
摘要:团队昨天发布的一个模型学会一切论文背后,有一个用来训练模型的模块化多任务训练库。模块化的多任务训练库利用工具来开发,定义了一个深度学习系统中需要的多个部分数据集模型架构优化工具学习速率衰减计划,以及超参数等等。
Google Brain团队昨天发布的“一个模型学会一切”论文背后,有一个用来训练MultiModel模型的模块化多任务训练库:Tensor2Tensor。
今天,Google Brain高级研究员Łukasz Kaiser就在官方博客上发文,详细介绍了新开源的T2T库。
以下内容编译自Google Research的官方博客:
深度学习推动了许多技术的快速发展,例如机器翻译、语音识别和对象检测。在科研领域,人们可以查找作者开源的代码,从而复现他们的研究成果,推动深度学习技术的进一步发展。
然而,这些深度学习系统大部分都采用了独特配置,需要大量的工程开发,并且可能只适用于特定的问题或架构,导致很难尝试新的实验并比较结果。
今天,我们很高兴发布Tensor2Tensor (T2T),一个用于在TensorFlow中训练深度学习模型的开源系统。
T2T有助于开发顶尖水平的模型,并适用各类机器学习应用,例如翻译、分析和图像标注等。这意味着,对各种不同想法的探索要比以往快得多。
此次发布的这个版本还提供了由数据集和模型构成的库文件,包括近期几篇论文中最优秀的模型(文末列举了这几篇论文),从而推动你自己的深度学习研究。
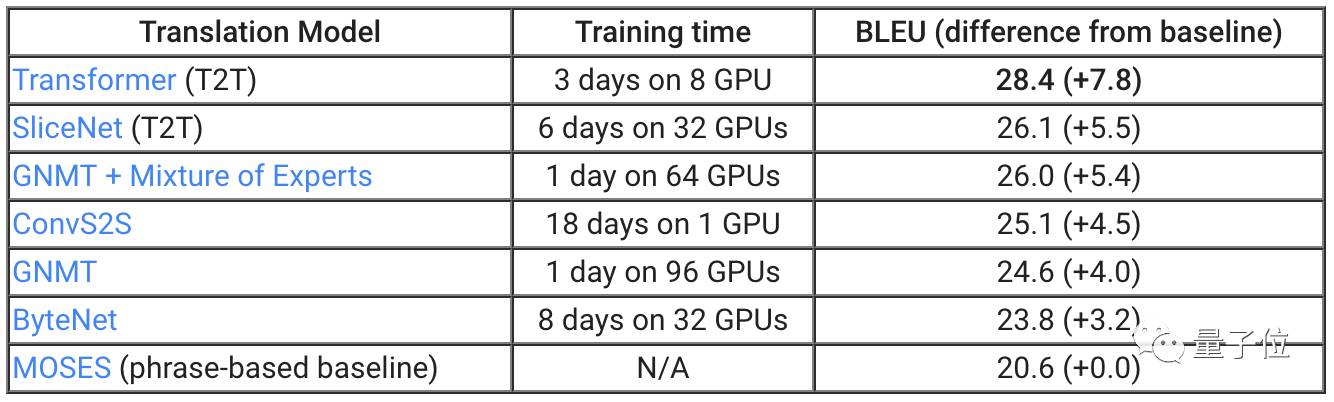
为了证明T2T可以带来的改进,我们将库文件应用于机器翻译。正如上表所显示的,两个不同的T2T模型,SliceNet和Transformer,超过了此前表现较好的系统GNMT+MoE。
我们最优秀的T2T模型Transformer,比标准GNMT模型高出3.8分,而GNMT自身要比作为基准的翻译系统MOSES高出4分。
值得注意的是,通过T2T,你可以使用单个GPU,在一天时间里获得此前最漂亮的结果:小规模Transformer模型基于单个GPU在一天的训练后获得了24.9 BLEU。
目前,所有拥有GPU的研究者都可以自行探索最强大的翻译模型。我们在Github上介绍了如何去做。
模块化的多任务训练
T2T库利用TensorFlow工具来开发,定义了一个深度学习系统中需要的多个部分:数据集、模型架构、优化工具、学习速率衰减计划,以及超参数等等。
最重要的是,T2T在所有这些部分之间实现了标准接口,并配置了当前机器学习的较佳行为方式。
因此,你可以选择任意数据集、模型、优化工具,以及一套超参数,随后运行训练,看看效果如何。
我们实现了架构的模块化,因此输入数据和预期输出结果之间所有部分都是张量到张量的函数。
如果你对模型的架构有新想法,那么不需要替换所有设置。你可以保留嵌入的部分,用自己的函数来替换模型体。这样的函数以张量为输入,并返回张量。
这意味着T2T很灵活,训练不再局限于特定模型或数据集。
这也非常简单,例如知名的LSTM序列到序列模型可以用几十行代码来定义。你也可以用不同类型的多任务来训练单个模型。在一定的限制下,单个模型甚至可以使用所有数据集来训练。
例如,我们的MultiModel模型用这种方式在T2T中进行了训练,在许多任务中取得了良好的结果。这一模型使用的训练数据集包括ImageNet(图像分类)、MS COCO(图像标注)、WSJ(语音识别)、WMT(翻译),以及Penn Treebank分析语料库。
这是首次证明,单个模型能同时执行所有这些任务。
内置的较佳行为方式
