
摘要:本文将告诉你如何用最省钱的方式,来搭建一个高性能深度学习系统。
由于深度学习的计算相当密集,所以有人觉得“必须要购买一个多核快速CPU”, 也有人认为“购买快速CPU可能是种浪费”。
那么,这两种观点哪个是对的? 其实,在建立深度学习系统时,最糟糕的事情之一就是把钱浪费在不必要的硬件上。 本文将告诉你如何用最省钱的方式,来搭建一个高性能深度学习系统。
当初,在我研究并行深度学习过程中,我构建了一个GPU集群 ,所以我需要仔细选择硬件。 尽管经过了反复的研究和推理,但当我挑选硬件时,我仍然会犯许多错误,并且当应用于实践中时,那些错误就展现出来了。 所以,在这里,我想分享一下我所学到的知识,希望你不会像我一样再陷入同样的陷阱。
GPU
本文假设您将使用GPU进行深度学习。 如果您正在建立或升级您的系统,那么忽视GPU是不明智的。 GPU才是深度学习应用的核心,它能大大提升处理速度,所以不能忽略。
我在之前的文章中详细介绍了GPU的选择,并且GPU的选择可能是您的深度学习系统中最关键的选择。
一般来说,如果您的资金预算有限,我推荐您购买GTX 680,或者GTX Titan X(如果你很有钱,可用它做卷积)或GTX 980(它性价比很高,但若做大型卷积神经网络就有些局限性了),它们在eBay上就能买得到。
另外,低成本高性价比的内存我推荐GTX Titan。 之前我支持过GTX 580,但是由于新更新的cuDNN库显着提升了卷积速度,故而所有不支持cuDNN的GPU都已经过时了,其中 GTX 580就是这样一款GPU。 如果您不使用卷积神经网络,GTX 580仍然是一个很好的选择。

你能识别上面哪个硬件会导致糟糕的表现? 是这些GPU的其中一个? 还是CPU?
CPU
要选择CPU,我们首先要了解CPU及它与深度学习的关系。
CPU对深度学习有什么作用? 当您在GPU上运行深度网络时,CPU几乎没有计算,
但是CPU仍然可以处理以下事情:
在代码中写入和读取变量
执行诸如函数调用的指令
在GPU上启动函数调用
创建小批量数据
启动到GPU的数据传输
所需CPU的数量
当我用三个不同的库训练深度神经网络时,我总是看到一个CPU线程是100%(有时另一个线程会在0到100%之间波动)。 而且这一切立即告诉你,大多数深入学习的库,以及实际上大多数的软件应用程序,一般仅使用一个线程。
这意味着多核CPU相当无用。 如果您运行多个GPU,并使用MPI之类的并行化框架,那么您将一次运行多个程序,同时,也需要多个线程。
每个GPU应该是一个线程,但每个GPU运行两个线程将会为大多数深入学习库带来更好的性能;这些库在单核上运行,但是有时会异步调用函数,就使用了第二个CPU线程。
请记住,许多CPU可以在每个内核上运行多个线程(这对于Intel 的CPU尤为如此),因此通常每个GPU对应一个CPU核就足够了。
CPU和PCI-Express
这是一个陷阱! 一些新的Haswell CPU不支持那些旧CPU所支持的全部40个PCIe通道。如果要使用多个GPU构建系统,请避免使用这些CPU。 另外,如果您有一个带有3.0的主板,则还要确保您的处理器支持PCIe 3.0。
CPU缓存大小
正如我们将在后面看到的那样,CPU高速缓存大小在“CPU-GPU-管线”方面是相当无关紧要的,但是我还是要做一个简短的分析,以便我们确保沿着这条计算机管道能考虑到每一个可能出现的瓶颈,进而我们可以全面了解整体流程。
通常人们购买CPU时会忽略缓存,但通常它是整体性能问题中非常重要的一部分。 CPU缓存的片上容量非常小,且位置非常靠近CPU,可用于高速计算和操作。 CPU通常具有缓存的分级,从小型高速缓存(L1,L2)到低速大型缓存(L3,L4)。
作为程序员,您可以将其视为哈希表,其中每个数据都是键值对(key-value-pair),您可以在特定键上进行快速查找:如果找到该键,则可以对高速缓存中的值执行快速读写操作; 如果没有找到(这被称为缓存未命中),则CPU将需要等待RAM赶上,然后从那里读取该值(这是非常缓慢的过程)。 重复的缓存未命中会导致性能显着降低。 高效的CPU高速缓存方案和架构,通常对CPU的性能至关重要。
CPU如何确定其缓存方案,是一个非常复杂的主题,但通常可以假定重复使用的变量、指令和RAM地址将保留在缓存中,而其他不太频繁出现的则不会。
