
摘要:然而,可用数据集的规模却没有成比例地扩大。这还说明无监督表征学习,以及半监督表征学习方法有良好的前景。例如,对于对象探测得分,单个模型目前可以实现,高于此前的。此外,构建包含图片的数据集并不是最终目标。
都说深度学习的兴起和大数据息息相关,那么是不是数据集越大,训练出的图像识别算法准确率就越高呢?
Google的研究人员用3亿张图的内部数据集做了实验,然后写了篇论文。他们指出,在深度模型中,视觉任务性能随训练数据量(取对数)的增加,线性上升。
以下是Google Research机器感知组指导教师,卡耐基梅隆大学助理教授Abhinav Gupta对这项工作的介绍,发布在Google Research官方博客上,量子位编译:
过去10年,计算机视觉技术取得了很大的成功,其中大部分可以归功于深度学习模型的应用。此外自2012年以来,这类系统的表现能力有了很大的进步,原因包括:
1)复杂度更高的深度模型;
2)计算性能的提升;
3)大规模标签数据的出现。
每年,我们都能看到计算性能和模型复杂度的提升,从2012年7层的AlexNet,发展到2015年101层的ResNet。
然而,可用数据集的规模却没有成比例地扩大。101层的ResNet在训练时仍然用着和AlexNet一样的数据集:ImageNet中的10万张图。
作为研究者,我们一直在关注这样的问题:如果能将训练数据集扩大10倍,较精确度是否会有成倍的提升?如果数据集扩大100倍或300倍又会怎样?较精确度会停滞不前,还是随着数据量的增长不断提升?
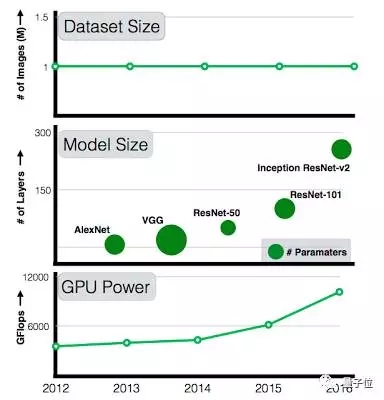
过去5年间,GPU计算力和模型复杂度都在持续增长,但训练数据集的规模没有任何变化
在论文Revisit the Unreasonable Effectiveness of Data中,我们迈出了第一步,探索“大量数据”与深度学习之间的关系。我们的目标是研究:
1)使用当前的算法,如果提供越来越多带噪声标签的图片,视觉表现是否仍然可以得到优化;
2)对于标准的视觉任务,例如分类、对象探测,以及图像分割,数据和性能之间的关系是什么;
3)利用大规模学习技术,开发能胜任计算机视觉领域各类任务的较先进的模型。
当然,问题的关键在于,我们要从何处找到比ImageNet大300倍的数据集。
Google一直努力构建这样的数据集,以优化计算机视觉算法。在Geoff Hinton、Francois Chollet等人的努力下,Google内部构建了一个包含3亿张图片的数据集,将其中的图片标记为18291个类,并将其命名为JFT-300M。
图片标记所用的算法混合了复杂的原始网络信号,以及网页和用户反馈之间的关联。
通过这种方法,这3亿张图片获得了超过10亿个标签(一张图片可以有多个标签)。在这10亿个标签中,约3.75亿个通过算法被选出,使所选择图片的标签较精确度较大化。然而,这些标签中依然存在噪声:被选出图片的标签约有20%是噪声。
我们的实验验证了一些假设,但也带来了意料之外的结果:
更好的表征学习(Representation Learning)能带来帮助。
我们观察到的较早的现象是,大规模数据有助于表征学习,从而优化我们所研究的所有视觉任务的性能。
我们的发现表明,建立用于预训练的大规模数据集很重要。这还说明无监督表征学习,以及半监督表征学习方法有良好的前景。看起来,数据规模继续压制了标签中存在的噪声。
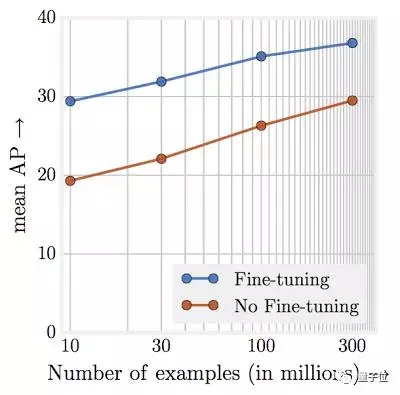
随着训练数据数量级的增加,任务性能呈线性上升。
或许最令人惊讶的发现在于,视觉任务性能和表现学习训练数据量(取对数)之间的关系。我们发现,这样的关系仍然是线性的。即使训练图片规模达到3亿张,我们也没有观察到性能上升出现停滞。如下图所示:
模型容量非常关键。
我们观察到,如果希望完整利用3亿张图的数据集,我们需要更大容量(更深)的模型。
例如,对于ResNet-50,COCO对象探测得分的上升很有限,只有1.87%,而使用ResNet-152,这一得分上升达到3%。
新的较高水准结果。
我们的论文用JFT-300M去训练模型,多项得分都达到了业界较高水准。例如,对于COCO对象探测得分,单个模型目前可以实现37.4 AP,高于此前的34.3 AP。
需要指出,我们使用的训练体系、学习进度以及参数基于此前用ImageNet 1M图片训练ConvNets获得的经验。
