
摘要:于年在意大利北部帕维亚的监狱中死亡。的死亡促使了现代犯罪学的诞生。写道,犯罪分子生下来就是罪犯。最近的一个例子便是,上海交通大学和在年月传到上的论文使用脸部图像自动推断罪犯。
任何关心如何确保 AI 技术朝着有利于人类发展的人都是本文的读者
1844 年,意大利南部一个小城镇举办了一场审判会,一个名叫 Giuseppe Villella 的劳工因涉嫌窃取了“5 个里考塔(注释:意大利奶制品,类似凝乳),一块硬奶酪,两块面包……和两只小山羊”,最终被判定为“brigante”(暴匪)。当时,意大利南部正因盗匪和国家暴动陷入恐慌。Villella 于 1864 年在意大利北部帕维亚的监狱中死亡。
Villella 的死亡促使了现代犯罪学的诞生。当时镇里居住的一位名叫 Cesare Lombroso 的科学家和外科医生,他认为“brigante”是一种原始的人,天生容易犯罪。检查 Villella 的遗体后,Lombroso 发现了所谓的“证据”,证实了他的猜想:Villella 头骨枕头上的凹陷让人联想到“野人和猿猴”的头骨特征。
使用较精确的测量仪器,Lombroso 记录下了他在 Villella 遗体上发现的更多显示其有精神错乱(derangement)的物理特征,包括“不对称的脸”。Lombroso 写道,犯罪分子“生下来就是罪犯”。他认为犯罪行为是会遗传的,并且在遗传时会带有伴随的物理特征,可以用卡钳和颅骨等仪器来测量[1]。这个想法很自然地证明了他之前的假设,即意大利南部人种相比北意大利人要落后原始许多。
使用人的外观推断其内在特征的做法被称为相面(physiognomy)。虽然在今天相面被认为是伪科学,但在民间一直流传着,可以从某个人的面部和身体特征识别出较差的“类型”的人,这一观点也在不同时期被编入国家法律,为很多行为提供了基础,比如购买土地、禁止移民、证明奴隶制合理,以及将种族灭绝正当化。在实践中,相面的伪科学成为科学种族主义(scientific racism)的伪科学。
人工智能和机器学习的快速发展使科学种族主义进入了一个新的时代。其中,人类行为中存在的偏见也被带入了机器学习模型的开发过程中。无论是有意还是无意,这种通过计算机算法对人类偏见的“洗白”可能会使这些偏见看来是客观的。
最近的一个例子便是,上海交通大学 Xiaolin Wu 和 Xi Zhang 在 2016 年 11 月传到 arXiv 上的论文《使用脸部图像自动推断罪犯》(Automated Inference on Criminality Using Face Images)。吴和张认为,机器学习技术可以预测一个人是否是犯罪分子(不是犯罪嫌疑人),号称准确度几乎 90%,而他们使用的数据仅仅是类似美国驾驶执照上人脸的证件照。虽然该论文没有经过同行评议,但其调查结果激发了一系列新闻报道。[2]
研究界的许多人都认为吴和张的分析在道德和科学上都是有问题的。在某种意义上,这不是什么新鲜事。然而,使用现代机器学习方法(性能强大,但对很多人来说也是神秘的),可以使这些过去的说法看上去有了新的可信度。
在摄像机和大数据无所不在的时代,机器学习相面也可以前所未有的规模得到应用。鉴于社会越来越多地依赖机器学习实现常规认知任务的自动化,开发人员、评论家和用户都迫切需要了解人工智能技术的局限和相面这一伪科学的历史,更何况后者如今还披上了一层和现代技术的外衣。
因此,我们在这里面向广泛的受众撰写了这篇深度文章:不仅对研究人员、工程师、记者和政策制定者,任何关心如何确保 AI 技术朝着有利于人类发展的人都是本文的读者。
接下来,我们将首先回顾机器学习技术的底层运作方式,然后讨论机器学习将如何延续人类的偏见。
如何用机器学习了解图像
计算机可以根据某个人的图片进行计算来分析这个人的身体特征。这是很普通的一个图像问题:计算机程序分析照片、根据照片做出一些决定,然后得出某些有意义的判断(比如说,“这张照片中的人很可能在 18 岁和 23 岁之间”)。
照片和计算机反馈之间的关系由一组参数确定,这些参数会在机器学习的阶段进行调整,这就是“机器学习”的由来。机器学习最常见的方法是监督学习,会使用大量带标记的样本工作,也就是样本图像与每个理想输出都进行配对。当参数设置为随机值时,机器只能纯粹凭运气作出回答;但即使给出了一个随机的起点,人可以慢慢地调整一个或多个参数,并问“这种变化是更好还是更差?”这样,计算机就能自我优化,学习任务。通常的训练项目会涉及数百万、数十亿或数万亿的参数选择,计算机在这个过程中稳步提高完成任务的性能。最终,计算机提高的水平放缓并趋于平稳,根据给定任务的固有困难程度以及机器和数据的局限性,预测准确性可能已经达到了较佳状态。
训练时,要避免的一个情况是过拟合(overfitting)。过拟合就是机器能够记住个别训练样本的正确答案,但不能进行泛化,泛化则是适用于不同的数据。避免过拟合最简单的方法是在验证系统时,使用没有在训练中出现过标记数据集。如果系统在验证时性能和训练时大致相同,那么就可以确信系统真的学会了如何发现数据中的一般模式,而不仅仅是记住了训练样本。这实际上和让学生考试的理由相同,测验时考的都是以前没有见过的问题,而不仅仅是重复在课堂上学到的例子。
每个机器学习系统都有参数——否则就没什么可学习的了。简单的系统可能只有比较少的参数。增加参数数量可以让系统学会更复杂的关系,成为更强大的学习者,输入输出间的关系越复杂,系统错误率就越低。另一方面,更多的参数也让系统能够记住更多的训练数据,因而也更容易产生过拟合。这意味着在参数数量和所需的训练数据的数量之间有一个关系。
现代的复杂的机器学习技术,如卷积神经网络(CNN)有数百万个参数,因此需要大量的训练数据避免发生过拟合。获得足够多带标签的数据来训练和测试系统,通常是机器学习研究者面临的较大的实际挑战。
示例:确定照片拍摄时间
卷积神经网络应用十分广泛,性能也非常强大。例如,Ilya Kostrikov 和 Tobias Weyand 提出的 ChronoNet,这个 CNN 可以猜测拍摄照片的年份。他们使用的数据是在过去 100 年间拍摄已知的日期的照片,这些照片都带了某种程度的标签(在这种情况下为日期照片),因此获取标记数据用于训练这个网络相对来说比较简单。
一旦网络被训练好,就可以输入照片,可以看出系统猜测拍摄的那一年。 例如,以下两张照片都是 ChronoNet 猜测1951(左)和1971(右):

图2 深度学习猜测拍摄年份的照片
这些都是很好的猜测。左边的照片在 1950 年在斯德哥尔摩海滨拍摄的,右边的照片则是 1972 年尼克松在亚特兰大州发表竞选演说,旁边是尼克森夫人。
