摘要:在机器学习中,设计正确的文件架构并不简单。当你在进行机器学习项目时,模型通过你使用的框架共享了许多相似之处。因为与机器学习研究交互的主要结束点就是你使用任何工具的外壳,程序外壳是你实验的基石。
在机器学习中,设计正确的文件架构并不简单。我自己在几个项目上纠结过此问题之后,我开始寻找简单的模式,并希望其能覆盖大部分在读代码或自己编代码时遇到的使用案例。
在此文章中,我会分享我自己的发现。
声明:该文章更像是建议,而非明确的指导,但我感觉挺成功的。该文章意在为初学者提供起点,可能会引发一些讨论。因为一开始我想要为自己的工作设计文件架构,我想我能分享下这方面的内容。如果你有更好的文件架构理论,可以留言分享。
总需要得到什么?
想下在你做机器学习的时候,你必须要做的是什么?
需要编写一个模型
该模型(至少)有两个不同的阶段:训练阶段和推论阶段(成果)
需要为该模型输入数据集(训练阶段)
可能也需要为它输入单个元素(推论阶段)
需要调整它的超参数
精调超参数,需要模型是可配置的,并创造一个类似「API」的存在,至少能让你推动配置的运行
训练结果需要好的文件夹(folder)架构(以便于浏览并轻易的记住每个实验)
需要用图表示一些指标,比如损失或准确率(在训练以及成果阶段)
想要这些图能够轻易地被搜索到
想要能够复制所做的任何实验
甚至在训练阶段希望跳回前面,以检查模型
在构造文件和文件夹时,很容易就会忘记以上这些。此外,可能还有其他需求我并未列出。下面,让我们寻找一些较好的实践。
整体文件夹架构
一图胜千言:
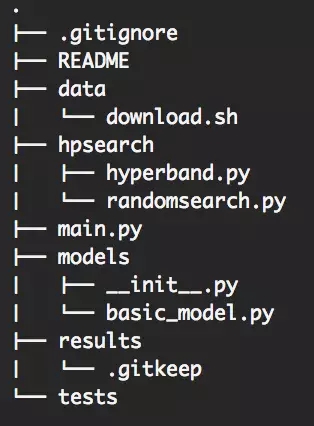
文件架构
README 文件:大部分人可能使用 Github,所以请花费些时间,写一个至少包含以下选项的好的 markdown:安装、使用、测试、有用的链接,来记录要直接放进 repository 的大型文件。
main.py 文件:独特的 endpoint,简单。下面会有更详细的介绍。你也可以用两个文档做为变形(train.py/infer.py)。但在我看来不必要,它通常用来为每个文件建立两个 API。
数据文件夹:创造一个文件夹,并放进一个脚本来下载数据集。如果需要,让脚本很好地适配数据文件夹,例如:如果没有的话,脚本可以创造 trian/val/test 子文件夹。
模型文件夹:该文件夹用来放模型文件。我认为不只有一种方式可处理这个文件夹,你可以为每个模型或每个模型类别写个文件,甚至可以有一个子文件夹。只要保持一致就行。
__init__ file:下面我会对该文件介绍更多,但它是一个 python 助手(helper),能让你更容易找到模型,且简化了模型文件夹的复杂度。
basic_model.py 文件:下面也会对此有所详介。我认为 TensorFlow 中的大部分模型能共享一个通用架构,后文我会解释自己的选择以及原因。
hysearch 文件夹:该文件夹用来存放任何做自定义超参数搜索的助手。如果你使用函数库,可能就不需要它,但大多时候你总需要自定义些东西。保持这些功能的纯粹与多带带性,以便于能简单地进行测试。
测试文件夹:测试文件夹,当然是用来测试的。你会测试它们,对吧?