在最初版本中,我们还提供了脚本,用于生成在研究领域广泛使用的数据集,少量模型,大量的超参数配置,以及其他一些技巧的配置。
考虑一下这样的任务:将英语语句解析为语法选区树。这个问题的研究已有几十年历史,并诞生了许多有竞争力的解决办法。这可以被视为一个序列到序列问题,并使用神经网络来解决。不过,这需要大量的调节优化。通过T2T,我们只需几天时间,就可以添加解析数据集生成器,并调整我们的注意力转换模型,针对这个问题来训练。惊喜的是,我们在一周时间里就取得了很好的结果。
相关资源
Tensor2Tensor GitHub:
https://github.com/tensorflow/tensor2tensor
Google Research Blog原文:
https://research.googleblog.com/2017/06/accelerating-deep-learning-research.html
文中提到“近期几篇论文中最优秀的模型”,这几篇论文分别是:
Attention Is All You Need
https://arxiv.org/abs/1706.03762
Depthwise Separable Convolutions for Neural Machine Translation
https://arxiv.org/abs/1706.03059
One Model to Learn Them All
https://arxiv.org/abs/1706.05137
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4565.html
摘要:机器学习作为时下最为火热的技术之一受到了广泛的关注。文中给出的个建议都是针对机器学习系统的,没有包含通用软件工程里那些单元测试,发布流程等内容,在实践中这些传统最佳实践也同样非常重要。 图片描述 「观远AI实战」栏目文章由观远数据算法天团倾力打造,观小编整理编辑。这里将不定期推送关于机器学习,数据挖掘,特征重要性等干货分享。本文8千多字,约需要16分钟阅读时间。 机器学习作为时下最为火...
摘要:本文内容节选自由主办的第七届,北京一流科技有限公司首席科学家袁进辉老师木分享的让简单且强大深度学习引擎背后的技术实践实录。年创立北京一流科技有限公司,致力于打造分布式深度学习平台的事实工业标准。 本文内容节选自由msup主办的第七届TOP100summit,北京一流科技有限公司首席科学家袁进辉(老师木)分享的《让AI简单且强大:深度学习引擎OneFlow背后的技术实践》实录。 北京一流...
摘要:它可以用来做语音识别,使得一个处理语音,另一个浏览它,使其在生成文本时可以集中在相关的部分上。它对模型使用的计算量予以处罚。 本文的作者是 Google Brain 的两位研究者 Chris Olah 和 Shan Carter,重点介绍了注意力和增强循环神经网络,他们认为未来几年这些「增强 RNN(augmented RNN)」将在深度学习能力扩展中发挥重要的作用。循环神经网络(recur...

阅读 3421·2021-10-18 13:33
阅读 876·2019-08-30 14:20
阅读 2671·2019-08-30 13:14
阅读 2563·2019-08-29 18:38
阅读 2928·2019-08-29 16:44
阅读 1247·2019-08-29 15:23
阅读 3567·2019-08-29 13:28
阅读 1955·2019-08-28 18:00




