
摘要:很多人可能会问这个故事和生成式对抗网络有什么关系其实,只要你能理解这段故事,就可以了解生成式对抗网络的工作原理。
男:哎,你看我给你拍的好不好?
女:这是什么鬼,你不能学学XXX的构图吗?
男:哦
……
男:这次你看我拍的行不行?
女:你看看你的后期,再看看YYY的后期吧,呵呵
男:哦
……
男:这次好点了吧?
女:呵呵,我看你这辈子是学不会摄影了
……
男:这次呢?
女:嗯,我拿去当头像了
上面这段对话讲述了一位“男朋友摄影师”的成长历程。很多人可能会问:这个故事和生成式对抗网络(GAN)有什么关系?其实,只要你能理解这段故事,就可以了解生成式对抗网络的工作原理。
首先,先介绍一下生成模型(generative model),它在机器学习的历史上一直占有举足轻重的地位。当我们拥有大量的数据,例如图像、语音、文本等,如果生成模型可以帮助我们模拟这些高维数据的分布,那么对很多应用将大有裨益。
针对数据量缺乏的场景,生成模型则可以帮助生成数据,提高数据数量,从而利用半监督学习提升学习效率。语言模型(language model)是生成模型被广泛使用的例子之一,通过合理建模,语言模型不仅可以帮助生成语言通顺的句子,还在机器翻译、聊天对话等研究领域有着广泛的辅助应用。
那么,如果有数据集S={x1,…xn},如何建立一个关于这个类型数据的生成模型呢?最简单的方法就是:假设这些数据的分布P{X}服从g(x;θ),在观测数据上通过较大化似然函数得到θ的值,即较大似然法:

GAN的工作原理是这样的
文章开头描述的场景中有两个参与者,一个是摄影师(男生),一个是摄影师的女朋友(女生)。男生一直试图拍出像众多优秀摄影师一样的好照片,而女生一直以挑剔的眼光找出“自己男朋友”拍的照片和“别人家的男朋友”拍的照片的区别。于是两者的交流过程类似于:男生拍一些照片 ->女生分辨男生拍的照片和自己喜欢的照片的区别->男生根据反馈改进自己的技术,拍新的照片->女生根据新的照片继续提出改进意见->……,这个过程直到均衡出现:即女生不能再分辨出“自己男朋友”拍的照片和“别人家的男朋友”拍的照片的区别。
我们将视线回看到生成模型,以图像生成模型举例。假设我们有一个图片生成模型(generator),它的目标是生成一张真实的图片。与此同时我们有一个图像判别模型(discriminator),它的目标是能够正确判别一张图片是生成出来的还是真实存在的。那么如果我们把刚才的场景映射成图片生成模型和判别模型之间的博弈,就变成了如下模式:生成模型生成一些图片->判别模型学习区分生成的图片和真实图片->生成模型根据判别模型改进自己,生成新的图片->····
这个场景直至生成模型与判别模型无法提高自己——即判别模型无法判断一张图片是生成出来的还是真实的而结束,此时生成模型就会成为一个完美的模型。这种相互学习的过程听起来是不是很有趣?
