
摘要:前言标题不能再中二了本文仅对一些常见的优化方法进行直观介绍和简单的比较,各种优化方法的详细内容及公式只好去认真啃论文了,在此我就不赘述了。就是每一次迭代计算的梯度,然后对参数进行更新,是最常见的优化方法了。
前言
(标题不能再中二了)本文仅对一些常见的优化方法进行直观介绍和简单的比较,各种优化方法的详细内容及公式只好去认真啃论文了,在此我就不赘述了。
SGD
此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mini-batch gradient descent的具体区别就不细说了。现在的SGD一般都指mini-batch gradient descent。
SGD就是每一次迭代计算mini-batch的梯度,然后对参数进行更新,是最常见的优化方法了。即:

缺点:(正因为有这些缺点才让这么多大神发展出了后续的各种算法)
选择合适的learning rate比较困难 - 对所有的参数更新使用同样的learning rate。对于稀疏数据或者特征,有时我们可能想更新快一些对于不经常出现的特征,对于常出现的特征更新慢一些,这时候SGD就不太能满足要求了
SGD容易收敛到局部最优,并且在某些情况下可能被困在鞍点【原来写的是“容易困于鞍点”,经查阅论文发现,其实在合适的初始化和step size的情况下,鞍点的影响并没这么大。感谢@冰橙的指正】
Momentum
momentum是模拟物理里动量的概念,积累之前的动量来替代真正的梯度。公式如下:

Nesterov
nesterov项在梯度更新时做一个校正,避免前进太快,同时提高灵敏度。 将上一节中的公式展开可得:

所以,加上nesterov项后,梯度在大的跳跃后,进行计算对当前梯度进行校正。如下图:
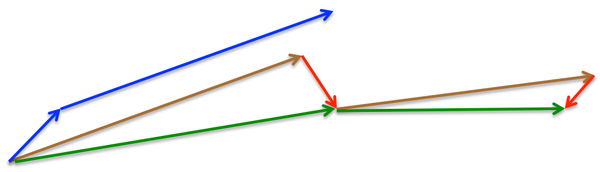
momentum首先计算一个梯度(短的蓝色向量),然后在加速更新梯度的方向进行一个大的跳跃(长的蓝色向量),nesterov项首先在之前加速的梯度方向进行一个大的跳跃(棕色向量),计算梯度然后进行校正(绿色梯向量)
其实,momentum项和nesterov项都是为了使梯度更新更加灵活,对不同情况有针对性。但是,人工设置一些学习率总还是有些生硬,接下来介绍几种自适应学习率的方法
Adagrad
Adagrad其实是对学习率进行了一个约束。即:


在此处Adadelta其实还是依赖于全局学习率的,但是作者做了一定处理,经过近似牛顿迭代法之后:

此时,可以看出Adadelta已经不用依赖于全局学习率了。
特点:
训练初中期,加速效果不错,很快
训练后期,反复在局部最小值附近抖动
RMSprop
RMSprop可以算作Adadelta的一个特例:

特点:
其实RMSprop依然依赖于全局学习率
RMSprop算是Adagrad的一种发展,和Adadelta的变体,效果趋于二者之间
适合处理非平稳目标 - 对于RNN效果很好
Adam
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。公式如下:

特点:
结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
对内存需求较小
为不同的参数计算不同的自适应学习率
也适用于大多非凸优化 - 适用于大数据集和高维空间
Adamax
Adamax是Adam的一种变体,此方法对学习率的上限提供了一个更简单的范围。公式上的变化如下:
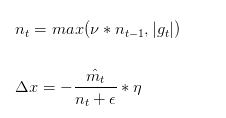
可以看出,Adamax学习率的边界范围更简单
Nadam
Nadam类似于带有Nesterov动量项的Adam。公式如下:
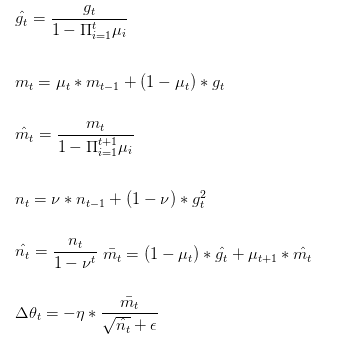
可以看出,Nadam对学习率有了更强的约束,同时对梯度的更新也有更直接的影响。一般而言,在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果。
经验之谈
对于稀疏数据,尽量使用学习率可自适应的优化方法,不用手动调节,而且较好采用默认值
SGD通常训练时间更长,但是在好的初始化和学习率调度方案的情况下,结果更可靠
如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法。
Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多。
在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果
最后展示两张可厉害的图,一切尽在图中啊,上面的都没啥用了... ...
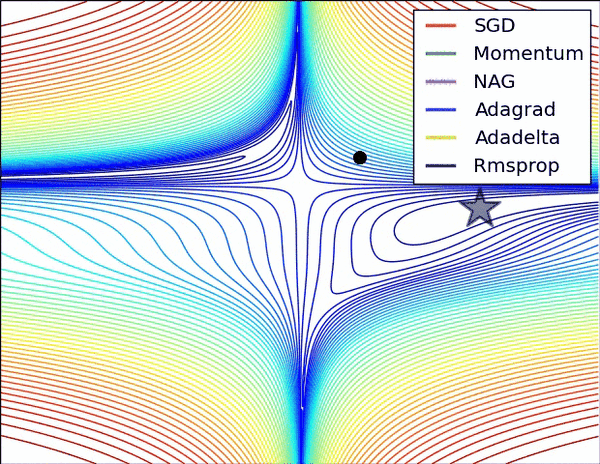
损失平面等高线

在鞍点处的比较
转载须全文转载且注明作者和原文链接,否则保留维权权利
引用
[1]Adagrad
[2]RMSprop[Lecture 6e]
[3]Adadelta
[4]Adam
[5]Nadam
[6]On the importance of initialization and momentum in deep learning
[7]Keras中文文档
[8]Alec Radford(图)
[9]An overview of gradient descent optimization algorithms
[10]Gradient Descent Only Converges to Minimizers
[11]Deep Learning:Nature
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4569.html
摘要:大家好,我是冰河有句话叫做投资啥都不如投资自己的回报率高。马上就十一国庆假期了,给小伙伴们分享下,从小白程序员到大厂高级技术专家我看过哪些技术类书籍。 大家好,我是...
摘要:将每一行作为返回,其中是每行中的列名。对于每一行,都会生成一个对象,其中包含和列中的值。它返回一个迭代器,是迭代结果都为的情况。深度解析至此全剧终。 简单实战 大家好,我又来了,在经过之前两篇文章的介绍后相信大家对itertools的一些常见的好用的方法有了一个大致的了解,我自己在学完之后仿照别人的例子进行了真实场景下的模拟练习,今天和大家一起分享,有很多部分还可以优化,希望有更好主意...
摘要:值得一提的是每篇文章都是我用心整理的,编者一贯坚持使用通俗形象的语言给我的读者朋友们讲解机器学习深度学习的各个知识点。今天,红色石头特此将以前所有的原创文章整理出来,组成一个比较合理完整的机器学习深度学习的学习路线图,希望能够帮助到大家。 一年多来,公众号【AI有道】已经发布了 140+ 的原创文章了。内容涉及林轩田机器学习课程笔记、吴恩达 deeplearning.ai 课程笔记、机...

阅读 1587·2023-04-26 00:20
阅读 1197·2023-04-25 21:49
阅读 860·2021-09-22 15:52
阅读 630·2021-09-07 10:16
阅读 1023·2021-08-18 10:22
阅读 2712·2019-08-30 14:07
阅读 2280·2019-08-30 14:00
阅读 2711·2019-08-30 13:00




