
摘要:近段时间以来,张量与新的机器学习工具如是非常热门的话题,在那些寻求应用和学习机器学习的人看来更是如此。计算机之所以可凭极快速度求出用线性代数编写的程序值,部分原因是线性代数具有规律性。但是,我们没有必要把自己限制在线性代数上。
近段时间以来,张量与新的机器学习工具(如 TensorFlow)是非常热门的话题,在那些寻求应用和学习机器学习的人看来更是如此。但是,当你回溯历史,你会发现一些基础但强大的、有用且可行的方法,它们也利用了张量的能力,而且不是在深度学习的场景中。下面会给出具体解释。
如果说计算是有传统的,那么使用线性代数的数值计算就是其中最重要的一支。像 LINPACK 和 LAPACK 这样的包已经是非常老的了,但是在今天它们任然非常强大。其核心,线性代数由非常简单且常规的运算构成,它们涉及到在一维或二维数组(这里我们称其为向量或矩阵)上进行重复的乘法和加法运算。同时线性代数适用范围异常广泛,从计算机游戏中的图像渲染到核武器设计等许多不同的问题都可以被它解决或近似计算,
关键的线性代数运算:在计算机上使用的最基础的线性代数运算是两个向量的点积(dot product)。这种点积仅仅是两个向量中相关元素的乘积和。一个矩阵和一个向量的积可以被视为该矩阵和向量行(row)的点积,两个矩阵的乘积可以被视为一个矩阵和另一个矩阵的每一列(column)进行的矩阵-向量乘积的和。此外,再配上用一个值对所有元素进行逐一的加法和乘法,我们可以构造出所需要的线性代数运算机器。
计算机之所以可凭极快速度求出用线性代数编写的程序值,部分原因是线性代数具有规律性。此外,另一个原因是它们可以大量地被并行处理。完全就潜在性能而言,从早期的 Cray-1(译者注:Cary-1 是世界上最早的一台超级计算机,于 1975 年建造,运算速度每秒 1 亿次)到今天的 GPU 计算机,我们可以发现性能增长了超过 30000 倍。此外,当你要考虑用大量 GPU 处理集群数据时,其潜在的性能,在极小成本下,比曾经世上最快速的计算机大约高出一百万倍。
然而,历史的模式总是一致的,即要想充分利用新的处理器,我们就要让运算越来越抽象。Cray-1 和它向量化的后继者们需要其运行程序能够使用向量运算(如点积)才能发挥出硬件的全部性能。后来的机器要求要就矩阵-向量运算或矩阵-矩阵运算来将算法形式化,从而方可尽可能地发挥硬件的价值。
我们现在正站在这样一个结点上。不同的是我们没有任何超越矩阵-矩阵运算的办法,即:我们对线性代数的使用已达极限。
但是,我们没有必要把自己限制在线性代数上。事实证明,我们可以沿着数学这棵大树的枝叶往上再爬一段。长期以来,人们都知道在数学抽象的海洋中存在着比矩阵还要大的鱼,这其中一个候选就是张量(tensor)。张量是广义相对论重要的数学基础,此外它对于物理学的其它分支来说也具有基础性的地位。那么如同数学的矩阵和向量概念可被简化成我们在计算机中使用的数组一样,我们是否可以将张量也简化和表征成多维数组和一些相关的运算呢?很不幸,事情没有那么简单,这其中的主要原因是不存在一个显而易见且简单的(如在矩阵和向量上类似的)可在张量上进行的一系列运算。
然而,也有好消息。虽然我们不能对张量使用仅几个运算。但是我们可以在张量上写下一套运算的模式(pattern)。不过,这还不不够,因为根据这些模式编写的程序不能像它们写的那样被充分高效地执行。但我们还有另外的好消息:那些效率低下但是编写简单的程序可以被(基本上)自动转换成可非常高效执行的程序。
更赞的是,这种转换可以无需构建一门新编程语言就能实现。只需要一个简单的技巧就可以了,当我们在 TensorFlow 中写下如下代码时:
v1 = tf.constant(3.0)
v2 = tf.constant(4.0)
v3 = tf.add(node1, node2)
实际情况是,系统将建立一个像图 1 中显示的数据结构:
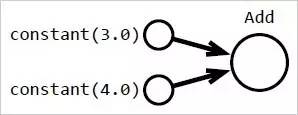