在深度学习中,相同的内存范围会重复被小批量读取,直到送到GPU,并且该内存范围会被新数据覆盖。但是如果内存数据可以存储在缓存中,则取决于小批量大小。
对于128位的小批量大小,我们对应于MNIST和CIFAR分别有0.4MB和1.5 MB,这适合大多数CPU缓存;对于ImageNet,我们每个小批量有超过85 MB的数据( ),即使是较大的缓存(L3缓存不超过几MB),也算是很大的了。
由于数据集通常太大而无法适应缓存,所以新的数据需要从RAM中每个读取一小部分新的,并且需要能够以任何方式持续访问RAM。
RAM内存地址保留在缓存中(CPU可以在缓存中执行快速查找,并指向RAM中数据的确切位置),但是这仅限于整个数据集都存储于RAM时才会如此,否则内存地址将改变,并且缓存也不会加速(稍后你会看到的,使用固定内存时则不会出现这种情况,但这并不重要)。
深度学习代码的其他部分(如变量和函数调用),将从缓存中受益,但这些代码通常数量较少,可轻松适应几乎任何CPU的小型快速L1缓存。
从这个推理结果可以看出,CPU缓存大小不应该很重要。下一节进一步分析的结果,也与此结论相一致。
所需的CPU时钟频率(frequency)
当人们想到快速的CPU时,他们通常首先想到时钟频率(clockrate)。 4GHz真的比3.5GHz快吗?这对于具有相同架构的处理器来说,通常是正确的,例如“Ivy Bridge”。但在不同架构的处理器之间,就不能这样比较了。 此外,时钟频率也并非总是较佳的性能指标。
在深度学习上,使用CPU的计算很少:比如增加一些变量、评估一些布尔表达式、在GPU或程序中调用一些函数。以上这些都取决于CPU内核时钟率。虽然这个推理似乎是合理的,但是当我运行深度学习程序时,CPU却有100%的使用率,这是为什么? 为了找到原因,我做了一些CPU核频率的降频实验。

在MNIST和ImageNet上的CPU降频测试 :以上数据,是在具有不同CPU内核时钟频率时,对ImageNet运行200个周期MNIST数据集,或1/4 ImageNet周期所用时间,进行性能测量的。其中以较大时钟频率作为每个CPU的基准线。 为了比较:从GTX 680升级到GTX Titan,性能约为15%; 从GTX Titan到GTX 980提升20%; GPU超频为所有GPU提升约5%的性能。
那么为什么CPU内核频率对系统来说无关紧要,而使用率却是100%? 答案可能是CPU缓存未命中(CPU持续忙于访问RAM,但是同时CPU必须等待RAM以跟上其较慢的时钟频率,这可能会导致忙碌和等待两者同时存在的矛盾状态)。 如果这是真的,就像上面看到的结果一样,那么CPU内核的降频不会导致性能急剧下降。
另外,CPU还执行其他操作,如将数据复制到小批量中,并将准备复制到GPU的数据准备好,但这些操作取决于内存时钟频率,而不是CPU内核时钟频率。 所以,现在我们来看看内存方面。
RAM时钟频率
CPU-RAM,以及与RAM的其他交互,都相当复杂。 我将在这里展示一个简化版本的过程。为了能更全面地理解,就我们先来深入了解从CPU RAM到GPU RAM这一过程。
CPU内存时钟和RAM交织在一起。 您的CPU的内存时钟决定了RAM的较大时钟频率,这两个部分构成CPU的总体内存带宽,但通常RAM本身确定了总体可用带宽,原因是它比CPU内存频率慢。
您可以这样确定带宽:
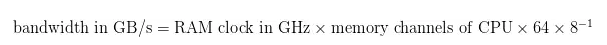
(其中64是指64位CPU架构。 对于我的处理器和RAM模块,带宽为51.2GB / s)
但是,如果您复制大量的数据,这时会和带宽相关。 通常,您的RAM上的时序(例如8-8-8)对于小数据量来说更为相关,并且决定您的CPU等待RAM追赶的时间。 但是如上所述,您深入学习程序中的几乎所有数据都将轻松适应CPU缓存,除非因为太大,才无法从缓存中获益。 这意味着计时器将是不重要的,而带宽可能才是重要的。
那么这与深度学习程序有什么关系呢? 我刚刚只是说带宽可能很重要,但是在下一步里,它就不是很重要了。 您的RAM的内存带宽决定了一个小批量可以被重写和分配用于初始化GPU传输的速度,但下一步,CPU-RAM到GPU-RAM是真正的瓶颈,这一步使用直接内存存取(DMA)。 如上所述,我的RAM模块的内存带宽为51.2GB/ s,但DMA带宽只有12GB / s!
