
摘要:受到其他同行在上讨论更好经验的激励,我决定买一个专用的深度学习盒子放在家里。下面是我的选择从选择配件到基准测试。即便是深度学习的较佳选择,同样也很重要。安装大多数深度学习框架是首先基于系统开发,然后逐渐扩展到支持其他操作系统。
在用了十年的 MacBook Airs 和云服务以后,我现在要搭建一个(笔记本)桌面了
几年时间里我都在用越来越薄的 MacBooks 来搭载一个瘦客户端(thin client),并已经觉得习以为常了。所以当我涉入深度学习(DL)领域后,我毫不犹豫的选择了当时的 Amazon P2 云服务。该云服务不需要预付成本,能同时训练很多个模型,并且还能让一个机器学习模型慢慢地训练自己。
但随着时间推移,AWS(亚马逊云服务)的账单逐渐越堆越高,即便我换成了便宜十倍的 Spot instances 也没用。而且我也没有同时训练过多个模型。在模型训练的时候,我会去吃午饭,锻炼等等,然后带着一个更清晰的头脑回来查看它。
但最终我模型的复杂度增加了,训练时间也变得更长。对一个刚完成两天训练的模型,我经常会忘记之前对它进行了哪些不同的操作。受到其他同行在 Fast.AI Forum 上讨论更好经验的激励,我决定买一个专用的深度学习盒子(DL box)放在家里。
最重要的原因就是能在进行模型的原型设计时节省时间,如果我们能训练地更快,反馈时间也会更短。这能让我们更容易的在头脑中建立起模型假设和结果之间的联系。
而且我也想省钱,我之前用的是亚马逊网络服务(AWS),它通过 Nvidia K80 的 GPU 来提供 P2 instances。最近 AWS 的费用达到了每月 60 到 70 美元,还有增长的趋势。并且要储存大型数据集也很贵,比如 ImageNet 这样的。
最后一点,我已经有 10 年没有一个(笔记本的)桌面了,想看看现在有什么变化(这里剧透一下:基本上没变化)。
下面是我的选择:从选择配件到基准测试。
目录
1. 选择配件
2. 把它们组装在一起
3. 软件设置
4. 基准测试
选择配件
对我来说合理的预算是两年云计算服务的成本。以我目前的情况来看,即 AWS 每月 70 美元的使用费,那么总预算应该在 1700 美元左右。
PC Part Picker 这个网站非常有帮助,可以帮你发现是否某些配件放在一起并不好用。
你可以在这里查看所有使用过的配件:https://pcpartpicker.com/list/T6wHjc
GPU
GPU 是整个机箱里最关键的部件了。它训练深度网络的速度更快,从而缩短反馈循环(的周期)。
GPU 很重要是因为:a) 深度学习中绝大部分计算都是矩阵运算,比如矩阵乘法之类。而用 CPU 进行这类运算就会很慢。b)当我们在一个典型的神经网络中进行成千上万个矩阵运算时,这种延迟就会累加(我们也会在后面的基准训练部分看到这一点)。而另一方面,GPU 就更方便了,因为能并行的运行所有这些运算。他们有很多个内核,能运行的线程数量则更多。GPU 还有更高的存储带宽,这能让它们同时在一群数据上进行这些并行计算。
我在几个 Nvidia 的芯片之间选择:GTX 1070 (360 美元), GTX 1080 (500 美元), GTX 1080 Ti (700 美元),以及 Titan X(1320 美元)。
在性能方面,GTX 1080 Ti 和 Titan X 较接近,粗略来看 GTX 1080 大约比 GTX 1070 快了 25%,而 GTX 1080 Ti 则比 GTX 1080 快乐 30% 左右。
Tim Dettmers 有一篇更好的关于选择深度学习 GPU 的文章,而且他还经常会在新的芯片上市后更新博文:http://timdettmers.com/2017/04/09/which-gpu-for-deep-learning/
下面是选购 GPU 时需要考虑的事情:
品牌:这里没什么可说的,选 Nvidia 就对了。它们已经专注于机器学习很多年了,并且取得了成果。他们的统一计算设备架构(CUDA)工具包在这个领域里有着不可撼动的地位,所以它真的是深度学习从业者的选择。
预算:Titan X 在这方面真的没有任何优势,因为它比同样性能的 1080 Ti 贵了 500 多美元。
一个还是多个:我考虑过用一堆 1070s 去替代(单个)1080 或 1080 Ti。这能让我在两个芯片上训练一个模型,或同时训练两个模型。目前在多个芯片上训练一个模型还有点麻烦,不过现在有所转机,因为 PyTorch 和 Caffe 2 提供了随着 GPU 数量几乎成线性提升的训练规模。另一个选择—同时训练两个模型似乎更有价值,但我决定现在先用一个强大的核心,以后再添加另一个。