神经网络究竟是如何计算出来的?从机械学的角度来看,数百万个学习参数只是一系列加权平均计算中使用的权重。从原始像素值开始,加权平均值被组合,然后用作相似的计算集合的输入,然后又被用作另一个类似的计算集合的输入,等等——在多层网络中创建一个级联的加权平均计算。[3] 在 ChronoNet 中,最后一层的输出对应的是照片拍摄可能年份的概率值。虽然在技术上是正确的,但这个“概率”是无法解释的;让一位人类专家判断这两张照片的年代,他同样可以说:“我这样回答,是因为我的神经元就是这么连在一起的。”
事实上,像人类专家一样,人工神经网络很可能学到了发现各种细微线索,从低级属性,如胶片颗粒和色域(电影处理技术在 20 世纪得到了长足的发展)到衣服和发型,乃至车型和字体。上面那张斯德哥尔摩照片中的扬声器和婴儿车的风格也可能是线索。自 2006 年以来,所谓的深度学习进一步加快了人工智能的快速发展,与任务(颜色、汽车模型等)相关的特征可以被隐含地学习,为更高层次的目标(比如猜测照片拍摄年代)服务。[4]
以前的机器学习方法也可能已经达到了猜测照片拍摄年代的高级目标,但是需要手工编写计算机代码,从原始图像中提取字体和发型等特征。让计算机能够端到端的学习一个复杂的问题,省去了编码这样的定制工作,大大加快了开发速度,也经常大幅地提高了结果的准确率。
这既机器学习的力量也是这种方法的危险,特别是深度学习。深度学习的力量我们是清楚的:一般的方法可以发现各种不同问题中的隐含关系;系统本身会去寻找去学习的内容。而深度学习的危险则来自于一个科学家或工程师可以轻松地设计一个分类任务,让机器在不了解任务实际测量的内容,或者系统实际发现的模式的前提下,进行很好的学习。这种情况下,机器“如何”或“为什么”做出判断就变得很重要了,尤其是涉及到判断一个人的性格或犯罪情况时。
论文摘要
我们首次进行基于静止的人脸图像自动推测犯罪性的研究。通过有监督机器学习,我们使用 1856 张真实的人的面部照片建四个分类器(逻辑回归,KNN,SVM,CNN),这些人中有近一半是已被定罪的犯罪者,其余是非犯罪者,我们以民族、性别、年龄和面部表情作为控制要素,让计算机区分犯罪者和非犯罪者。四个分类器都表现良好,为根据脸部特征自动预测犯罪性提供了有效性证据,尽管围绕该主题存在历史性争议。此外,我们发现一些可以预测犯罪性的结构上的区别特征,例如嘴角的弧度、眼内角间宽、以及所谓的鼻唇角角度。这项研究最重要的发现是,犯罪者和非犯罪者的面部照片在表情的多样性方面非常不同。犯罪者的面部表情变化明显大于非犯罪者。由两组照片组成的两个流形看起来是同心的,非犯罪者的流形的跨度较小,表现出正常的规律。换句话说,一般守法公民的面貌与犯罪者的面貌相比具有更大程度上的相似性,也就是说,犯罪分子在面部表情上的差异比普通人更大。
通过机器学习来推断一个人是否是“犯罪分子”?
《使用脸部图像自动推理罪犯》要做的,也是 ChronoNet 类似的事情,除了后者是推测任意照片拍摄的年代,而前者则是根据人脸部图像推测一个人是否有犯罪记录。因此,吴和张在论文中写道,这是首次“为自动根据人脸推理罪犯提供了证据”。
为了说明为什么这种说法有问题,接下来我们将更详细地解说其研究方法和结果。
方法和结果
吴和张的数据集是中国政府颁发的身份证照片,一组含有 1,856 张 80x80 像素的中国男性面孔近照(closely cropped)。这些男性年龄介于 18 至 55 岁之间,图像中没有面部毛发,也没有疤痕或其他明显痕迹。图像中的 730 个人被标记为“罪犯”,或者更确切地说,
“……其中 330 人是中国公安部和广东省、江苏省、辽宁省等公安部门公布的犯罪嫌疑人;其他则是由中国一个城市警察部门根据保密协议提供。……在 730 名罪犯中,235 人犯有包括谋杀、强奸、殴打、绑架和抢劫等暴力罪行;其余 536 人被定罪为非法暴力罪行,例如盗窃、欺诈、腐败、伪造和敲诈勒索罪。”
其他 1126 张人脸图像则是:
“使用网络爬虫从互联网获取的非犯罪分子头像,覆盖广泛的专业和社会地位,包括服务员、建筑工人、出租车和卡车司机、房地产经纪人、医生、律师和教授;……大约有一半的人拥有大学学位。”
需要特别强调的是,所有这些人脸图像都来自政府颁发的身份证——这些被视为“犯罪分子”的图片不是犯罪现场照片。
吴和张用这些带标签的样本做监督学习。他们训练计算机看一张脸像,并产生一个“是/否”的回答:这个图片上的人属于“罪犯”组还是“非犯罪分子”组?他们使用了4种不同复杂程度的机器学习技术,也就是参数数量多少不同,更复杂的技术具有更多的参数,因此能够学会图像中细微的关系。其中,一个不太复杂的技术使用自定义代码对图像进行预处理,提取特定已知面部特征的位置(如眼睛和嘴角),然后使用较旧(older)的方法学习与这些面部特征位置相关的模式。作者还使用了 AlexNet,其架构与 ChronoNet 类似。AlexNet 是最现代化的模型和参数最多的 CNN 之一,性能也十分强大,分类精度高达近 90%。不过,即使使用较老的方法,论文给出的精度也远高于 75%。
这带来了几个问题,也许第一个就是“这可能是真的吗?”更确切地说,
这些数字是否可信?
机器学习学到的是什么?
这与犯罪行为和刑事判决有什么关系?
可能的假象
要看准确率高达 90% 是个什么概念,我们来对比另外一篇论文。计算机视觉研究人员 Gil Levi 和 Tal Hassner 在一篇精心控制的 2015 年论文中发现,具有相同架构的卷积神经网络(AlexNet)在推测快照中人脸性别[5] 时的准确率只有 86.8%[6]。另外,吴和张在论文中声称基于 CNN 方法的“假阳性”(即将“非罪犯”误识别为“罪犯”的错误率)只超过 6% 一点点。新的研究显示,药物检测一般会在 5% 至 10% 的病例中产生假阳性结果,10% 至 15% 的病例中为假阴性。
我们认为论文中声称的准确度高得有些不切实际。一个技术问题是,少于 2000 个样本实际上是不足以训练和测试像 AlexNet 这样的 CNN 而不会过拟合的。论文采用较旧的非深度学习方法给出的较低的准确率(其实还是很高了)可能更为真实。
还应该注意,作者无法可靠地推断出他们从网络获取的身份证图像都是“非犯罪分子”的;如果我们假设这些人是一般人群中抽取的随机样本,根据统计学,其中一部分人也可能从事犯罪活动。
另一方面,论文中使用的数据集都是来自 18 只 55 岁的男性,这可能也有问题,因为法官在判决时可能会首先考虑排除年龄偏见。
同样,论文中所示的 3 个“非罪犯”图像(见下文)中都穿着白领衬衫,而另外 3 名被判别为“罪犯”的都没有。当然,只有 3 个例子,我们不知道这是否代表整个数据集。但是,我们知道,深度学习技术是强大的,并且能够学会所有接收到的线索,正如 ChronoNet 除了图像内容的不同之外,还提取了细节,如胶片颗粒度。
机器学习不会区分因果关系和偶然的相关性。
机器学习究竟学到了什么?