图 1:上方的代码被转译成一个可被重建的数据结构,而且它会被转成机器可执行的形式。将代码转译成用户可见的数据结构可让我们所编写的程序能被重写从而更高效地执行,或者它也可以计算出一个导数,从而使高级优化器可被使用。
该数据结构不会在上面我们展示的程序中实际执行。因此,TensorFlow 才有机会在我们实际运行它之前,将数据结构重写成更有效的代码。这也许会牵涉到我们想让计算机处理的小型或大型结构。它也可生成对我们使用的计算机 CPU、使用的集群、或任何手边可用的 GPU 设备实际可执行的代码。对它来说很赞的一点是,我们可以编写非常简单但可实现令人意想不到结果的程序。
然而,这只是开始。
做一些有用但不一样的事
TensorFlow 和像它一样的系统采用的完全是描述机器学习架构(如深度神经网络)的程序,然后调整那个架构的参数以最小化一些误差值。它们通过创建一个表征我们程序的数据结构,和一个表征相对于我们模型所有参数误差值梯度的数据结构来实现这一点。这个梯度函数的存在使得优化变得更加容易。
但是,虽然你可以使用 TensorFlow 或 Caffe 或任何其它基本上同样工作模式的架构来写程序,不过你写的程序不一定要去优化机器学习函数。如果你写的程序使用了由你选择的包(package)提供的张量标注,那它就可以优化所有类型的程序。自动微分和较先进的优化器以及对高效 GPU 代码的编译对你仍然有利。
举个简例,图二给出了一个家庭能耗的简单模型。
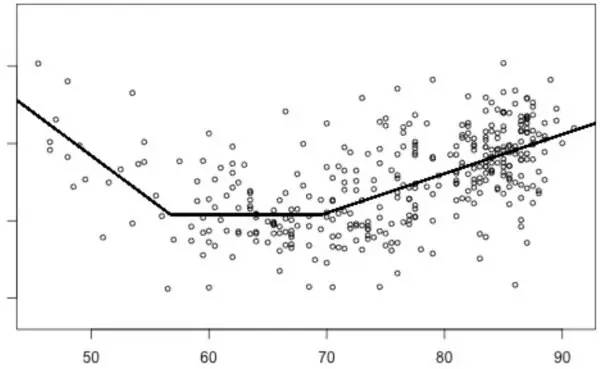
图 2:该图显示了一间房子的日常能耗情况(圆圈),横轴代表了温度(华氏度)。能耗的一个分段线性模型叠加在了能耗具体数据上。模型的参数按理来说会形成一个矩阵,但是当我们要处理上百万个模型时,我们便可以用到张量。
该图显示了一间房子的能耗使用情况,并对此进行了建模。得到一个模型不是什么难事,但是为了找出这个模型,笔者需要自己写代码来分别对数百万间房子的能耗情况进行建模才行。如果使用 TensorFlow,我们可以立即为所有这些房子建立模型,并且我们可以使用比之前得到这个模型更有效的优化器。于是,笔者就可以立即对数百万个房间的模型进行优化,而且其效率比之前我们原始的程序要高得多。理论上我们可以手动优化代码,并且可以有人工推导的导数函数。不过完成这项工作所需要的时间,以及更重要的,调试花费的时间会让笔者无法在有限时间里建立这个模型。
这个例子为我们展示了一个基于张量的计算系统如 TensorFlow(或 Caffe 或 Theano 或 MXNet 等等)是可以被用于和深度学习非常不同的优化问题的。
所以,情况可能是这样的,对你而言较好用的机器学习软件除了完成机器学习功能以外还可以做很多其它事情。
原文链接:http://www.kdnuggets.com/2017/06/deep-learning-demystifying-tensors.html
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4563.html
摘要:是一个专为移动端异构计算平台优化的神经网络计算框架。地址文档链接打开在线文档网页,引入眼帘的是这里简单介绍一下中的内容移动计算引擎是一种针对移动异构计算平台优化的深度学习推理框架。 Mobile AI Compute Engine (MACE) 是一个专为移动端异构计算平台优化的神经网络计算框架。主要从以下的角度做了专门的优化:性能代码经过NEON指令,OpenCL以及Hexagon HVX...

阅读 2418·2023-04-25 23:15
阅读 2107·2021-11-22 09:34
阅读 1664·2021-11-15 11:39
阅读 1046·2021-11-15 11:37
阅读 2331·2021-10-14 09:43
阅读 3591·2021-09-27 13:59
阅读 1594·2019-08-30 15:43
阅读 3608·2019-08-30 15:43