内存:内存越大当然就越好了。更多的存储空间能让我们部署更大的模型,并且在训练时使用足够大的批量大小(这会对梯度流很有帮助)。
存储带宽:这能让 GPU 在更大的内存上运行。Tim Dettmers 指出这对于一个 GPU 来说是最重要的指标。
考虑到所有这些,我选择了 GTX 1080 Ti,主要是考虑到训练速度的激增。我计划很快再增加一个 1080 Ti。
CPU
即便 GPU 是深度学习的较佳选择,CPU 同样也很重要。比如说数据预处理通常都是在 CPU 上进行的。如果我们想把所有的数据提前并行,核的数量和每个核的线程数就非常重要了。
为了不偏离预算,我选择了一个中等程度的 CPU,Intel i5 7500,价格大概在 190 美元。相对来说挺便宜,但也足够保证不拖慢速度。
内存(RAM)
如果我们要在一个较大数据集上工作,当然钱多好办事,内存总是多多益善的。我买了两根 16 GB 的内存条,也就是以 230 美元的价格买下了总共 32 GB 的 RAM,而且打算以后再买 32 GB 的。
硬盘
遵循了 Jeremy Howard 的建议,我买了一个固态硬盘(SSD)搭载我的操作系统和现有的数据,还有一个慢转硬盘驱动器(HDD)来存储那些大型数据集(比如 ImageNet)。
SSD:我记得多年前买到第一部 Macbook Air 时,是如何惊叹于它的固态硬盘速度的。让我高兴的事,与此同时,叫做 NVMe 的新一代固态硬盘上市了。230 美元买到一个 480 GB 的 MyDigitalSSDNVMe 驱动真的很值。这个宝贝能以每秒千兆字节的速度拷贝数据。
HDD: 66 美元 2 TB。在 SSD 越来越快的同时,HDD 变得更便宜了。对一个用了 7 年 128 GB 的 Macbook 的人来说,有如此大容量的硬盘简直是太棒了。
主板
有一件我一直很关心的事,就是挑选一块能支持两块 GTX 1080 Ti 的主板,两个都在串行总线(PCI Express Lanes)的数量上(最小的是 2x8),并且有能放下两个芯片的物理空间。还要确保它跟选好的 CPU 兼容。最后一个 130 美元的 Asus TUF Z270 主板帮我做到了这一点。
电源
经验法则:它应该能为 CPU 和 GPU 提供足够的能量,再加上外的 100 瓦。
Intel i5 7500 处理器的能耗是 65W,每个 GPU (1080 Ti) 需要 250W,所以我用 75 美元买了一个 Deepcool 750W Gold 电源供应单元(PSU)。这里的「Gold」指的是电源效率(power efficiency),即它以热量的形式损耗了多大的功率。
机箱
机箱应该跟母板有相同的形状系数。如果也能有足够的 LED 来防止过热就更好了。
一个朋友推荐了 Thermaltake N23 机箱,价格 50 美元,我马上就买了下来。可惜没有 LED。

组装派对就要开始了
组装
如果你没有太多的硬件经验,并害怕弄坏某些部件,较好是找专业人士来组装。然而,这可是我无法错过的学习机会啊(即时我已经分享过此前操作硬件的悲惨经历了)。
第一步也是很重要的一步就是 阅读说明手册,每个配件都会有一个手册。这对我尤其重要,因为我已经做过一两次组装了,正好处于那种经验不足容易搞砸事情的阶段。

主板上的示意图
在主板上安装 CPU

CPU 放在了它的卡槽里,但杠杆拉不下去。
这一步要在把母板放入机箱之前完成。处理器旁边有一个杠杆,需要提起来。这时候处理器就放在了底座上(这里要检查两次朝向是否正确)。最终杠杆会放下把 CPU 固定住。

我在安装 CPU 时获得了帮助
但我进行这一步的时候很困难,一旦 CPU 放在了位置上,杠杆却无法下降。我其实是让一个更懂硬件的朋友通过视频通话指导我完成的。结果发现把杠杆拉下去需要的力量超过了我预期的程度。

安装好的风扇
下一步就要把风扇固定在 CPU 的顶部:风扇的脚柱必须用螺丝旋紧到母板上。还要在安装前考虑到把风扇的电线放在哪里。我买的处理器带有热熔胶。如果你的没有,要确保在 CPU 和冷却单元之间加一些胶。如果你把风扇拿下来了,也要把胶更换掉。
在机箱里安装电源

穿过背面固定电源线
我把电源供应单元(PSU)放在了主板的前方,让电源线紧密的贴在机箱背侧。
在机箱里安装主板
这一步非常简单直接,小心地放进去然后拧紧。一个磁性的螺丝刀是非常有帮助的。
然后连接电源线和机箱按键以及 LED。
安装 NVMe 盘