结果文件夹:很明显,该文件夹是用来放结果的。TensorFlow 中更多有关如何提供 TensorBorad 的子文件夹架构的信息,下面很有所介绍。
注释:请在结果文件夹中添加一个「.gitkeep」文件和为「.gitignore」文件添加一个文件夹。因为你也许不希望将所有试验都放到 Github 上,并需要避免代码在首次安装时因为文件夹丢失而中断。
这些都是十分基础的。当然,也许还需要添加其他文件夹,但那些都能归结到这一基本集中。
通过将良好的 README 和其他 bash 脚本作为辅助。任何人希望使用你的资源库(repository)都可以通过「Install」命令和「Usage」命令复制你的研究。
基本模型
正如我所说的,我最终意识到模型中的模式是通过 TF 工程化的东西。这一点引领着我我设计了一个非常简单的类(class),其可以由我未来的模型所扩展。
我并不是继承类别(class inheritance)的热衷者,但我也不是永远清晰复写一段相同代码的热衷者。当你在进行机器学习项目时,模型通过你使用的框架共享了许多相似之处。
所以我试图找到一个避免继承的(inheritance)已知香蕉问题(banana problem)的实现,这是通过让一个继承尽可能地深而达到。
要完全清楚,我们需要将这一类别作为以后模型的顶部父级类别(top parent),令你模型的构建在一行使用一个变元(one argument):配置(the configuration)。
为了更进一步理解,我们将为你直接展示注释文件(commented file):
import os, copy
import tensorflow as tf
class BasicAgent(object):
# To build your model, you only to pass a "configuration" which is a dictionary
def __init__(self, config):
# I like to keep the best HP found so far inside the model itself
# This is a mechanism to load the best HP and override the configuration
if config["best"]:
config.update(self.get_best_config(config["env_name"]))
# I make a `deepcopy` of the configuration before using it
# to avoid any potential mutation when I iterate asynchronously over configurations
self.config = copy.deepcopy(config)
if config["debug"]: # This is a personal check i like to do
print("config", self.config)
# When working with NN, one usually initialize randomly
# and you want to be able to reproduce your initialization so make sure
# you store the random seed and actually use it in your TF graph (tf.set_random_seed() for example)
self.random_seed = self.config["random_seed"]
# All models share some basics hyper parameters, this is the section where we
# copy them into the model
self.result_dir = self.config["result_dir"]
self.max_iter = self.config["max_iter"]
self.lr = self.config["lr"]
self.nb_units = self.config["nb_units"]
# etc.
# Now the child Model needs some custom parameters, to avoid any
# inheritance hell with the __init__ function, the model
# will override this function completely
self.set_agent_props()
# Again, child Model should provide its own build_grap function
self.graph = self.build_graph(tf.Graph())
# Any operations that should be in the graph but are common to all models
# can be added this way, here
with self.graph.as_default():
self.saver = tf.train.Saver(
max_to_keep=50,
)
# Add all the other common code for the initialization here
gpu_options = tf.GPUOptions(allow_growth=True)
sessConfig = tf.ConfigProto(gpu_options=gpu_options)
self.sess = tf.Session(config=sessConfig, graph=self.graph)
self.sw = tf.summary.FileWriter(self.result_dir, self.sess.graph)
# This function is not always common to all models, that"s why it"s again
# separated from the __init__ one
self.init()
# At the end of this function, you want your model to be ready!
def set_agent_props(self):
# This function is here to be overriden completely.
# When you look at your model, you want to know exactly which custom options it needs.
pass
def get_best_config(self):