上述这种博弈式的训练过程,如果采用神经网络作为模型类型,则被称为生成式对抗网络(GAN)。用数学语言描述整个博弈过程的话,就是:假设我们的生成模型是g(z),其中z是一个随机噪声,而g将这个随机噪声转化为数据类型x,仍拿图片问题举例,这里g的输出就是一张图片。D是一个判别模型,对任何输入x,D(x)的输出是0-1范围内的一个实数,用来判断这个图片是一个真实图片的概率是多大。令Pr和Pg分别代表真实图像的分布与生成图像的分布,我们判别模型的目标函数如下:
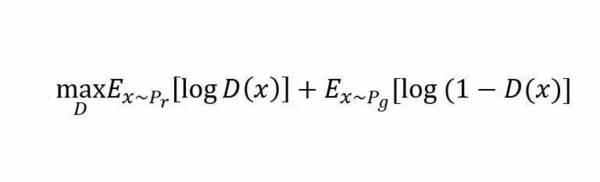
类似的生成模型的目标是让判别模型无法区分真实图片与生成图片,那么整个的优化目标函数如下:
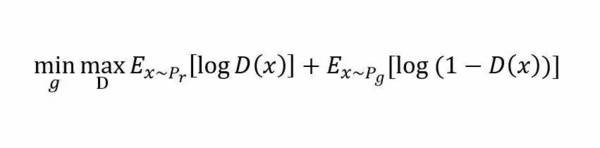
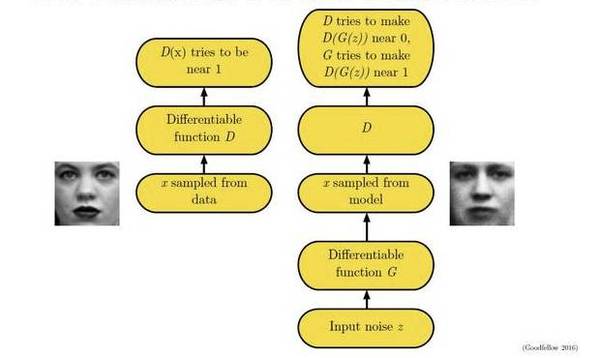
这个较大最小化目标函数如何进行优化呢?最直观的处理办法就是分别对D和g进行交互迭代,固定g,优化D,一段时间后,固定D再优化g,直到过程收敛。
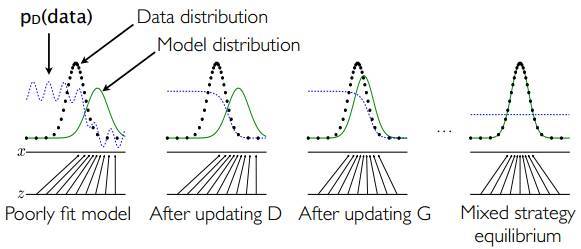
一个简单的例子如下图所示:假设在训练开始时,真实样本分布、生成样本分布以及判别模型分别是图中的黑线、绿线和蓝线。可以看出,在训练开始时,判别模型是无法很好地区分真实样本和生成样本的。接下来当我们固定生成模型,而优化判别模型时,优化结果如第二幅图所示,可以看出,这个时候判别模型已经可以较好的区分生成数据和真实数据了。第三步是固定判别模型,改进生成模型,试图让判别模型无法区分生成图片与真实图片,在这个过程中,可以看出由模型生成的图片分布与真实图片分布更加接近,这样的迭代不断进行,直到最终收敛,生成分布和真实分布重合。
以上就是生成式对抗网络的基本核心知识,下面我们看几个在实际中应用的例子。
GAN在图像中的应用——DCGAN
为了方便大家更好地理解生成式对抗网络的工作过程,下面介绍一个GAN的使用场景——在图片中的生成模型DCGAN。
在图像生成过程中,如何设计生成模型和判别模型呢?深度学习里,对图像分类建模,刻画图像不同层次,抽象信息表达的最有效的模型是:CNN (convolutional neural network,卷积神经网络)。
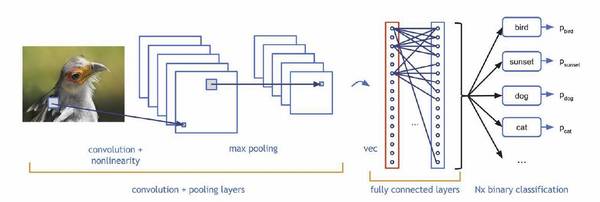
CNN是深度神经网络的一种,可以通过卷积层(convolutional layer)提取不同层级的信息,如上图所示。CNN模型以图片作为输入,以图片、类别抽象表达作为输出,如:纹理、形状等等,其实这与人类对图像的认知有相似之处,即:我们对一张照片的理解也是多层次逐渐深入的。
那么生成图像的模型应该是什么样子的呢?想想小时候上美术课,我们会先考虑构图,再勾画轮廓,然后再画细节,最后填充颜色,这事实上也是一个多层级的过程,就像是把图像理解的过程反过来,于是,人们为图像生成设计了一种类似反卷积的结构:Deep convolutional NN for GAN(DCGAN)
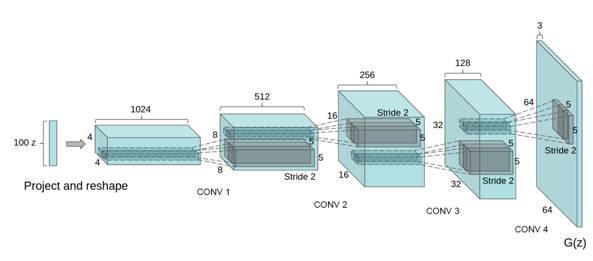
DCGAN采用一个随机噪声向量作为输入,如高斯噪声。输入通过与CNN类似但是相反的结构,将输入放大成二维数据。通过采用这种结构的生成模型和CNN结构的判别模型,DCGAN在图片生成上可以达到相当可观的效果。如下是一些生成的案例照片。

GAN在半监督学习中的应用
再来看一个GAN在半监督学习(semi supervised learning)中的例子。假如我们面对一个多分类的任务,手里只有很少有标注的样本,同时有很多没有标注的样本,怎么能够利用GAN的思路合理使用无标签数据,提高分类性能呢?