DMA带宽与常规带宽有关,但细节并不一定必须了解。如果您想详细了解,可到该维基百科词条查看,您可以在词条内查找RAM模块的DMA带宽(峰值传输限制)。 但是先让我们看看DMA是如何工作的吧。
(地址:https://en.wikipedia.org/wiki/DDR3_SDRAM#JEDEC_standard_modules)
直接内存存取(DMA)
具有RAM的CPU只能通过DMA与GPU进行通信。
在第一步中,CPU RAM和GPU RAM都保留特定的DMA传输缓冲区;
在第二步,CPU将请求的数据写入CPU侧的DMA缓冲区;
在第三步中,保留的缓冲区无需CPU的帮助即可传输到GPURAM。
这里有人可能会想:你的PCIe带宽是8GB / s(PCIe 2.0)或15.75GB / s(PCIe 3.0),所以你应该买一个像上面所说的良好峰值传输限制的RAM吗?
答案是:不必要。 软件在这里会扮演重要角色。 如果你以一种聪明的方式进行一些传输,那么你就不再需要那些便宜且慢的内存。
异步迷你批量分配(Asynchronousmini-batch allocation)
一旦您的GPU完成了当前迷你批量的计算,它就想立即计算下一迷你批次(mini-batch)。 您现在可以初始化DMA传输,然后等待传输完成,以便您的GPU可以继续处理数字。
但是有一个更有效的方法:提前准备下一个迷你批量,以便让您的GPU不必等待。 这可以轻松且异步地完成,而不会降低GPU性能。

用于异步迷你批次分配的CUDA代码:当GPU开始处理当前批次时,执行前两次调用; 当GPU完成当前批处理时,执行最后两个调用。 数据传输在数据流的第二步同步之前就已经完成,因此GPU处理下一批次将不会有任何延迟。
Alex Krishevsky的卷积网络的ImageNet 2012迷你批次的大小为128,仅需要0.35秒就能完成它的完整的反向传递。 我们能够在如此短时间内分配下一批吗?
如果我们采用大小为128的批次,并且维度244x244x3大小的数据,总量大约为0.085 GB( )。 若使用超慢内存,我们有6.4 GB / s,即每秒75个迷你批次! 所以使用异步迷你批量分配,即使是最慢的RAM对深入学习也将足够。如果使用异步迷你批量分配,购买更快的RAM模块没有任何优势。
该过程也间接地意味着CPU缓存是无关紧要的。 您的CPU的快速覆盖速度(在快速缓存中),以及准备(将缓存写到RAM)一个迷你批次其实并不重要,因为在GPU请求下一个迷你批次之前,整个传输就已经完成了,所以一个大型缓存真的没那么重要。
所以底线确实是RAM的时钟频率是无关紧要的,所以买便宜的就行了。
但你需要买多少个呢?
RAM大小
您应该至少具有与GPU内存大小相同的RAM。 当然,您可以使用较少的RAM,但这样的话可能需要一步一步地传输数据。 然而,从我的经验来看,使用更大的RAM会更加方便。
心理学告诉我们,专注力是随着时间的推移会慢慢耗尽的一种资源。有些为数不多的硬件,可以帮您节省注意力资源以解决更困难的编程问题, RAM就是其中之一。 如果您有更多的RAM,您可以将更多的时间投入到更紧迫的事情上,而不是花费大量的时间来弥补RAM瓶颈。
有了很多RAM,您可以避免这些瓶颈,节省时间并提高生产率,使注意力投入到更紧迫的地方。 特别是在Kaggle比赛中,我发现额外的RAM对于特征操作非常有用。 所以如果你资金充裕,并做了大量的预处理,那么额外的RAM可能是一个不错的选择。
硬盘驱动器/SSD
在某些情况下,硬盘驱动器可能是深度学习的重大瓶颈。 如果您的数据集很大,您通常会在SSD /硬盘驱动器上放一些数据,RAM中也有一些,以及GPURAM中也会放两个迷你批量(mini-batch)。 为了不断地供给GPU,我们需要以GPU可以运行完的速度提供新的的迷你批量(mini-batch)。
为此,我们需要使用与异步迷你批量分配相同的想法。 我们需要异步读取多个小批量的文件,这真的很重要! 如果我们不这样做,结果表现会被削弱很多(约5-10%),并且你精心设计的硬件优势将毫无作用(好的深入学习软件在GTX 680也能运行很快,而坏的深入学习软件即使用GTX 980也会步履维艰)
考虑到这一点,如果我们将数据保存为32位浮点数据,就会遇到Alex的ImageNet卷积网络遇到的数据传输速率的问题,约每0.3秒0.085GB( )即290MB / s。 如果我们把它保存为jpeg数据,我们可以将它压缩5-15倍,将所需的读取带宽降低到约30MB / s。 如果我们看硬盘驱动器的速度,我们通常会看到速度为100-150MB / s,所以这对于压缩为jpeg的数据是足够的。