# This function is here to be overriden completely.
# It returns a dictionary used to update the initial configuration (see __init__)
return {}
@staticmethod
def get_random_config(fixed_params={}):
# Why static? Because you want to be able to pass this function to other processes
# so they can independently generate random configuration of the current model
raise Exception("The get_random_config function must be overriden by the agent")
def build_graph(self, graph):
raise Exception("The build_graph function must be overriden by the agent")
def infer(self):
raise Exception("The infer function must be overriden by the agent")
def learn_from_epoch(self):
# I like to separate the function to train per epoch and the function to train globally
raise Exception("The learn_from_epoch function must be overriden by the agent")
def train(self, save_every=1):
# This function is usually common to all your models, Here is an example:
for epoch_id in range(0, self.max_iter):
self.learn_from_epoch()
# If you don"t want to save during training, you can just pass a negative number
if save_every > 0 and epoch_id % save_every == 0:
self.save()
def save(self):
# This function is usually common to all your models, Here is an example:
global_step_t = tf.train.get_global_step(self.graph)
global_step, episode_id = self.sess.run([global_step_t, self.episode_id])
if self.config["debug"]:
print("Saving to %s with global_step %d" % (self.result_dir, global_step))
self.saver.save(self.sess, self.result_dir + "/agent-ep_" + str(episode_id), global_step)
# I always keep the configuration that
if not os.path.isfile(self.result_dir + "/config.json"):
config = self.config
if "phi" in config:
del config["phi"]
with open(self.result_dir + "/config.json", "w") as f:
json.dump(self.config, f)
def init(self):
# This function is usually common to all your models
# but making separate than the __init__ function allows it to be overidden cleanly
# this is an example of such a function
checkpoint = tf.train.get_checkpoint_state(self.result_dir)
if checkpoint is None:
self.sess.run(self.init_op)
else:
if self.config["debug"]:
print("Loading the model from folder: %s" % self.result_dir)
self.saver.restore(self.sess, checkpoint.model_checkpoint_path)
def infer(self):
# This function is usually common to all your models
pass
基本模型文件
一些注释:
关于我配置的「较佳」属性:人们通常在没有模型最优超参数的情况下传送代码,有人知道为什么吗?
随机函数是静态的,因为你不想实例化(instantiate)你的模型以访问它,但为什么要将其添加到模型本身呢?因为它通常与模型自定义参数绑定。注意,这个函数必须是纯粹的(pure),这样才能根据需要复杂化。
示例 init 函数是最简单的版本,它会加载现存文件夹或(如果 result_dir 为空)使用 init_op 随机初始化。
The __init__ script
你能在文件夹结构看到初始化脚本(The __init__ script),其和机器学习并没有什么关联。但该脚本是令你的代码对你或其他人更加易读的简单方式。
该脚本通过添加几行代码令任何模型类别都能从命名空间 models 直接可读取:所以你能在代码任一处输入:from models import MyModel,该代码行能导入模型而不用管模型的文件夹路径有多么深。
这里有一个脚本案例来实现这一任务:
from models.basic_model import BasicModel
from agents.other_model import SomeOtherModel
__all__ = [
"BasicModel",
"SomeOtherModel"
]
def make_model(config, env):
if config["model_name"] in __all__:
return globals()[config["model_name"]](config, env)
else:
raise Exception("The model name %s does not exist" % config["model_name"])
def get_model_class(config):
if config["model_name"] in __all__:
return globals()[config["model_name"]]
else:
raise Exception("The model name %s does not exist" % config["model_name"])
这并没有多高端,但我发现这一脚本十分有用,所以我把它加到本文中了。
API 外壳(The shell API)
我们有一个全局一致的文件夹架构和一个很好的基础类别来构建我们的模型,一个好的 python 脚本很容易加载我们的类(class),但是设计「shell API」,特别是其默认值是同样重要的。
因为与机器学习研究交互的主要结束点就是你使用任何工具的外壳(shell),程序外壳是你实验的基石。
你想要做的最后一件事就是调整你代码中的硬编码值来迭代这些实验,所以你需要从外壳中直接访问所有的超参数。同样你还需要访问所有其他参数,就像结果索引或 stage (HP search/Training/inferring) 等那样。
同样为了更进一步理解,我们将为你直接展示注释文件(commented file):
import os, json