把他放到 M2 槽里再拧紧就好了。小菜一碟。
安装 RAM

在我费力的把 RAM 装到基底上时,GTX 1080 Ti 静静的躺在那里等着轮到它。
结果我发现内存条非常难装,需要花很多功夫把它正确的固定住。有几次我差点就放弃了,想着我肯定做的不对。最终有一个齿对上了,其他齿很快也跟着进去了。
这时候我打开了电脑,以确保它能工作。让我兴奋的是,它正常启动了!
安装 GPU

GTX 1080 Ti 放入主板
终于,GPU 毫不费力的就滑了进去。14 个引脚提供的电能让它运行了起来。
注意:不要立刻就把你的显示器插入多余的卡槽。绝大部分情况下它需要驱动来运行(详见下面的部分)。
终于,它完成了!

软件设置
现在硬件设备已经就绪,我们不再需要螺丝刀,而是键盘来设置相应的软件环境。
双系统注意事项:如果你打算安装 Windows 操作系统(出于基准测试的考虑,完全不是为了打游戏),那么请先安装 Windows 再安装 Linux。如果先装的 Linux,那么不但用不上双系统,还得重装 Ubuntu,因为 Windows 把启动分区弄乱了。
安装 Ubuntu
大多数深度学习框架是首先基于 Linux 系统开发,然后逐渐扩展到支持其他操作系统。所以我选择了 Ubuntu,默认的 Linux 系统发行版。一个老掉牙的 2G 的 USB 驱动盘对于系统安装来说也还挺好使的。UNetbootin (OSX) 或者 Rufus (Windows)都可用于制作 Linux 的闪盘驱动。在 Ubuntu 的安装过程中,一路默认选项到底都工作正常,没出什么问题。
写这篇文章的时候 Ubuntu 17.04 刚刚发行,我仍然使用的是上一个版本(16.04),而且网上也可以找到该版本很全面的快速入门手册。
Ubuntu 服务器或者桌面版本:Ubuntu 服务器版本和桌面版本几乎完全相同,只是服务器版本未安装可视化界面(简称 X)。我安装了桌面版本并禁用了自启动 X, 以便计算机可以在终端启动 X。如有需要,还可以稍后通过键入 startx 来启动可视化桌面。
更新
现在让我们把系统更新到版本。这里用的是 Jeremy Howard 写的一个超级棒的 install-gpu 指令:
sudo apt-get update
sudo apt-get --assume-yes upgrade
sudo apt-get --assume-yes install tmux build-essential gcc g++ make binutils
sudo apt-get --assume-yes install software-properties-common
sudo apt-get --assume-yes install git
深度学习利器
为了使我们的计算机得到较大限度的深度学习使用,我们需要一系列技术来开发利用我们的 GPU:
GPU 驱动程序—操作系统与显卡的交互手段
CUDA—允许我们在 GPU 上运行通用代码
CuDNN—在 CUDA 之上提供常规的深度神经网络程序
深度学习框架—Tensorflow、PyTorch、 Theano 等等。有了这些学习框架,深度神经网络就像搭积木一样,简直简单太多了。
安装 CUDA
从 Nvidia 下载 CUDA, 或者直接运行如下指令:
wget http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_8.0.61-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu1604_8.0.61-1_amd64.deb
sudo apt-get update
sudo apt-get install cuda
安装完毕之后,运行如下指令为 CUDA 添加到路径变量:
cat >> ~/.tmp << "EOF"
export PATH=/usr/local/cuda-8.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
EOF
source ~/.bashrc
运行如下指令测试 CUDA 是否安装成功:
nvcc --version # Checks CUDA version
nvidia-smi # Info about the detected GPUs
显卡驱动程序的安装指令如下。对于我的机器来说,nvidia-smi 用 ERR 作为设备名称,所以我安装了版本的 Nvidia 驱动(本文写作之时刚解决这个问题):