在去年NIPS大会上,来自OpenAI的作者提供了如下思路:考虑一个K分类任务,有一个判别模型 G可以帮助生成样本,与此同时,有一个判别模型做一个K+1分类任务,其中新加的类是预测样本是否是由生成模型生成的。跟传统GAN不同,这里我们最终需要的是判别模型,而不是生成模型。
简单而言,目标函数针对不同数据,可以分为两部分。对于有标注的样本,目标是希望判别模型能够正确输出标签。而对于没有标注的生成样本,则是由GAN定义的loss。
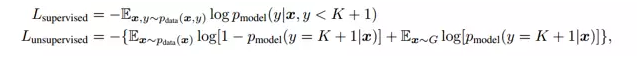
该作者认为这样处理的好处是可以充分利用未标注数据来学习样本分布,从而辅助监督学习的训练过程。实验结果也显示通过这种处理方法训练出来的判别模型,在合理利用未标注数据方面,有着比其他方法更好的效果。
GAN的改进——WGAN
刚才谈到很多GAN的优点、应用和变种,那么GAN真的是完美无缺的吗?
其实使用过GAN的人应该知道,训练GAN有很多头疼的问题。例如:GAN的训练对超参数特别敏感,需要精心设计。GAN中关于生成模型和判别模型的迭代也很有问题,按照通常理解,如果判别模型训练地很好,应该对生成的提高有很大作用,但实际中恰恰相反,如果将判别模型训练地很充分,生成模型甚至会变差。那么问题出在哪里呢?
在ICLR 2017大会上有一篇口头报告论文提出了这个问题产生的机理和解决办法。问题就出在目标函数的设计上。这篇文章的作者证明,GAN的本质其实是优化真实样本分布和生成样本分布之间的差异,并最小化这个差异。特别需要指出的是,优化的目标函数是两个分布上的Jensen-Shannon距离,但这个距离有这样一个问题,如果两个分布的样本空间并不完全重合,这个距离是无法定义的。
作者接着证明了“真实分布与生成分布的样本空间并不完全重合”是一个极大概率事件,并证明在一些假设条件下,可以从理论层面推导出一些实际中遇到的现象。
既然知道了问题的关键所在,那么应该如何解决问题呢?该文章提出了一种解决方案:使用Wasserstein距离代替Jensen-Shannon距离。并依据Wasserstein距离设计了相应的算法,即WGAN。新的算法与原始GAN相比,参数更加不敏感,训练过程更加平滑。
GAN的未来
无论是无监督学习、半监督学习,GAN给我们提供了一个处理问题的崭新思路,就是把博弈论引入到机器学习过程中来。可以预见,GAN本身的算法以及看问题的角度,必将对未来设计算法、以及解决实际问题产生深远的影响。
那么,GAN当前有哪些急需解决的问题呢:
首先,针对图片生成问题而言,一个至关重要的问题是GAN和其他方法比,到底好多少?GAN框架中的各种衍生算法相互比较,谁好谁坏?很可惜的是,现在没有一个客观的公认标准去衡量不同图片生成算法的差异性。其实这本身就是一个难题,因为人会从多角度判断一张图片是否真实,如图片是否清晰、图片物体线条颜色是否正确、图片里是否有一些反直觉的物体等,只有有了合理的衡量标准,才能科学系统地研究并改进GAN的算法。
其次,GAN是着眼于对所有生成模型的学习,并不局限于图像生成一个应用层面。那么GAN如何运用于其他问题,如机器翻译、对话生成、语音生成等?这些都是有趣、富有挑战的事情。其实还有更有趣的事情,如GAN能不能生成真实场景作为模拟器,帮助训练自动驾驶?GAN能否生成逼真的虚拟视觉给人们提供全新的游戏体验?