排除可能会影响论文所声称准确度的技术错误和混淆,图像中捕获的人脸外观与“罪犯”组中的成员之间可能确实存在相关性。这些被称为“罪犯”的人脸部有什么独特的特征吗?
吴和张使用了各种技巧对此作了详细的探讨。对于较为简单的机器学习方法,其中会测量标准面部标记(landmark)之间的关系,这是特别容易的。他们总结说,
“……犯罪分子从两边嘴角到鼻尖的角度 θ 平均值比非犯罪者的平均值要小19.6%,差异较大(has a larger variance)。而且,犯罪分子的上唇曲率 ρ 平均比非罪犯大 23.4%。另一方面,犯罪分子内眼角之间的距离 d 比非犯罪分子略窄(5.6%)。”[7]
关于这一点,我们可以从论文中的配图得到直观的了解。下图是论文中的图1,上面一排是“罪犯”,下面一排则是“非犯罪分子”。

上排是“罪犯”,下排是“非犯罪分子”。上排的人脸表情皱着眉头(frowning),而下排没有。深度学习系统可能会“学会”这样表面的区别。
论文作者只公开了上面这 6 个例子,这也有可能是故意挑选的。我们也做了随机调查(包括中国和西方国家的同事),如果必须在二者中选择一组,很多人也认为下面一排的 3 个人是罪犯的可能性小一些。一方面,尽管作者声称对面部表情做了控制,但是底部 3 张图像似乎都是显得在微笑的,而上排的 3 个人则似乎是皱着眉头。
如果这 6 幅图像确实是典型的样本,那么我们怀疑让一名人类法官将图像从微笑到皱眉来排个序,也可以很好地将“非罪犯”与“犯罪分子”区别开来。后面我们会阐述这一点。
人类又从中发现了什么?
值得强调的是,在这种(或任何)机器学习应用中没有超人的魔力。虽然非专家只能大概估计一张照片的拍摄年代,但大多数人[8]在识别人脸方面都非常敏感。我们能一眼就从比较远的距离认出自己熟悉的人,而且这样的人可能有成百上千个,注意到别人的凝视和表情的细微差别,并且所有这些都在十分之一秒内完成。[9]
吴和张并没有声称他们的机器学习技术在识别人脸面部细微特点(cue)方面,比不需要计算机辅助的普通人要强。不过,他们将其工作与 2011 年在心理学期刊发表的一项研究(Valla 等人,基于面部外观推断犯罪分子的准确性[The Accuracy of Inferences About Criminality Based on Facial Appearance])联系在一起,那篇论文也使用人类的判断得出了类似的结论:
“……研究人员给实验参与者展示了一组罪犯和非罪犯的头像,这些图片都控制了性别、种族、年龄、吸引力和情感表现之后,也消去了任何显示图片来源的线索,结果表明,实验参与者都能够可靠地区分这两个群体。”
虽然吴和张使用的身份证 ID 照片而不是犯罪嫌疑人照片(mugshot),我们应该注意,Valla 等人的论文(尽管他们声称已经对摄影条件做了控制),作者比较的是被定罪人的照片和在校园里拍摄的学生的照片。可以认为,被捕后身处威胁和侮辱性的环境中,那时所拍摄的照片看起来与在大学校园里拍摄的照片看上去不同,因而论文的结论也值得商榷。
吴和张也将他们的工作与 2014 年心理学期刊 Psychological Science 发表的一篇论文(Cogsdill 等人,从人脸推断性格:关于发育的研究[Inferring Character From Faces: A Developmental Study])联系起来。这篇论文的其中一位作者就是我们中的一个人。这篇论文发现,即使是 3 岁到 4 岁的孩子,也能准确地区分“善意”(nice)和“不友好”(mean)的脸部图像。但关键是,没有人声称这些这些印象与一个人的性格有关。本文研究的是在人类发育早期对人脸表情类型(facial stereotype)的识别,使用的也是将这些不同类型的表情可视化的照片。[译注:这里指实验中使用的是心理学研究中常用的代表不同表情的人脸照片。]
所谓“友善”和“不友善”的脸看起来是什么样子?过去 10 年有关人脸表情社会感知的研究表明,人对一张脸的印象可以浓缩到一些基本层面,包括强势(dominance)、吸引力(attractiveness)和价值(valence,与“值得信赖”、“外向”等积极评价有关)。科学家开发了各种方法,将这些维度上的典型面部表情可视化。其中一种是,让实验参与者评判随机合成的面孔,是否可靠(trustworthy)和强势(dominance)。由于合成的人脸是根据不同面部特征的相对大小或位置得出的统计模型,所以可以计算出代表“值得信赖”或“不可信任”的人脸的平均特征;对于白人男性,可靠与不可靠的脸分别看起来像这样:

图4. 根据儿童和成人的判断,典型的“友善”(左)和“不友善”的人脸
看起来“不值得信任”的脸与吴和张论文中“罪犯”的脸(图3)看起来相似。
客观的谬误
吴和张在论文中并没有危言耸听,将人对一张脸的印象(如“不可信赖”)和所谓的客观现实(如“罪犯”)联系起来,而是声称我们看到的右边的面部特征潜在预示(imply)犯罪行为。这种不正确的断言依赖的是推定的客观性和输入、输出自己算法之间的独立性。
因为吴和张使用的算法是基于一种高度通用的深度学习技术——卷积神经网络,后者可以从任何类型的图像数据中学习模式——这种方法可以说是客观的,也就是说,深度学习/卷积神经网络本身并不对人脸面部特征或犯罪行为带有偏见。
输入被认为是客观的,因为吴和张的论文使用的是标准化的 ID 照片。输出也被认为是客观的,因为它是一种合法的判决(legal judgement)——是独立于输入的,因为在绝大多数文献中“正义”(justice)都被认为是“看不见的”(注释:正义女神经常被造成带眼罩的形象,代表其客观、不徇私、一视同仁的平等精神)。正如作者所说,
“由人类观察者主观判断会导致偏见,而我们是首次在没有任何人为偏见的情况下,研究了根据脸部特征自动推断犯罪分子。”
在这里,论文中声称输入和输出的客观性是具有误导性的。但是,这项工作最令人不安的是,它引用了两种不同形式的权威力量——科学和法律,让人群中存在高低贵贱之分的这种说法再次复苏并且予以证明。那些上唇弧度更加弯曲,眼睛更靠近的人都处于社会较底层,容易出现(用吴和张的话说就是)“一大堆异常(不合群)的个人特征”,最终导致这些人在法律上被判定为“罪犯”的可能性很高。
