
摘要:我们提出了,它是一个分布式在上可实现高效通信的架构。利用深度程序中的层级模型结构而叠加通信与计算,这样以减少突发性网络通信。此外,使用混合的通信方案,并根据层级属性和机器数量优化每一层同步所要求的字节数。表神经网络的评估。
论文:Poseidon: An Efficient Communication Architecture for Distributed Deep Learning on GPU Clusters
论文链接:https://arxiv.org/abs/1706.03292

深度学习模型在单 GPU 机器上可能需要花费数周的时间进行训练,因此将深度学习分布到 GPU 集群进行训练就显得十分重要了。然而相对于 CPU,拥有更大的吞吐量的 GPU 允许单位时间内处理更多的数据批量(batches),因此目前的分布式 DL 因为大量参数频繁地在网络中进行同步而表现不佳。
我们提出了 Poseidon,它是一个分布式 DL 在 GPU 上可实现高效通信的架构。Poseidon 利用深度程序中的层级模型结构而叠加通信与计算,这样以减少突发性网络通信。此外,Poseidon 使用混合的通信方案,并根据层级属性和机器数量优化每一层同步所要求的字节数。我们表明 Poseidon 能使 Caffe 和 TensorFlow 在 16 个单 GPU 机器上实现 15.5 倍的加速,而且该实验还是在有带宽限制(10GbE)并挑战 VGG19-22K 图像分类网络下完成的。此外,Poseidon 能使 TensorFlow 在 32 个单 GPU 机器上运行 Inception-V3 达到 31.5 倍的加速,相比于开源的 TensorFlow 实现 50% 的性能提升(20 倍加速)。
图1. 六层卷积神经网络
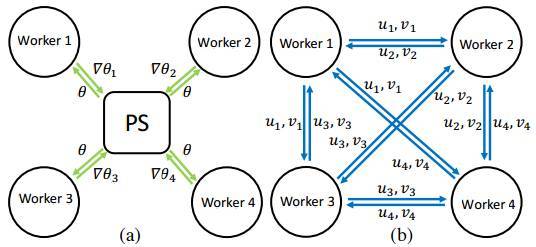
图 2:(a)参数服务器和(b)分布式 ML 的充分因子 broadcasting。
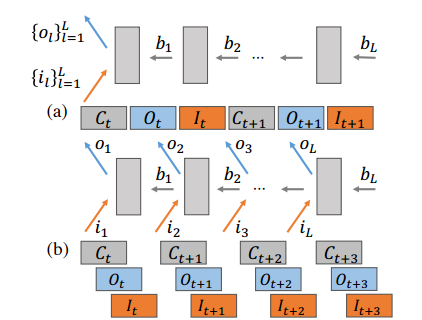
图 3:分布式环境中的(a)传统反向传播和(b)无等待(wait-free)反向传播。
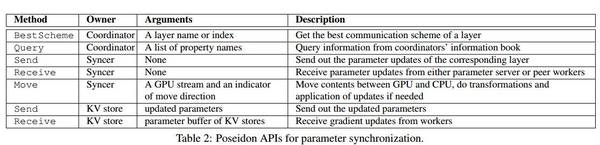
表 2:用于参数同步的 Poseidon API。
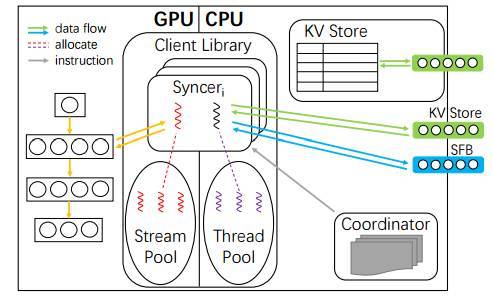
图 4:Poseidon 架构的概览。

表 3:神经网络的评估。其中展示了单结点批量大小,这些批量大小是基于文献中的标准报告而选择的(通常较大的批量大小正好是 GPU 的内存大小)。

图 5:使用 Poseidon 平行化的 Caffe 和 40GbE 带宽训练的 GoogLeNet、VGG19 和 VGG19-22K,及它们训练时的吞吐量变化。单节点 Caffe 设置为基线(即加速=1)。
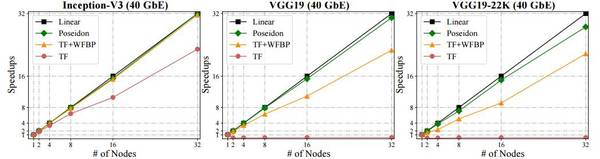
图 6:使用 Poseidon 平行化的 Caffe 和 40GbE 带宽训练的 Inception-V3、VGG19 和 VGG19-22K,及它们训练时的吞吐量变化。单节点 TensorFlow 设置为基线(即加速=1)。
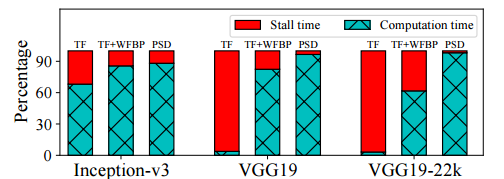
图 7:在 8 个节点上使用不同系统训练三种网络的 GPU 计算分解和延迟时间。
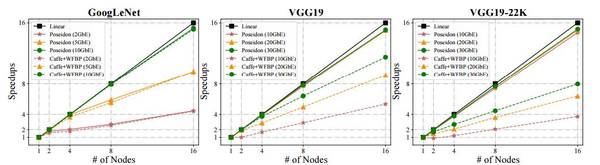
图 8:使用 Poseidon 平行化的 Caffe 和不同网络带宽训练的 GoogLeNet、VGG19 和 VGG19-22K,及它们训练时的吞吐量变化。单节点 Caffe 设置为基线(即加速=1)。
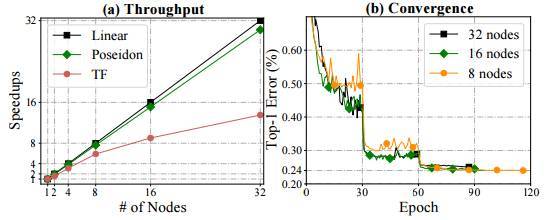
图 9:(a)加速 vs. 节点数量和(b)使用 Poseidon TensorFlow 与原始 TensorFlow 训练 ResNet-152 的较佳测试误差 vs. epochs。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4566.html
摘要:在一个数据分析任务和任务混合的环境中,大数据分析任务也会消耗很多网络带宽如操作,网络延迟会更加严重。本地更新更新更新目前,我们已经复现中的实验结果,实现了多机并行的线性加速。 王佐,天数润科深度学习平台负责人,曾担任 Intel亚太研发中心Team Leader,万达人工智能研究院资深研究员,长期从事分布式计算系统研究,在大规模分布式机器学习系统架构、机器学习算法设计和应用方面有深厚积累。在...

阅读 3728·2021-11-23 09:51
阅读 1739·2021-10-22 09:53
阅读 1400·2021-10-09 09:56
阅读 922·2019-08-30 13:47
阅读 2213·2019-08-30 12:55
阅读 1644·2019-08-30 12:46
阅读 1172·2019-08-30 10:51
阅读 2463·2019-08-29 12:43


