
摘要:谷歌团队还研究使用该模型进行噪声输入,其中以不同混合比例将两个扬声器的单声道混合语音作为模型的输入。结论在本文中,谷歌团队引入了一种新的在线序列到序列模型的训练方式,并将其应用于具有噪音输入的环境。
近日谷歌团队发布了一篇关于在线语音识别的序列到序列模型论文,雷锋网了解到,该模型可以实现在线实时的语音识别功能,并且对来自不同扬声器的声音具有识别能力。
论文摘要
生成式模型一直是语音识别的主要方法。然而,这些模型的成功依赖于使用的精密的组合和复杂方法。最近,关于深入学习方面的研究已经产生了一种可以替代生成式模型的识别模型,称为“序列到序列模型”。这种模型的准确性几乎可以与较先进的生成模型相匹配。该模型在机器翻译,语音识别,图像标题生成等方面取得了相当大的经验成果。由于这些模型可以在同一个步骤中端对端地进行培训,因此该模型是非常易于训练的,但它们在实践中却具有限制,即只能用于离线识别。这是因为该模型要求在一段话开始时就输入序列的整体以供使用,然而这对实时语音识别等任务来说是没有任何意义的。

图. 1:本文使用的模型的总体架构
为了解决这个问题,谷歌团队最近引入了在线序列模型。这种在线序列模型具有将产生的输出作为输入的 特性,同时还可以保留序列到序列模型的因果性质。这些模型具有在任何时间t产生的输出将会影响随后计算结果的特征。其中,有一种模型将使用二进制随机变量来选择产生输出的时间步长。该团队将这个模型称为神经自回归传感器(NAT)。这个模型将使用策略梯度方法来训练随机变量。

图. 2:熵正则化对排放位置的影响。 每行显示为输入示例的发射预测,每个符号表示3个输入时间步长。 "x"表示模型选择在时间步长发出输出,而“ - ”则表示相反的情况。 顶线 - 没有熵惩罚,模型在输入的开始或结束时发出符号,并且无法获得有意义的梯度来学习模型。 中线 – 使用熵正规化,该模型及时避免了聚类排放预测,并学习有意义地扩散排放和学习模型。 底线 - 使用KL发散规则排放概率,同时也可以缓解聚类问题,尽管不如熵正则化那样有效。
通过使用估计目标序列相对于参数模型的对数概率的梯度来训练该模型。 虽然这个模型并不是完全可以微分的,因为它使用的是不可微分的二进制随机单元,但是可以通过使用策略梯度法来估计关于模型参数的梯度。更详细地说,通过使用监督学习来训练网络进行正确的输出预测,并使用加强学习以训练网络来决定何时发出各种输出。
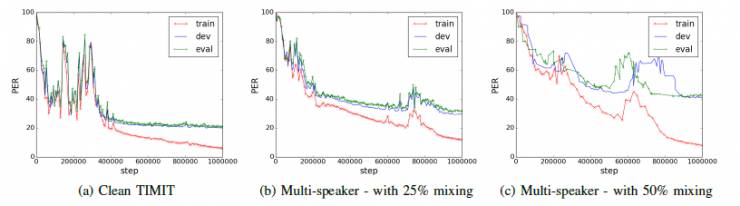
图. 3:在TIMIT上运行示例培训
图3b和3c分别示出了混合比例分别为0.25和0.5的两种情况的训练曲线的实例。 在这两种情况下,都可以看出,该模型学习了过适合数据。
谷歌团队还研究使用该模型进行噪声输入,其中以不同混合比例将两个扬声器的单声道混合语音作为模型的输入。
实验和结果
使用这个模型对两种不同的语音语料库进行了实验。 第一组实验是对TIMIT进行了初步实验,以评估可能导致模型稳定行为的超参数。 第二组实验是在不同混合比例下从两个不同的扬声器(一个男性和一个女性)混合的语音进行的。 这些实验被称为Multi-TIMIT。
A:TIMIT
TIMIT数据集是音素识别任务,其中必须从输入音频语音推断音素序列。有关训练曲线的示例,请参见图3。 可以看出,在学习有意义的模型之前,该模型需要更多的更新(> 100K)。 然而,一旦学习开始,即使模型受到策略梯度的训练,实现了稳定的过程。
表I显示了通过这种方法与其他更成熟的模型对TIMIT实现的结果。 可以看出,该模型与其他单向模型比较,如CTC,DNN-HMM等。如果结合更复杂的功能,如卷积模型应该可以产生更好的结果。 此外,该模型具有吸收语言模型的能力,因此,应该比基于CTC和DNNHMM的模型更适合端到端的培训,该模型不能固有地捕获语言模型。

表I:针对各种模型使用单向LSTM的TIMIT结果
B:Multi-TIMIT
通过从原始TIMIT数据混合男性声音和女性声音来生成新的数据集。 原始TIMIT数据对中的每个发音都有来自相反性别的声音。