这种论调与 Cesare Lombroso 的话很相似。在探索面部外观输入与刑事判决输出之间相关性的可能原因之前,我们有必要停下来,回顾这些声称的历史。
“面相学”——科学种族主义
面相学和“类型”理论[10]
“面相学”的根源在于人类倾向于相关地、隐喻地、甚至是诗意地解释一个人的外表。这种想法至少可以追溯到古希腊人[11],在文艺复兴时期的多米尼加·詹巴蒂斯塔·德拉·波塔的“人类生理学”(De humanaphysiognomonia)中尤其明显,书中展示:一个长得像猪的人就像猪一样[12]:

图5. 一半像男人,一半像公猪:摘自 Giambattista dellaPorta 的 De humanaphysiognomonia(那不勒斯,1586)
要在启蒙运动中理解这样的想法,有必要从中去除诗意的成分,集中精力在更具体的身体和行为特征上。在十七世纪,瑞士神学家约翰·卡斯帕拉夫特(Johann CasparLavater)基于眼睛、眉毛、嘴巴和鼻子的形状和位置来分析人的性格,以确定一个人是否具有“欺骗性”、“充满恶意”、“愚蠢”、还是”疯狂“。
在这种情况下,维多利亚时代的博学家弗朗西斯·加尔顿(Francis Galton,1822-1911)试图通过将犯罪分子的人像曝光叠加在同一张底板上来实证地表征“犯罪”类型。大约在同一时间,Lombroso 采取了更为“科学”的犯罪学方法进一步进行了现实的测量。[13]虽然Lombroso 可以被认为是第一个试图系统研究犯罪行为的人之一,但他也可以被认为是第一个使用现代科学来对定义“矮化”的“人类类型”的人之一。

图6.弗朗西斯·加尔顿(Francis Galton)试图重建“通用犯罪分子”的肖像。
严谨的科学方法凭借时间、同行评议和迭代来去除错误假设; 但使用科学语言和方法并不能阻止研究人员进行有缺陷的实验,并提出错误的结论——特别是当他们先入为主时。这种认识与种族主义本身一样古老。
1850——1950年的科学种族主义
Lombroso 的信仰伴随着对意大利的“南方人”的尊重,隐含着一种带有政治色彩的种族等级观念。但是19 世纪的美国面相学家们更加注重合理化这个等级:他们是奴隶主。塞缪尔·莫顿(Samuel Morton)用颅骨的测量和民族学的论据来表达白人至上的地位; 正如他的追随者Josiah Nott和George Gliddon 在他们《1854 年的人类类型》中引用的:
“智慧,有活力,有野心,进步,解剖学上更为高级,这是一些种族的特点; 愚蠢,懒惰,低活动能力,野蛮,解剖学更为低等,是另一些种族的特点。在所有情况下,崇高的文明都是由“白种人”团体完成的。”
尽管这本书以学术论著自居了几个世纪,它显示出等同于德拉·波塔的论文中显而易见的面部特征推理和动物类比,尽管在现代语境下,更具侵略性:

图7.人类的劣势类型的观念和一些人比其他人更像动物这样科学上无效的想法相关。来自Nott 和Gliddon,《1854年的人类类型》。
在19世纪后期,达尔文进化理论反驳了人类类型的认识,即所谓种族是如此不同,它们必须由上帝独立创造。然而,通过明确说明人类实际上是动物,而且与其他猿类有着密切的关系,它为莫顿离散的种族等级“学说”提供了肥沃的土壤,这一学说区分出“更人性化”的人(在身体、智力和行为方面更为进化)和“少人性”(进化不足,身体上更接近其他猿,不那么聪明,不太“文明”)。 [14] 达尔文在他的1871年的《人类的由来》中写道:
“[...]人的身体结构清楚地体现出从某种低级形式的演变轨迹; 或者是一个野蛮人和现代人之间的道德和智力方面的差异。比如由老导航员拜伦描绘的男人,他们把孩子摔在岩石上,就因为孩子弄掉了一篮子海胆;你也想象不出野蛮人会像牛顿或者莎士比亚那样使用抽象术语。较高种族和较低种族的野人之间的这种差异是渐变的。“
不足为奇,达尔文认为人性的高峰体现在物理学家艾萨克·牛顿、剧作家威廉·莎士比亚、废奴主义者托马斯·克拉克森、慈善家约翰·霍华德等人身上,他们都是英国人,基督教徒,白人,男性,受过良好教育——也就是说,像达尔文本人。达尔文的观点(在某些方面比他同时代人的更进步)充分表现出普遍的认知偏见——人们喜欢与自己相似的人。
基于可遗传的身体和行为特征的同质性,以及种族等级结构的合理化,“类型”理论一直存在到20世纪。等级的细节取决于理论家的信念和同情度。对于德国进化生物学家恩斯特·海克尔(Ernst Haeckel,1834-1919)来说,犹太人与德国人和英国人共处在高等级别,[15]但在纳粹时代,犹太人已经被诋毁,就像Haeckel 和他的先驱们,为“巴布亚人”、“Hottentots”和其他与他们没有社会关系的外国人分等级一样。例如,1938 年的儿童读物Der Giftpilz(The Toadstool)被用作学校教科书,上面说:
“正如通常很难区分可食用的蘑菇和毒蘑菇,一般很难认识到犹太人是骗子和罪犯[...]如何区分犹太人:犹太人的鼻子弯曲,看起来像数字 6 [...]“。
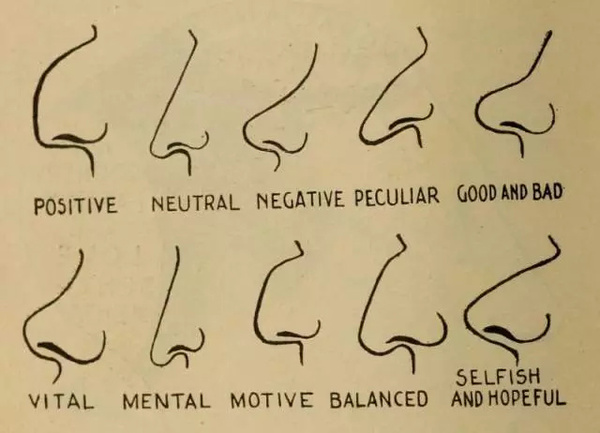
图8.Vaught 《实用性格判定》,1902年,第80页。
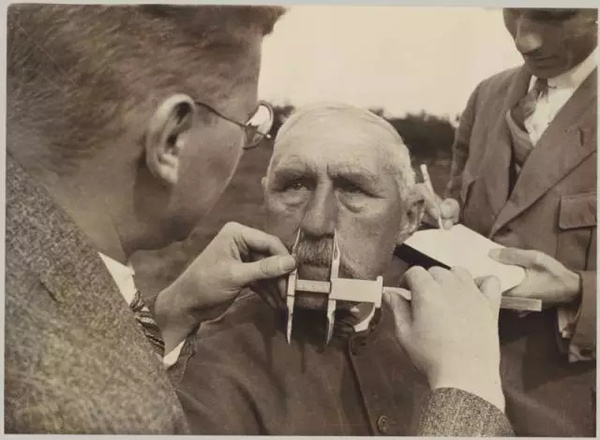
图9 .纳粹“种族科学家”正在做容貌测量,1933年。
今天的科学种族主义
尽管半个世纪来社会和科学一直在进步,但科学种族主义与过去相比并不像人们想的那样已经衰落了。例如,现在的美国“把妹达人”和白人种族主义者詹姆斯·韦德曼(James Weidmann)已经发表了支持面相学的博客:
“有证据表明,一个人的外表能说明他的政治派别、智慧、个性甚至是他的犯罪倾向。样貌类型不会凭空出现。有经验表明,人们通过脸部线条来衡量一个人(或一个女人)的历史是有道理的。 [...]就像你可以通过封面来判断一本书:丑陋的人更容易犯罪。[...]面相学是合理的。它需要作为科学研究的合法领域重新被提出来[...]“。
Wu 和 Zhang 的论文做的也正是这件事情:虽然他们并没有直接提出基于深度学习的面相学,但他们对自己的研究对于“社会心理学、管理学与犯罪学”的影响感到兴奋。
以色列创业公司Faception 已经采取了合乎逻辑的下一步,尽管他们尚未公布任何有关其方法,训练数据来源或量化结果的细节:
“Faception首先推出专有的计算机视觉和机器学习技术,用于对人员进行分析,并仅基于他们的面部特征来揭示他们的个性,这在技术和市场两方面都是首创。”
Faception 团队并不羞于推广其技术应用,提供了专门的引擎,从脸部图像中识别“高智商”、“白领罪犯”、“恋童癖者”和“恐怖主义者”。 [16]他们的主要目标是国土安全和公共安全。Faception 认为政府再次热衷于“通过封面判断一本书”。
“‘犯罪类型’在人脸上显而易见的认识,可能取决于几个有缺陷的假设:
也许不足为奇的是,Wu 和 Zhang 作为灵感引用的目前研究人员对面孔社会认知的研究,倾向于对他们正在研究的现象进行更细微的观察。一方面,这项研究表明,人们可以在观看面孔不到十分之一秒之后形成人脸印象,例如面部表情的可信度,这些印象预测了一系列重要的社会成果,从政治选举到经济交易到法律决定。另一方面,虽然我们的印象几乎反映出了脸部外观的特征,但并不意味着这些印象是准确的。证据表明它们并不准确。
从根本上说,“‘犯罪类型’在人脸上显而易见的认识,可能取决于几个有缺陷的假设:
一个人的脸部外观纯粹是天生的;
“犯罪”是某一群人的天然属性;
法律制度下刑事判决定罪不受面部外观影响。
我们依次检验每个假设。
从面部读出个性
面部结构不是纯天生的,而是受成长、[17]环境的强大影响。人脸的照片同时取决于摄影过程中的设定。所有这些附加因素都会在人脸的感知中发挥重要作用——这些都不容忽视。
Dorothea Lange 着名的大萧条时代的照片,如1936年的“移居的母亲”系列作品,以困难的环境对人类身体和情感的塑造为主题。他们可以被看作是 Dust Bowl 本身的肖像,折射出那些不幸生活在30 年代美国草原上的人们的面孔。在这样的图像中,问问观众,“在不同情况下,在另一个时间和地点,这个人看起来会是什么样的?”额头严峻,面部肌肉重新配置了焦虑和绝望的表情; “上唇曲率”都很大。在这个意义上,兰格的照片几乎可以被看作是对面相学的批判。

图 10.来自 Dorothea Lange 的“移居的母亲”系列。原来的标题是:“ 一个32岁的、7个孩子的母亲。1936年二月。”
当然,兰格的照片也是艺术声明,反映了她对“Dust Bowl”及其人民的看法。我们必须谨慎,假设这样的肖像可以被看作是其主题的“纯粹”表现形式。
研究表明,摄影师的先入之见和拍摄照片的背景与面孔本身一样重要; 同一人的不同图像可能导致广泛不同的印象。找到一对年龄、种族和性别相匹配的两个人的图像,使得其中一个人看起来更可信或更有吸引力,而另一个人在不同图像中显得更值得信赖或更具吸引力,这本身并不难。考虑一下这个例子:来自Mike Burton 及其同事在Cognition 杂志上的一篇论文(2011年):

图10. R.Jenkins 等人在2011年论文中举例说明,同一张脸在照片中发生了变化。
大多数人会认为顶部左侧的脸部比右侧的脸部更有吸引力。大多数人也看到底部左侧的脸比右侧的脸吸引力小。然而,左边的两个脸是同一个人的不同图像; 右边的两个脸也是如此。
在最近的非正式实验中,澳大利亚佳能实验室邀请了五位专业摄影师与同一个人共处几分钟,并“记录”其精髓。每个摄影师都被告知有关该人的虚假信息,而这些虚假信息导致了截然不同的照片。“白手起家的百万富翁”正看向未来,而“前犯人”似乎充满了犹豫和怀疑。标准照片(如政府ID 中使用的照片)比澳大利亚Canon Lab 的照片更平均更中立。但这一实验没有经过仔细控制——与和摄影师相关的设定上的不确定偏差将显示在数据中——因为他们可能在Valla 等人2011 年的论文中(《基于面部外观的进行犯罪推论的准确性》)将犯罪案件与在大学校园拍摄的照片进行比对。
过度概括
人与自己形象之间有完美的对应关系的想法是由我们熟悉的面孔经验所推动的心理幻觉。我们能立即识别熟悉的人的图像,这一识别唤起了我们对他们的回忆和感受。但是,当我们看陌生人的图像时,没有对应的过程。每个图像产生了不同的和任意的印象。
这部分是因为很难完全抛开情感因素去识别面孔——即使简单的印象,如一个人是微笑还是皱眉,也会影响到人的判断。所谓情绪中性面孔产生的许多印象可以通过他们的“中性”表达与情感表达的相似性来预测。
考虑到前面展示的“值得信赖”和“不可信”的面孔,我们可以看到,值得信赖的面孔比不可信任的面孔有更多的积极表现,而且更具女性气质。也就是说,可信度的印象是基于与瞬间情感表达的相似程度,这体现了行为意图以及性别观念。这些人物留下的印象被理解为对现在这个人的可能意图的过度概括。换句话说,意图可以通过将脸部的变化来传达,但不同的人脸会有不同的偏移,并会覆盖同一个空间的不同色域——因此,我们阅读意图的能力会导致过度和错误投射某些人情绪或意图。可以推测,在快照中,这种效果可能会特别明显。因为在该快照中,观看者无法测量上下文或看到更多的表情变化。
本质主义
这种面部过度概括是本质主义的一个例证,(不正确的)想法是,人们有一个不可改变的核心或本质,完全决定了其外表和行为。这些是Lavater、Lombroso 和Galton 的信仰——他们痴迷于优生学。而在现代,基因经常起到了本质的作用。在早期阶段,基因具有哲学甚至神秘的特征。
本质主义似乎常常使人类的思想变色。正如斯蒂芬·杰伊·古尔德(Stephen Jay Gould)在1981年的“人类误区”一书中所说:
“柏拉图的精神根深蒂固。我们无法摆脱哲学传统,我们在世界上可以看到和衡量的仅仅是一个基本现实的外表和不完美的代表。 [...]相关技术特别受到这种滥用的影响,因为它似乎为推断因果关系提供了一条路径(有时确实是这样,但也仅仅是有时)。
本质主义者的推理通常是循环的。例如,在19 世纪的英国,妇女通常被认为基本上不能理解抽象的数学思想。这被用作禁止她们学习高等数学的理由。当然,如果没有高等教育机会,维多利亚时期的女性就难以突破这个周期。但没有证据显示,女性无法学习高等数学。即使在一切可能的情况下,一个女人成功上升到金字塔顶端,正如菲利普·菲切特(Philippa Fawcett)在1890年历史悠久的剑桥数学竞赛考试中获得顶尖成绩一样,这会被认为是一个奇怪的结果,而没有人会认为是假设存在缺陷。 [18]虽然在过去一个世纪,我们看到了更多的一流女性数学家的例子,但我们仍然在这种确认偏见和性别本质主义的遗产中挣扎。
罪犯真的是一种“类型”吗?