wget http://us.download.nvidia.com/XFree86/Linux-x86_64/378.13/NVIDIA-Linux-x86_64-378.13.run
sudo sh NVIDIA-Linux-x86_64-375.39.run
sudo reboot
移除 CUDA/Nvidia 驱动
如果出于某种原因或者 CUDA 看起来坏掉了(我碰到过很多次这样的情况),那我们可以运行如下指令进行重装:
sudo apt-get remove --purge nvidia*
sudo apt-get autoremove
sudo reboot
CuDNN
由于目前的 Tensorflow 版本尚不支持 CuDNN 6, 所以我安装的是 CuDNN 5.1 版本。要下载 CuDNN,首先需要注册一个免费的开发者账户。下载完毕后,安装操作如下:
tar -xzf cudnn-8.0-linux-x64-v5.1.tgz
cd cuda
sudo cp lib64/* /usr/local/cuda/lib64/
sudo cp include/* /usr/local/cuda/include/
Anaconda
Anaconda 是一个非常强大的 Python 包与环境管理工具。我的 Python 版本已经是 3.6,所以使用了 Anaconda 3 版本。其安装指令如下:
wget https://repo.continuum.io/archive/Anaconda3-4.3.1-Linux-x86_64.sh -O「anaconda-install.sh」
bash anaconda-install.sh -b
cat >> ~/.bashrc << "EOF"
export PATH=$HOME/anaconda3/bin:${PATH}
EOF
source .bashrc
conda upgrade -y --all
source activate root
TensoFlow
Tensorflow 是 Google 开源的一款非常流行的深度学习框架,安装方法如下:
sudo apt install python3-pip
pip install tensorflow-gpu
验证 Tensorflow 的安装:为保证我们的一系列工具能够顺畅地运行,我运行 Tensorflow 的 MNIST 数据做测试:
git clone https://github.com/tensorflow/tensorflow.git
python tensorflow/tensorflow/examples/tutorials/mnist/fully_connected_feed.py
我们可以看到,在训练过程中损失也是在下降的:
Step 0: loss = 2.32 (0.139 sec)
Step 100: loss = 2.19 (0.001 sec)
Step 200: loss = 1.87 (0.001 sec)
Keras
Keras 是一款高级的神经网络框架,非常友好的工作利器。它的安装也是再简单不过了:
pip install keras
PyTorch
PyTorch 是深度学习框架领域的后来者,但它的 API 是基于非常成熟的 Torch。PyTorch 虽然仍然处在需要继续试用的阶段,但总的来说它给人全新的感受,非常出色。安装指令如下:
conda install pytorch torchvision cuda80 -c soumith
Jupyter 笔记本
Jupyter 是一个基于网页的 IDE,适用于 Python。它是一款理想的数据科学任务处理工具,可以通过 Anaconda 安装,所以我们只需简单地配置并测试:
# Create a ~/.jupyter/jupyter_notebook_config.py with settings
jupyter notebook --generate-config
jupyter notebook --port=8888 --NotebookApp.token="" # Start it
现在我们只需在浏览器键入 http://localhost:8888,就可以见到 Jupyter 界面。
启动时运行 Jupyter
与其在电脑每次重启时多带带运行 Jupyter,我们可以将其设置成启动时自动运行。使用 crontab -e 命令来完成这项操作,然后在 crontab 文件的最后一行添加指令如下:
# Replace "path-to-jupyter" with the actual path to the jupyter
# installation (run "which jupyter" if you don"t know it). Also
# "path-to-dir" should be the dir where your deep learning notebooks
# would reside (I use ~/DL/).
@reboot (http://twitter.com/reboot) path-to-jupyter ipython notebook --no-browser --port=8888 --NotebookApp.token="" --notebook-dir path-to-dir &
外部访问
我用的是一台虽然旧但是完全可靠的 MacBook Air 来做开发,我希望能在家登录到这个深度学习网络。
使用 SSH 比简单地使用密码更为安全。关于如何设置可以参考 Digital Ocean 提供的指南:https://www.digitalocean.com/community/tutorials/how-to-set-up-ssh-keys--2
SSH 通道:如果你希望在另外一台电脑上使用你的 Jupyter 笔记本,推荐使用 SSH 通道(以取代用密码来打开笔记本)。让我们来看看具体该怎么做:
首先我们需要一个 SSH 服务器。我们只需在深度学习盒子(服务器)上运行如下指令即可安装 SSH:
sudo apt-get install openssh-server
sudo service ssh status
然后在客户端运行以下脚本来连接 SSH 通道:
# Replace user@host with your server user and ip.
ssh -N -f -L localhost:8888:localhost:8888 user@host
在远程机器上打开浏览器,键入 http://localhost:8888 进行测试,这时候屏幕上应该可以出现你的 Jupyter 笔记本了。
设置网络外访问:最后,需要从外部访问深度学习网络,我们需要三个步骤:
你的家庭网络的静态 IP (或者一个可用于模拟的服务器)—以便我们可以知道将要联通的地址。
一个手动 IP 或者 DHCP 保留设置,这样可以将深度学习所在的服务器地址设置为你家庭网络的永久地址。
从路由器到深度学习盒子的端口转发。
外部网络的访问权限取决于路由器以及网络的设置,所以我在此不做赘述。
基准测试
现在一切都运行顺畅,我们可以用这个新盒子来做些测试了。我会把这套新组装成的系统与 AWS P2 来做比较,AWS P2 是我之前使用的深度学习系统。由于我们的测试都跟计算机视觉有关,这意味着得使用卷积网络和一个全连接模型。我们分别用 AWS P2 GPU(K80) 、AWS P2 CPU、GTX1080 Ti 以及 Intel I5 来训练模型,并比较其各自的运行时间。
MNIST 多层感知机
计算机视觉领域的"hello world"—MNIST 数据库,收集了 70,000 个手写的数字。我们运行 Keras 中的多层感知机 (MLP) 来处理 MNIST 数据库。多次感知机只需全连接层而不用卷积。该模型将数据训练了 20 个 epoch 之后,准确率达到了 98%。