表II:Multi-TIMIT的结果:该表显示了该模型在不同比例的混合中为干扰语音所实现的音素误差率(PER)。 还显示了深层LSTM 和RNN-自感器 的CTC的结果
表II显示了使用混合扬声器的不同混合比例的结果。 可以看出,随着混合比例的增加,模型的结果越来越糟糕。 对于实验而言,每个音频输入始终与相同的混音音频输入配对。 有趣的是,可以发现,将相同的音频与多个混淆的音频输入配对会产生更差的结果,这是由于产生了更为糟糕的过度配对。 这可能是因为该模型强大到足以复制整个转录的结果。
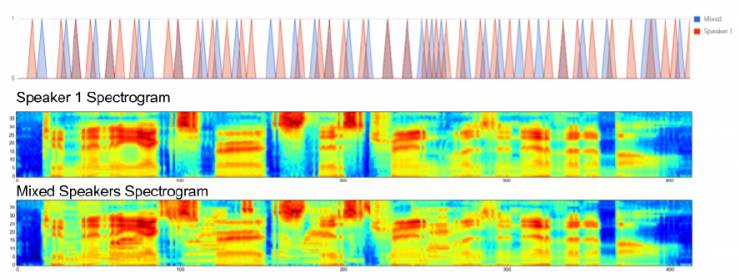
图. 5:Multi-TIMIT的声音分布:该图显示了在TIMIT中发出干净话语的情况下发出令牌的概率以及Multi-TIMIT中对应的噪声发音。 可以看出,对于Multi-TIMIT语句,该模型稍稍比TIMIT语句发出符号要晚一点。
图5显示为示例Multi-TIMIT话语的模型发出的符号。 并与一个干净模型的发出进行比较。 一般来说,与TIMIT发出的模型相比,该模型选择稍后再发布Multi-TIMIT。
结论
在本文中,谷歌团队引入了一种新的在线序列到序列模型的训练方式,并将其应用于具有噪音输入的环境。 作为因果模型的结果,这些模型可以结合语言模型,并且还可以为相同的音频输入生成多个不同的 转录结果。 这使它成为一类非常强大的模型。 即使在与TIMIT一样小的数据集上,该模型依然能够适应混合语音。 从实验分析的角度来说,每个扬声器只耦合到一个干扰扬声器,因此数据集的大小是有限的。 通过将每个扬声器与多个其他扬声器配对,并将每个扬声器预测为输出,应该能够实现更强的鲁棒性。 由于这种能力,该团队希望可以将这些模型应用到未来的多通道、多扬声器识别中。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4582.html
摘要:目前较好的语音识别系统采用双向长短时记忆网络,,这种网络能够对语音的长时相关性进行建模,从而提高识别正确率。因而科大讯飞使用深度全序列卷积神经网络来克服双向的缺陷。 人工智能的应用中,语音识别在今年来取得显著进步,不管是英文、中文或者其他语种,机器的语音识别准确率在不断上升。其中,语音听写技术的发展更为迅速,目前已广泛在语音输入、语音搜索、语音助手等产品中得到应用并日臻成熟。但是,语音应用的...
摘要:文本谷歌神经机器翻译去年,谷歌宣布上线的新模型,并详细介绍了所使用的网络架构循环神经网络。目前唇读的准确度已经超过了人类。在该技术的发展过程中,谷歌还给出了新的,它包含了大量的复杂案例。谷歌收集该数据集的目的是教神经网络画画。 1. 文本1.1 谷歌神经机器翻译去年,谷歌宣布上线 Google Translate 的新模型,并详细介绍了所使用的网络架构——循环神经网络(RNN)。关键结果:与...
摘要:自从年深秋,他开始在上撰写并公开分享他感兴趣的机器学习论文。本文选取了上篇阅读注释的机器学习论文笔记。希望知名专家注释的深度学习论文能使一些很复杂的概念更易于理解。主要讲述的是奥德赛因为激怒了海神波赛多而招致灾祸。 Hugo Larochelle博士是一名谢布克大学机器学习的教授,社交媒体研究科学家、知名的神经网络研究人员以及深度学习狂热爱好者。自从2015年深秋,他开始在arXiv上撰写并...
摘要:在与李世石比赛期间,谷歌天才工程师在汉城校区做了一次关于智能计算机系统的大规模深度学习的演讲。而这些任务完成后,谷歌已经开始进行下一项挑战了。谷歌深度神经网络小历史谷歌大脑计划于年启动,聚焦于真正推动神经网络科学能达到的较先进的技术。 在AlphaGo与李世石比赛期间,谷歌天才工程师Jeff Dean在Google Campus汉城校区做了一次关于智能计算机系统的大规模深度学习(Large-...

阅读 1812·2021-11-23 10:07
阅读 2857·2019-08-30 11:10
阅读 2998·2019-08-29 17:08
阅读 1918·2019-08-29 15:42
阅读 3323·2019-08-29 12:57
阅读 2532·2019-08-28 18:06
阅读 3712·2019-08-27 10:56
阅读 521·2019-08-26 11:33