类似地,一个人可以使用mp3或其他压缩技术处理的声音文件,但是对于处理原始32位浮点数据的其他数据组,难以很好地压缩数据(只能压缩32位浮点数据10-15%)。 所以如果你有大的32位数据组,那么你肯定需要一个SSD,因为速度为100-150 MB / s的硬盘会很慢,难以跟上GPU。
所以如果你今后有可能遇到这样的数据,那就买一个一个SSD;如果不会遇到那样的数据,一个硬盘驱动器就足够用了。
许多人购买SSD是为了感觉上更好:程序启动和响应更快,并且使用大文件进行预处理也更快一些。但是对于深入学习,仅当输入维度很高且无法充分压缩数据时,才用得到SSD。
如果您购买SSD,您应该买一个能够容纳您常用大小的数据组的SSD,另外还需要额外留出几十GB的空间。其实,让硬盘驱动器来存储未使用的数据组也是个好主意。
电源单元(PSU)
一般来说,您需要一个足够的PSU来满足未来的所有GPU。 GPU通常会随着时间的推移而更加节能,所以即使当其他组件到了更换的时候,PSU也能继续工作很长时间,所以良好的PSU是一个明智的投资。
您可以通过将CPU和GPU的所需瓦数,与其他组件所需瓦数相加,再加上作为电源峰值缓冲的100-300瓦,就能计算出所需的瓦数。
要注意的一个重要部分,是留意您的PSU的PCIe连接器是否支持带有连接线的8pin + 6pin的接头。 我买了一个具有6x PCIe端口的PSU,但是只能为8pin或6pin连接器供电,所以我无法使用该PSU运行4个GPU。
另一个重要的事情是购买具有高功率效率等级的PSU,特别是当您运行多个GPU并想要运行很长时间。
在全功率(1000-1500瓦特)下运行4个GPU系统,对卷积网进行两个星期的训练,将消耗300-500千瓦时,而在德国的电力成本还要高出20美分/ kWh,即60~100
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4571.html
摘要:在此之前,我们要为此做一些准备工作搭建本地测试节点,方便以后编写和部署合约。摘要这篇,我们将简单学习如何搭建本地测试节点大家就不要花钱去买了,以及如何使用超级账户创建新账户以及加载基础的系统合约。可以说,拥有了这个账户,就拥有了整个测试网络 之前三篇我们掌握了如何使用EOS源码搭建环境、连接主网以及如何创建账户。自此,我们对EOS就有了一个感性的认知,对EOS中公钥、账户以及权限有了新...
摘要:接下来,介绍了使用深度学习的计算机视觉系统在农业零售业服装量身定制广告制造等产业中的应用和趋势,以及在这些产业中值得关注的企业。 嵌入式视觉联盟主编Brian Dipert今天发布博文,介绍了2016年嵌入式视觉峰会(Embedded Vision Summit)中有关深度学习的内容:谷歌工程师Pete Warden介绍如何利用TensorFlow框架,开发为Google Translate...
摘要:然而目前的问题是,光互连硬件的成本随着其功能的增加而增加,并且其增长快于其他数据中心硬件的成本。如今,维护和升级数据中心硬件是一项优化工作。对于管理数据中心硬件的工作人员来说,这一点很重要数据需求将会持续增长。对于许多企业的数据中心团队来说,所面临困难的现实是需要支持更多的商业级应用:提高业务敏捷性,实现基础设施的现代化以提高能源效率,加强网络安全等等。与此同时,即使面临明确长期节省成本和业...
摘要:基准测试我们比较了和三款,使用的深度学习库是和,深度学习网络是和。深度学习库基准测试同样,所有基准测试都使用位系统,每个结果是次迭代计算的平均时间。 购买用于运行深度学习算法的硬件时,我们常常找不到任何有用的基准,的选择是买一个GPU然后用它来测试。现在市面上性能较好的GPU几乎都来自英伟达,但其中也有很多选择:是买一个新出的TITAN X Pascal还是便宜些的TITAN X Maxwe...
摘要:很明显这台机器受到了英伟达的部分启发至少机箱是这样,但价格差不多只有的一半。这篇个文章将帮助你安装英伟达驱动,以及我青睐的一些深度学习工具与库。 本文作者 Roelof Pieters 是瑞典皇家理工学院 Institute of Technology & Consultant for Graph-Technologies 研究深度学习的一位在读博士,他同时也运营着自己的面向客户的深度学习产...

阅读 1503·2019-08-30 12:54
阅读 1954·2019-08-30 11:16
阅读 1691·2019-08-30 10:50
阅读 2583·2019-08-29 16:17
阅读 1372·2019-08-26 12:17
阅读 1453·2019-08-26 10:15
阅读 2476·2019-08-23 18:38
阅读 861·2019-08-23 17:50