也许盗梦空间离我们很近,也许盗梦空间的创造者就是你。
参考文献:
1.Wasserstein GAN
https://arxiv.org/abs/1701.07875
2.Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
https://arxiv.org/abs/1511.06434
3.Improved techniques for training gans
https://arxiv.org/abs/1606.03498
4."Generative Adversarial Networks," NIPS 2016 tutorial by Ian Goodfellow
http://www.iangoodfellow.com/slides/2016-12-04-NIPS.pdf
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4530.html
摘要:但年在机器学习的较高级大会上,苹果团队的负责人宣布,公司已经允许自己的研发人员对外公布论文成果。苹果第一篇论文一经投放,便在年月日,斩获较佳论文。这项技术由的和开发,使用了生成对抗网络的机器学习方法。 GANs「对抗生成网络之父」Ian Goodfellow 在 ICCV 2017 上的 tutorial 演讲是聊他的代表作生成对抗网络(GAN/Generative Adversarial ...
摘要:引用格式王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃生成对抗网络的研究与展望自动化学报,论文作者王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃摘要生成式对抗网络目前已经成为人工智能学界一个热门的研究方向。本文概括了的研究进展并进行展望。 3月27日的新智元 2017 年技术峰会上,王飞跃教授作为特邀嘉宾将参加本次峰会的 Panel 环节,就如何看待中国 AI学术界论文数量多,但大师级人物少的现...
摘要:的两位研究者近日融合了两种非对抗方法的优势,并提出了一种名为的新方法。的缺陷让研究者开始探索用非对抗式方案来训练生成模型,和就是两种这类方法。不幸的是,目前仍然在图像生成方面显著优于这些替代方法。 生成对抗网络(GAN)在图像生成方面已经得到了广泛的应用,目前基本上是 GAN 一家独大,其它如 VAE 和流模型等在应用上都有一些差距。尽管 wasserstein 距离极大地提升了 GAN 的...
摘要:目前,生成对抗网络的大部分应用都是在计算机视觉领域。生成对抗网络生成对抗网络框架是由等人于年设计的生成模型。在设置中,两个由神经网络进行表示的可微函数被锁定在一个游戏中。我们提出了深度卷积生成对抗网络的实现。 让我们假设这样一种情景:你的邻居正在举办一场非常酷的聚会,你非常想去参加。但有要参加聚会的话,你需要一张特价票,而这个票早就已经卖完了。而对于这次聚会的组织者来说,为了让聚会能够成功举...
摘要:生成式对抗网络简称将成为深度学习的下一个热点,它将改变我们认知世界的方式。配图针对三年级学生的对抗式训练属于你的最严厉的批评家五年前,我在哥伦比亚大学举行的一场橄榄球比赛中伤到了自己的头部,导致我右半身腰部以上瘫痪。 本文作者 Nikolai Yakovenko 毕业于哥伦比亚大学,目前是 Google 的工程师,致力于构建人工智能系统,专注于语言处理、文本分类、解析与生成。生成式对抗网络—...

阅读 2159·2021-11-24 10:28
阅读 1204·2021-10-12 10:12
阅读 3413·2021-09-22 15:21
阅读 740·2021-08-30 09:44
阅读 1985·2021-07-23 11:20
阅读 1194·2019-08-30 15:56
阅读 1833·2019-08-30 15:44
阅读 1528·2019-08-30 13:55