我们已经看到,面部外观受到本质(遗传学)和非本质(环境、情境)因素的影响。犯罪怎么样?罪犯真的是一种“类型”吗?
“犯罪阶级”
如同面相学一样,“犯罪类型”或“犯罪阶级”这个观念在十九世纪极为流行。历史学家和文化评论家罗伯特·休斯(Robert Hughes)在他的书“致命之岸”(The Fatal Shore)中,丰富多彩地叙述了英国80 年的实验,当时英国将罪犯移往澳大利亚。他从殖民地艺术的角度描述:
“转移罪犯没那么”残酷“,因为罪犯是”一个野蛮人“,其犯罪本性就刻在他的身上。
向澳大利亚移送英国罪犯旨在英国减少犯罪——尽管没有迹象表明这是有效的。这样做是为了给澳大利亚带来“罪犯污点”,并使本质主义的焦虑传承下去的本质主义焦虑,造成永久的充斥犯罪和残酷的社会。
然而,“[...]定罪制度的真正持久遗产不是”犯罪“,而是对它的反对:向善的意志、升华和消灭罪犯污点的愿望,即使付出历史健忘症的代价[...] “[19]
也许不言而喻,“罪犯阶级”的思想在社会阶层的观念上是非常有限的。在实践中,绝大多数被运送的罪犯都是穷人,他们的许多罪行——就像任何一个时代——都是贫穷所致。他们的“犯罪”原来是环境所致的,而非本质的。就像克里斯托夫·利希滕贝格(Georg ChristophLichtenberg)——负责揭开 Lavater’s“科学”的人所说:
“你希望从面孔的相似性,特别是固定的特征来得出什么结论。如果一个上了绞刑架的人,在各个阶段各个方面都得到的是桂冠而非绞索呢?机会不单造就了罪犯,也同样早就了伟人。“。
那么,我们可以就任何一个人“内在的”犯罪类型而提出任何学说吗?
睾酮
性别是一个入手的好地方:从经验上讲,暴力犯罪的人往往是男性。较高的睾酮水平可能是一个因素,因为它似乎增加了侵略性和对风险的偏好,而且它增加了体力。 [20]这些发现甚至在一系列非人类动物中被印证。
虽然睾丸激素可能不是严格的“本质”——血液浓度可以根据情况而变化,并且可以在药学上被操纵。还有证据表明,产前睾酮水平和对睾丸激素的反应性影响身体了的发育,包括食指和无名指的长度比,以及行为的一些方面,也包括侵略性。这意味着有一些变量影响了身体和行为; 现代的面相学支持者总是指责这项工作来保卫自己的立场。
然而,这些论文中描述的各种相关性远远不够强大,不足以在实验室测试中得到证明:
“在成对的天然或合成面孔中,睾酮较高的脸部分别被认为更为具有男性气质(53%和57%)。作者认为,只有具有非常高或非常低水平的睾丸激素的男性,在男性气质方面可以视觉上区分开来。 [...]其他研究发现睾酮和男性气质之间没有联系。 [...]同样,Neave,Laing,Fink和Manning(2003)报道了感觉到的脸部男性气质的联系具有二到四位数比(2D:4D),但与测得的基准睾酮水平无关; Ferdenzi,Lemaître,Leongómez和Roberts(2011)发现人能感觉到的的脸部男性气质与2D:4D比率没有关联。”
简而言之,研究表明,在某些情况下,身体外观与行为可能微弱相关 - 一个嫌疑人还有许多其他外表线索(例如“非犯罪分子”上的白领)。但这些相关性远远不适合作为变量。
深度学习可以更好地从图像中提取细微的信息差别,而不是简单的特征测量,如面宽比。但是,正如我们所指出的,它不是魔法。上面讨论的许多论文都对人类法官使用了双盲试验,正是因为人类对脸部感知任务非常擅长。深度学习不能提取不存在的信息,我们应该怀疑它能可靠地从人类法官都参不透的图像中提取隐藏的意义。
判决
在过去的几年中,我们看到越来越多的人关注长期存在的大规模监禁问题。虽然美国占世界人口的5%左右,但占了约25%的全球监狱人口(240万人)。被监禁的人在经济状况和肤色上很不均衡。在美国,作为一名黑人男性,你被监禁的可能性是白人男性的七倍。 [21]这将使得面部图像的种族检测器成为美国“罪犯”相当有效的预测因子——就像 Wu 和 Zhang 在中国做的一样。这是否公平?由于奴隶制和系统歧视的长期影响,美国黑人生活拮据的人数不成比例的高。这本身就与罪犯数量多有关,就像英格兰十九世纪的白人位于经济底层一样。
许多不同的证据表明,黑人更多地被逮捕,更多地被定罪,比犯有同样罪行的白人受到更加严厉处罚。例如,因毒品犯罪的黑人入狱率高于白人的5.8倍,尽管药物使用的流行率相当可观。黑人也要服更长的刑期。最近出版的大规模纵向研究发现,即使是最贫穷的白人儿童,也比最富有的10%的黑人儿童较少去监狱。一旦进入监狱,黑人会受到更为严厉的惩教。法官的种族偏见的直接测试是使用假设的案件进行的,并且对(假设的)黑人被告的判罚越来越严厉,特别是当法官拥有高水平的隐含[22]种族偏见——这在法官当中流行且常见。
像 Wu 和 Zhang 在实验中那样的做法,[23]能否消除法官的隐含偏见呢?