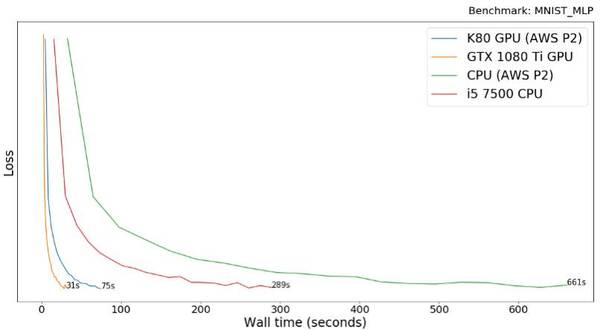
训练该模型时,GTX 1080 Ti 比 AWS P2 的 K80 要快 2.4 倍。这是让人感到惊讶的结果,因为通常说来这二者的表现应该差不多。我认为原因可能出在 AWS K80 的虚拟化或者降频问题上。
CPU 运行起来比 GPU 慢 9 倍之多。所有实验结束后我们可知,这其实对处理器来说已经是一个很好的结果了。因为此类简单模型还不能充分发挥出 GPU 并行运算的能力。
有意思的是,台式机 Intel i5-7500 在 Amazon 的虚拟 CPU 上实现了 2.3 倍的加速。
VGG(Visual Geometry Group)调参
VGG 网络将被用于 Kaggle 举办的猫狗辨识比赛。这个比赛旨在辨识出给定图片是猫还是狗。在 GPU 上运行相同批次(batches)数量的模型不太可行。所以我们在 GPU 上运行 390 批次(1 epoch),在 CPU 上运行 10 个批次。代码可以在 GitHub 上找到:https://github.com/slavivanov/cats_dogs_kaggle
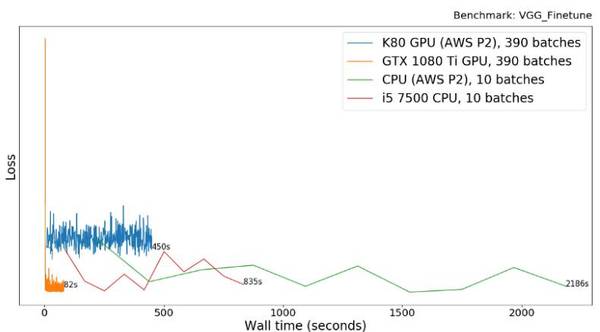
1080 Ti 比 AWS GPU(K80) 快了 5.5 倍。这应该与上一个实验结果(i5 快 2.6 倍)有类似的原因。然而 CPU 对于该任务来说根本不适用,因为相较于 GPU, 运行这种包括了 16 层卷积层和一对 semi-wide(4098)全连接层的大型模型,CPU 得花 200 多倍的时间。
Wasserstein GAN
GAN(生成对抗网络)是一种训练模型使其生成图片的方法。其原理是将两种网络结构放在一起相互对抗:其生成器将学习生成越来越高质量的图片,而辨别器则会尝试辨别出哪些图片是真实的哪些是由生成其「伪造」出来的。
Wasserstein GAN 是经典生成对抗网络的升级。我们用 PyTorch 来实现这一模型,该实现和 WGAN 作者所完成的很像。模型训练了 50 步,几乎每一步都有损失,这是 GAN 网络模型的普遍情况。通常并不考虑使用 CPU 来完成。
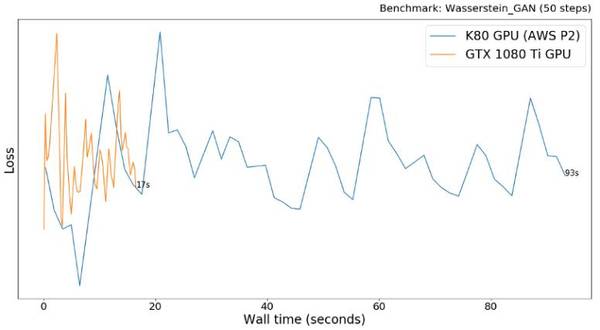
GTX 1080Ti 比 AWS P2 K80 快了 5.5 倍,这样的结果与之前的实验结果是一致的。
风格迁移
最后一个基准测试是源自一篇关于图片风格转换器的论文(Gateys et al.),使用的是 Tensorflow。风格转换是一种图片处理技术,它能将某一张图片(比如一幅画)的风格与另一张图片的内容相结合,从而生成新的图片。它分离和重组任意图像的内容和样式,为艺术图像的创建提供了一种新算法。
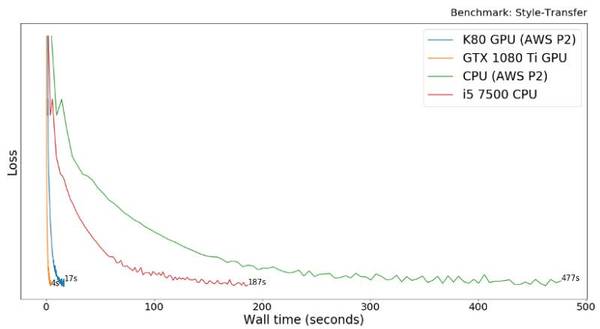
GTX 1080Ti 比 AWS P2 K80 快了 4.3 倍。这次 CPU 比 GPU 慢了 30-50 倍,已经比在 VGG 任务中的表现好多了,但仍然比 MNIST 多层感知机实验结果慢。该模型主要使用 VGG 网络中的较初级的层级,我怀疑这样浅层的网络无法充分利用 GPU。
以上就是这一次搭建的深度学习盒子的基准测试,我不知道从 AWS 转入到自建服务器到底是好还是坏,但时间会告诉我们一切!