import tensorflow as tf
# See the __init__ script in the models folder
# `make_models` is a helper function to load any models you have
from models import make_models
from hpsearch import hyperband, randomsearch
# I personally always like to make my paths absolute
# to be independent from where the python binary is called
dir = os.path.dirname(os.path.realpath(__file__))
# I won"t dig into TF interaction with the shell, feel free to explore the documentation
flags = tf.app.flags
# Hyper-parameters search configuration
flags.DEFINE_boolean("fullsearch", False, "Perform a full search of hyperparameter space ex:(hyperband -> lr search -> hyperband with best lr)")
flags.DEFINE_boolean("dry_run", False, "Perform a dry_run (testing purpose)")
flags.DEFINE_integer("nb_process", 4, "Number of parallel process to perform a HP search")
# fixed_params is a trick I use to be able to fix some parameters inside the model random function
# For example, one might want to explore different models fixing the learning rate, see the basic_model get_random_config function
flags.DEFINE_string("fixed_params", "{}", "JSON inputs to fix some params in a HP search, ex: "{"lr": 0.001}"")
# Agent configuration
flags.DEFINE_string("model_name", "DQNAgent", "Unique name of the model")
flags.DEFINE_boolean("best", False, "Force to use the best known configuration")
flags.DEFINE_float("initial_mean", 0., "Initial mean for NN")
flags.DEFINE_float("initial_stddev", 1e-2, "Initial standard deviation for NN")
flags.DEFINE_float("lr", 1e-3, "The learning rate of SGD")
flags.DEFINE_float("nb_units", 20, "Number of hidden units in Deep learning agents")
# Environment configuration
flags.DEFINE_boolean("debug", False, "Debug mode")
flags.DEFINE_integer("max_iter", 2000, "Number of training step")
flags.DEFINE_boolean("infer", False, "Load an agent for playing")
# This is very important for TensorBoard
# each model will end up in its own unique folder using time module
# Obviously one can also choose to name the output folder
flags.DEFINE_string("result_dir", dir + "/results/" + flags.FLAGS.model_name + "/" + str(int(time.time())), "Name of the directory to store/log the model (if it exists, the model will be loaded from it)")
# Another important point, you must provide an access to the random seed
# to be able to fully reproduce an experiment
flags.DEFINE_integer("random_seed", random.randint(0, sys.maxsize), "Value of random seed")
def main(_):
config = flags.FLAGS.__flags.copy()
# fixed_params must be a string to be passed in the shell, let"s use JSON
config["fixed_params"] = json.loads(config["fixed_params"])
if config["fullsearch"]:
# Some code for HP search ...
else:
model = make_model(config)
if config["infer"]:
# Some code for inference ...
else:
# Some code for training ...
if __name__ == "__main__":
tf.app.run()
以上就是本文想要描述的,我们希望它能帮助新入门者辅助研究,我们同样也欢迎自由评论或提问。
原文链接:https://blog.metaflow.fr/tensorflow-a-proposal-of-good-practices-for-files-folders-and-models-architecture-f23171501ae3
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4540.html
摘要:年月日,机器之心曾经推出文章为你的深度学习任务挑选最合适从性能到价格的全方位指南。如果你想要学习深度学习,这也具有心理上的重要性。如果你想快速学习深度学习,多个廉价的也很好。目前还没有适合显卡的深度学习库所以,只能选择英伟达了。 文章作者 Tim Dettmers 系瑞士卢加诺大学信息学硕士,热衷于开发自己的 GPU 集群和算法来加速深度学习。这篇博文最早版本发布于 2014 年 8 月,之...
摘要:本报告面向的读者是想要进入机器学习领域的学生和正在寻找新框架的专家。其输入需要重塑为包含个元素的一维向量以满足神经网络。卷积神经网络目前代表着用于图像分类任务的较先进算法,并构成了深度学习中的主要架构。 初学者在学习神经网络的时候往往会有不知道从何处入手的困难,甚至可能不知道选择什么工具入手才合适。近日,来自意大利的四位研究者发布了一篇题为《神经网络初学者:在 MATLAB、Torch 和 ...

阅读 2630·2021-11-22 09:34
阅读 3228·2021-10-25 09:43
阅读 2142·2021-10-11 10:59
阅读 3607·2021-09-22 15:13
阅读 2481·2021-09-04 16:40
阅读 554·2019-08-30 15:53
阅读 3339·2019-08-30 11:13
阅读 2765·2019-08-29 17:30