大量研究表明情况恰恰相反。 [24]列举几个例子,2015年,天普大学的布莱恩·霍尔兹(Brian Holtz)发表了一系列实验的结果,其中脸部的“可信度”强烈影响了实验参与者的判断力。具体来说,参与者在阅读一个小片段后,需要决定一个假设的CEO的行为是公平还是不公平的。虽然参与者对判决公平或不公平的判断根据小片段描述的行为而变化,但CEO 简历中使用“值得信赖”或“不可信赖”的面部照片也会对结果产生影响。根据Oosterhof 和Todorov 的2008年的论文,这些照片中的面孔“可信度”有高低之分。在另一项研究中,参与者和他们自认为是真实的合作伙伴玩了一个在线投资游戏,这些合作伙伴的面孔“值得信赖”或“不可信赖”。参与者更有可能投资“值得信赖”的合作伙伴,即使有关于合作伙伴过去投资行为的声誉信息也不能影响面孔的影响力。最近一项研究发现,在以一级谋杀罪被定罪的囚犯中,“不可信赖的”面孔被不合比例地判处死刑,而不是无期徒刑。对于被诬告随后被免除起诉的人也是如此。
这反映的并不是内在的似乎能一眼看穿别人的直觉天赋。事实上,有证据表明,在很多情况下,如果忽视面部特征,依靠关于世界的常识,我们将会做得更好。此外,衡量经济行为可信度的研究表明,依靠面部进行判断使我们的决定不仅仅是不太准确。
所以,归纳来说:
在看一张面部照片时,一台机器作为“犯罪检测器”看到的东西,和人类在看到这张肖像时看到的东西并无不同;
在查看“犯罪”和“非犯罪”的脸部图像时,这种检测器可能与负面的感知有关;
产生了犯罪“真实”数据的人类法官本身受到这种“不可信赖”的看法的强烈影响,“不可信”的外观似乎不是实际不可信度的良好预测因素,也不可能是犯罪行为的良好预测因素。
对于碰巧有“不可信”面孔的人来说,这是不幸的。同样不幸的是,Wu 和 Zhang 的实验可能揭示的是,人类判断的不准确和系统的不公平,包括官方作出的刑事判决。而不是通过计算机找到了一个有效和公正的捷径来做出准确的刑事判断,
我们预计未来几年会出现更多的研究,为了洗清人类的偏见而对科学的客观性抱有类似的偏见,提出错误的要求。
反馈循环
“做个穷人很糟糕,觉得自己在某种程度上应该是穷人就更糟糕。你开始相信你的贫穷是因为你的愚蠢和丑陋。然后你开始相信你是愚蠢和丑陋的,因为你是印度人。而且因为你是印度人,所以你开始相信自己注定是穷人。这是一个丑陋的循坏,你无能为力。“
— Sherman Alexie, The Absolutely True Diary of a Part-Time Indian
- Sherman Alexie,兼职印度人真实的日记
社会上已经有许多反馈循环为劣势创造了复合效应。在历史上,在与身份相关的种族、残疾和其他类别的背景下,这已经被广泛撰写。
除了 Sherman Alexie 所指出的内在消极情绪的心理重压之外,还有一些重复的、对同一偏见的运用所产生的后果。如果一个人的外表会导致教师怀疑其作弊,同学们避免与其坐在同一个午餐桌上,陌生人避免和他交谈,潜在的雇主不给他/她 Offer,而且警察更频繁地对其“喊停和盘问”,那么长此以往,不出问题才怪。
Wu 和 Zhang 的研究作为警察和安全应用工具,对这一前景,我们认为最令人震惊的是,正如 Faception 公司所做的,它“科学地”将带有社会偏见的训练数据和系统判定之间的关系合法化了。当 Wu 和 Zhang 写下下面的话时,就完全错了。
“与人类考官/法官不同,计算机视觉的算法或分类器没有主观成见,没有情绪,没有来自经验的或种族、宗教、政治派别、性别、年龄等方面的任何偏见,没有精神上的倦怠,不会因为事先没吃好或没睡好就影响判断力。犯罪自动推理消除了元数据准确性(人事法官/审查员的能力)的变数。
这种修辞主张用嵌入相同偏见的机器学习技术来代替有偏见的人类判断,而且认为更可靠。而更糟糕的是,他们认为将机器学习引入到可以增加或扩大人类对犯罪行为判断力的环境中,可以使事情变得更公平。事实上,情况恰恰相反。因为人类会认为机器的“判断”不仅一贯公平,而且与个人偏见无关。因此,他们将以其直觉作为独立佐证,同意其结论。随着时间的推移,它将训练使用它的人类法官,以同样的方式来认识犯罪行为。我们现有的隐含偏见将被合法化、规范化和放大化。我们甚至可以想象,如果后续版本的机器学习算法被算法本身就是动因的犯罪所训练,就会产生失控效应。
“预测性警务”(被列为“时代周刊”2011 年度50 项较佳发明之一)是此类反馈循环的早期示例。这个想法希望使用机器学习将警察资源分配到可能的犯罪点。因为相信机器学习的客观性,美国几个州实行了这种警务方式。然而,很多人注意到系统正在从以前的数据中学习。如果警方本来在黑人社区的巡逻就超过白人社区,这将导致更多的黑人被捕; 该系统然后进一步学习到,黑人社区更可能发生逮捕,从而加强了原来的人的偏见。这样的系统在实际发生犯罪的地方,并没有导致较佳的监管。
结论
在科学层面上,机器学习可以给我们一个前所未有的自然和人类行为的窗口,让我们内省和系统地分析以前在直觉或群众智慧领域使用的模式。通过这个窗口, Wu 和 Zhang 的研究结果显示了令人尴尬的真相,揭示出我们一直以来是如何判断人的。
在实践层面上,机器学习技术将越来越多地成为我们生活的一部分,像许多强大的工具一样,它们可以而且常常用于良好的应用——包括基于数据更快更公平地做出判断。
机器学习也可能被误用,而这往往是无意的。这种误用往往是源于对技术问题狭隘的偏执,包括:
缺乏对训练数据偏见来源的洞察力;
缺乏对该领域现有研究的仔细审查,特别是在机器学习领域之外;
不考虑可以产生测量相关性的各种因果关系;
不考虑机器学习系统应如何被实际使用,以及在实践中可能有什么社会影响。
Wu 和 Zhang 的论文体现了上述所有陷阱。特别不幸的是,他们测量出的相关性——假设它在更严格的实验条件下仍然很明显——实际上可能是研究机构揭示刑事判决普遍偏见的重要补充。基于表面特征的深度学习,显然不是应该加快刑事司法的工具。这样的做法,比如Faception,将会使不公正永久化。
致谢和注释
致谢——
Charina Choi,谷歌
JasonFriedenfelds, 谷歌
Tobias Weyand,谷歌
Tim Freeman,谷歌
Alison Lentz,谷歌
Jac de Haan,谷歌
MeredithWhittaker, 谷歌
Kathryn Hume, FastForward 实验室
注释
[1]用于测量头骨轮廓的颅形描记器是专门针对这种应用开发的许多仪器之一。
[2]大约在同一时间,一篇关于使用深度学习预测脸部的第一印象的论文,正确地确定了他们正在测量的是主观印象,而不是客观的特征,该论文受到的关注较少。