原文地址:https://blog.slavv.com/the-1700-great-deep-learning-box-assembly-setup-and-benchmarks-148c5ebe6415
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4547.html
摘要:在低端领域,在上训练模型的价格比便宜两倍。硬件定价价格变化频繁,但目前提供的实例起价为美元小时,以秒为增量计费,而更强大且性能更高的实例起价为美元小时。 随着越来越多的现代机器学习任务都需要使用GPU,了解不同GPU供应商的成本和性能trade-off变得至关重要。初创公司Rare Technologies最近发布了一个超大规模机器学习基准,聚焦GPU,比较了几家受欢迎的硬件提供商,在机器学...
摘要:很明显这台机器受到了英伟达的部分启发至少机箱是这样,但价格差不多只有的一半。这篇个文章将帮助你安装英伟达驱动,以及我青睐的一些深度学习工具与库。 本文作者 Roelof Pieters 是瑞典皇家理工学院 Institute of Technology & Consultant for Graph-Technologies 研究深度学习的一位在读博士,他同时也运营着自己的面向客户的深度学习产...
摘要:本文作者详细描述了自己组装深度学习服务器的过程,从主板电源机箱等的选取到部件的安装,再到服务器的设置,可谓面面俱到。注本文旨在讨论服务器设置及多用户协作,部件组装和软件安装过程是关于创建自己的的文章的简化版本。本文作者详细描述了自己组装深度学习服务器的过程,从 CPU、GPU、主板、电源、机箱等的选取到部件的安装,再到服务器的设置,可谓面面俱到。作者指出,组装者首先要弄清自己的需求,然后根据...
摘要:深度学习是一个对算力要求很高的领域。这一早期优势与英伟达强大的社区支持相结合,迅速增加了社区的规模。对他们的深度学习软件投入很少,因此不能指望英伟达和之间的软件差距将在未来缩小。 深度学习是一个对算力要求很高的领域。GPU的选择将从根本上决定你的深度学习体验。一个好的GPU可以让你快速获得实践经验,而这些经验是正是建立专业知识的关键。如果没有这种快速的反馈,你会花费过多时间,从错误中吸取教训...
摘要:但是如果你和我是一样的人,你想自己攒一台奇快无比的深度学习的电脑。可能对深度学习最重要的指标就是显卡的显存大小。性能不错,不过够贵,都要美元以上,哪怕是旧一点的版本。电源我花了美元买了一个的电源。也可以安装,这是一个不同的深度学习框架。 是的,你可以在一个39美元的树莓派板子上运行TensorFlow,你也可以在用一个装配了GPU的亚马逊EC2的节点上跑TensorFlow,价格是每小时1美...

阅读 1813·2021-11-24 09:39
阅读 1745·2021-11-22 15:22
阅读 1052·2021-09-27 13:36
阅读 3392·2021-09-24 10:34
阅读 3389·2021-07-26 23:38
阅读 2675·2019-08-29 16:44
阅读 1010·2019-08-29 16:39
阅读 1169·2019-08-29 16:20