由于我们并未在这项工作中探索最优的超参数(这将需要可观的计算工作),因此很有可能,我们还没有得到利用这一数据集进行训练能取得的较佳结果。因此我们认为,量化的性能报告可能低估了这一数据集的实际影响。
这项工作并未关注针对特定任务的数据,例如研究更多边界框是否会影响模型的性能。我们认为,尽管存在挑战,但获得针对特定任务的大规模数据集应当是未来研究的一个关注点。
此外,构建包含300M图片的数据集并不是最终目标。我们应当探索,凭借更庞大的数据集(包含超过10亿图片),模型是否还能继续优化。
Google Research Blog原文:https://research.googleblog.com/2017/07/revisiting-unreasonable-effectiveness.html
相关论文:Revisiting the Unreasonable Effectiveness of Data
https://arxiv.org/abs/1707.02968
你可能还关心那个3亿张图的数据集。它目前还是Google内部用品,这两篇论文提到过它:
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, Jeff Dean
https://arxiv.org/abs/1503.02531
Xception: Deep Learning with Depthwise Separable Convolutions
Franc¸ois Chollet
https://arxiv.org/abs/1610.02357
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4576.html
摘要:的这项研究,总共生成了篇深度学习论文的和代码,还创建了一个网站,供同行们众包编辑这些代码。来自印度研究院。目前是印度研究院的实习生。 深度学习的论文越来越多了~多到什么程度?Google scholar的数据显示,2016年以来,人工智能领域新增的论文已经超过3.5万篇。arXiv上,AI相关的论文每天都不下百篇。刚刚结束不久的计算机视觉会议ICCV上,发表了621篇论文;2018年的ICL...
摘要:在年初之际,国内专业的云资源选型服务平台旗下监测实验室,针对业界家主流的云服务提供商,包括阿里云腾讯云与华为云进行了横向评测。华为云和阿里云紧随其后,位列第二第三位。阿里云和腾讯云相对优势不明显。 在2020年初之际,国内专业的云资源选型服务平台CloudBest旗下监测实验室,针对业界4家主流的云服务提供商,包括阿里云、腾讯云、UCloud与华为云进行了横向评测。本次测试在尽量保证测试环...
摘要:年实验室团队采用了深度学习获胜,失败率仅。许多其他参赛选手也纷纷采用这一技术年,所有选手都使用了深度学习。和他的同事运用深度学习系统赢得了美元。深度学习,似乎是解决 三年前,在山景城(加利福尼亚州)秘密的谷歌X实验室里,研究者从YouTube视频中选取了大约一千万张静态图片,并且导入到Google Brain —— 一个由1000台电脑组成的像幼儿大脑一样的神经网络。花费了三天时间寻找模式之...
摘要:判别器胜利的条件则是很好地将真实图像自编码,以及很差地辨识生成的图像。 先看一张图:下图左右两端的两栏是真实的图像,其余的是计算机生成的。过渡自然,效果惊人。这是谷歌本周在 arXiv 发表的论文《BEGAN:边界均衡生成对抗网络》得到的结果。这项工作针对 GAN 训练难、控制生成样本多样性难、平衡鉴别器和生成器收敛难等问题,提出了改善。尤其值得注意的,是作者使用了很简单的结构,经过常规训练...
摘要:接下来,介绍了使用深度学习的计算机视觉系统在农业零售业服装量身定制广告制造等产业中的应用和趋势,以及在这些产业中值得关注的企业。 嵌入式视觉联盟主编Brian Dipert今天发布博文,介绍了2016年嵌入式视觉峰会(Embedded Vision Summit)中有关深度学习的内容:谷歌工程师Pete Warden介绍如何利用TensorFlow框架,开发为Google Translate...

阅读 4219·2021-09-22 15:34
阅读 2832·2021-09-22 15:29
阅读 546·2019-08-29 13:52
阅读 3395·2019-08-29 11:30
阅读 2323·2019-08-26 10:40
阅读 896·2019-08-26 10:19
阅读 2301·2019-08-23 18:16
阅读 2379·2019-08-23 17:50