[3]这种分层结构在大脑的视觉皮质上松散地建模,每个参数对应于突触的强度,或者从一个神经元到另一个神经元的电化学连接。
[4]许多卷积神经网络,包括 ChronoNet,属于深度学习的类别。 “深”意味着有多层连续的操作(因此有许多参数)。
[5]在本文中,性别被模仿为二进制,以基于自我宣称的性别身份为准。
[6]公平地说,这篇论文分析的现实世界快照数据库包括一些模糊的图像,还包括背对的人或戴着大太阳镜的人,以及 ID 照片中没有的其他困难案例。
[7]这让人联想到荷兰学者彼得·坎佩(1722-89)用来“推断”智力的“面角”(Facial angle)测量。
[8]有一些特定的认知障碍会削弱某些人在这项任务中的表现,就像阅读障碍会影响阅读一样。 “脸盲症”可能会影响〜2.5%的人口,包括一些令人惊讶的案例,如肖像艺术家 Chuck Close的案例。
[9]机器学习在过去几年中取得的巨大成就,是许多研究实验室经过数十年的努力,使得人脸识别能力得到了很大提高。
[10]新书《面部的价值:第一印象不可抗拒的影响》”的第一章,包括对面相学历史的更完整的评述。
[11]类似的类比思想是“幽默理论”,也起源于希腊,认为血液,痰,黑胆汁和黄胆汁的平衡决定了健康和个性。还有一些仍在使用的英文单词源自这个理论:sanguine(乐观), phlegmatic(冷静), bilious(恶心), choleric(不可理喻), melancholic(忧郁)。
[12]人类的个性“放养”可能意味着什么当然是第二次类比的飞跃。
[13]他的方法和他的分析今天都不会通过。他的测量是有选择性的,他的数据集很小,他的样本有偏差。
[14]在《人类的由来》中达尔文写道,奴隶制是“巨大的罪恶”,尽管接下来他指出,“有些野蛮人对于动物的残酷行为感到可怕的快乐,人性对他们来说是一种未知的美德。”对达尔文来说,奴隶制的罪恶源于残酷,而不是不平等。
[15] Haeckel 有犹太人朋友和同事,是达尔文主义在德国的主要推广者,所以犹太人和英国人都喜欢他的种族层次论也许并不奇怪。
[16]在他们的网站上,他们也指出,这些“类型”带有流行的心理描述的色彩——非常类似于古典文献中的类型学,如他们的“Bingo Player”描述的(是的,他们有一个 Bingo Player 检测器): “具有高精神上限,高度集中,冒险,强大的分析能力。倾向于具有创造力,具有高度的独创性和想象力,高度的保护欲和敏锐的感觉。“
[17]例如:对双胞胎的研究发现,阳光照射、吸烟和体重指数(主要由食物和运动习惯决定)显著影响面部老化。
[18]“她的得分比第二高出了13%,但她没有获得高级牧马人的头衔,因为只有男人被排名,而女人只是多带带列出。”(维基百科)
[19]见 The Fatal Shore,第10章,尾注48。
[20]暴力犯罪与男子相关度很高。在美国,98%的强奸罪,90%的谋杀案和78%的严重殴打的犯罪者是男人,但只有 57% 的盗窃罪和 51% 的贪污罪是男人。加拿大数据类似。这表明非暴力或白领犯罪可能不会有很强的性别相关性。
[21]在这个统计中,“黑人”和“白人”都排除了被确定为西班牙/拉丁裔的人口。
[22]使用反应时间在简单的分类测试(白人和黑人的脸以及褒义词和贬义词)上测量种族隐含的偏见。它揭示了个体隐含的与种族积极或消极的联系,独立于一个主体有意识的信仰。即使那个人没有自觉或明确的种族主义,一个人带有隐含偏见是非常普遍的;事实上,黑人主体通常也表现出隐含的反黑人偏见。
[23]他们的受试者都是中国人,因此“犯罪”和“非犯罪”集合之间的种族、经济和教育差异更为细微。这值得商榷。
[24]这个研究,以及第一印象准确性证据的缺乏,也在《面部的价值:第一印象不可抗拒的影响》中被评议:。
[25]马尔科姆·格拉德威尔(Malcolm Gladwell)的“眨眼”这本书普及了这样一个想法,即快速判断可以与理性考虑一样准确。直觉上说,这种观点的有效性是有限的,并且受到了广泛批评——正如本书所承认的那样。
原文链接:https://medium.com/@blaisea/physiognomys-new-clothes-f2d4b59fdd6a
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4535.html
摘要:文本谷歌神经机器翻译去年,谷歌宣布上线的新模型,并详细介绍了所使用的网络架构循环神经网络。目前唇读的准确度已经超过了人类。在该技术的发展过程中,谷歌还给出了新的,它包含了大量的复杂案例。谷歌收集该数据集的目的是教神经网络画画。 1. 文本1.1 谷歌神经机器翻译去年,谷歌宣布上线 Google Translate 的新模型,并详细介绍了所使用的网络架构——循环神经网络(RNN)。关键结果:与...
摘要:年实验室团队采用了深度学习获胜,失败率仅。许多其他参赛选手也纷纷采用这一技术年,所有选手都使用了深度学习。和他的同事运用深度学习系统赢得了美元。深度学习,似乎是解决 三年前,在山景城(加利福尼亚州)秘密的谷歌X实验室里,研究者从YouTube视频中选取了大约一千万张静态图片,并且导入到Google Brain —— 一个由1000台电脑组成的像幼儿大脑一样的神经网络。花费了三天时间寻找模式之...
摘要:我的核心观点是尽管我提出了这么多问题,但我不认为我们需要放弃深度学习。对于层级特征,深度学习是非常好,也许是有史以来效果较好的。认为有问题的是监督学习,并非深度学习。但是,其他监督学习技术同病相连,无法真正帮助深度学习。 所有真理必经过三个阶段:第一,被嘲笑;第二,被激烈反对;第三,被不证自明地接受。——叔本华(德国哲学家,1788-1860)在上篇文章中(参见:打响新年第一炮,Gary M...
摘要:谷歌也不例外,在大会中介绍了人工智能近期的发展及其对计算机系统设计的影响,同时他也对进行了详细介绍。表示,在谷歌产品中的应用已经超过了个月,用于搜索神经机器翻译的系统等。此外,学习优化更新规则也是自动机器学习趋势中的一个信号。 在刚刚结束的 2017 年国际高性能微处理器研讨会(Hot Chips 2017)上,微软、百度、英特尔等公司都发布了一系列硬件方面的新信息,比如微软的 Projec...

阅读 3006·2021-11-11 16:55
阅读 575·2021-09-27 13:36
阅读 1167·2021-09-22 15:35
阅读 2997·2019-08-30 12:46
阅读 3202·2019-08-26 17:02
阅读 1874·2019-08-26 11:56
阅读 1351·2019-08-26 11:47
阅读 463·2019-08-23 17:01





