
摘要:论文可迁移性对抗样本空间摘要对抗样本是在正常的输入样本中故意添加细微的干扰,旨在测试时误导机器学习模型。这种现象使得研究人员能够利用对抗样本攻击部署的机器学习系统。
现在,卷积神经网络(CNN)识别图像的能力已经到了“出神入化”的地步,你可能知道在 ImageNet 竞赛中,神经网络对图像识别的准确率已经超过了人。但同时,另一种奇怪的情况也在发生。拿一张计算机已经识别得比较准确的图像,稍作“调整”,系统就会给出完全不同的结果,比如:
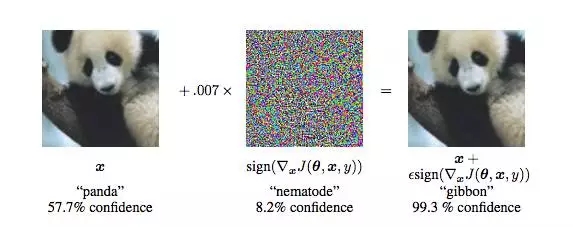
在左边的图像中,计算机认为图像是“熊猫”(57.7%),到了右边,就几乎肯定图像中显示的是“长臂猿”(99.3%)了。这个问题在 Goodfellow 等人《Explaining and Harnessing Adversarial Examples》一文中提出。
“神经网络很容易被骗过/攻击”这个话题,近来得到了越来越多研究者的讨论。
Szegedy 等人在《Intriguing properties of neural networks》一文中也提出了类似的例子。拿一张已经被正确分类的图像(左栏),加以扭曲(中间),在人眼看来与原图并无差异,但计算机会识别成完全不同的结果。

实际上,这样的情况并不仅限于图像识别领域,在语音识别、Softmax 分类器也存在。而语音、图像的识别的准确性对机器理解并执行用户指令的有效性至关重要。因此,这一环节也最容易被攻击者,通过对数据源的细微修改,就能达到让用户感知不到,但机器却能接收数据后做出错误的操作的结果,导致计算设备被入侵等一系列连锁反应。
这样的攻击被称为“对抗性攻击”。和其他攻击不同,对抗性攻击主要发生在构造对抗性数据的时候,之后该对抗性数据就如正常数据一样,输入机器学习模型并得到欺骗的识别结果。
通过向机器学习模型的输入样本引入微扰,可能会产生误导模型错误分类的对抗样本。对抗样本能够被用于制作成人类可识别,但计算机视觉模型会错误分类的图像,使恶意软件被分类为良性软件,以及强迫强化学习代理在游戏环境中的不当行为。
作为对抗生成网络(GAN)的发明人,Ian Goodfellow 自己也在研究“对抗性图像”在现实物理世界欺骗机器学习的效果,并由此对对抗性攻击进行防御。
昨天,号称要回到谷歌组建 GAN 团队的 Ian Goodfellow 和在他的研究合作者在 arXiv 上传了一篇论文《可迁移性对抗样本空间》(The Space of Transferable Adversarial Examples),朝着防御对抗性攻击迈出了第一步。
他们在研究中发现,对抗样本空间中存在一个大维度的连续子空间,该子空间是对抗空间的很重要部分,被不同模型所共享,因此能够实现迁移性。而这也是不同模型遭受对抗性攻击一个很重要的原因。
作者在论文中写道,他们的贡献主要有以下几点:
我们引入了一些找到多个独立攻击方向的方法。这些方向张成了一个连续的、可迁移的对抗子空间,其维度比先前的结果大了至少一个数量级。
我们对模型的决策边界进行了该领域内的首次量化研究,表明了来自不同假设类的模型学习到的决策边界非常接近,而与对抗性方向与良性方向无关。
在正式的研究中,我们找到了迁移性的充分条件,也找到了对抗样本迁移性不满足的实例。
论文:可迁移性对抗样本空间

摘要
对抗样本是在正常的输入样本中故意添加细微的干扰,旨在测试时误导机器学习模型。众所周知,对抗样本具有迁移性:同样的对抗样本,会同时被不同的分类器错误分类。这种现象使得研究人员能够利用对抗样本攻击部署的机器学习系统。
在这项工作中,我们提出了一种新颖的方法来估计对抗样本空间的维度。我们发现对抗样本空间中存在一个大维度的连续子空间,该子空间是对抗空间的很重要部分,被不同模型所共享,因此能够实现迁移性。可迁移的对抗子空间的维度意味着由不同模型学习到的学习边界在输入域都是异常接近的,这些边界都远离对抗方向上的数据点。对不同模型的决策边界的相似性进行了首次量化分析,结果表明,无论是对抗的还是良性的,这些边界实际上在任何方向上都是接近的。
我们对可迁移性的限制进行了正式研究,我们展示了:(1)数据分布的充分条件意味着简单模型类之间的迁移性;(2)迁移性不满足的任务示例。这表明,存在使模型具有鲁棒性的防御机制,能够抵御因对抗样本的迁移性而受到的攻击。
背景:对抗样本可迁移性是关键,首次估计了对抗样本子空间维度
论文中,研究人员首先对对抗性攻击及其影响做了阐释。
对抗样本经常在训练相同任务的不同模型之间迁移:尽管正在生成躲避特定架构的对抗样本,但是它们的类别被不同的模型误分。可迁移性是部署安全的机器学习系统的巨大障碍:对手可以使用本地代理模型制作能够误导目标模型的对抗样本以发起黑盒子的攻击。这些代理模型甚至在缺乏训练数据的情况下也能被训练,能实现与目标模型的交互作用最小。更好地理解为什么对抗样本具有迁移性,对于建立能成功防御黑盒攻击的系统是必要的。
对抗子空间:经验证据表明,对抗性样本发生在一些大的、连续的空间,而不是随机散布在小空间内。这些子空间的维度似乎与迁移性问题有关:维度越高,两个模型的子空间的可能相交越多。顺便说一句,这些子空间相交的越多,就越难以防御黑盒子的攻击。
该工作首次直接估计了这些子空间的维数。我们引入了一些发现多个正交对抗方向的方法,并展示了这些正交对抗方向张成了一个被错误分类的点的多维的连续空间。为了测量这些子空间的迁移性,我们在一些数据集上进行了实验,在这些数据集上不同的模型都达到了很高的准确率:数字分类和恶意软件检测。
我们在MNIST数据集上训练了一个全连接网络,平均来看,我们发现对抗样本在 25 维空间中迁移。
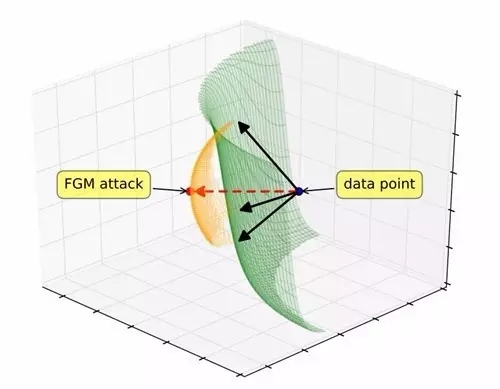
图一:梯度对齐对抗子空间(GAAS)。梯度对齐攻击(红色箭头)穿过决策边界。黑色箭头是与梯度对应的正交矢量,它们张成一个潜在的对抗输入(橙色)子空间。
高维度对抗子空间的迁移性意味着:用不同模型(如SVM和神经网络)训练得到的决策边界在输入空间是很接近的,这些边界都远离对抗方向上的数据点。经验表明,来自不同假设类的模型学习到的决策边界在任意方向上都是接近的,不管它们是对抗的还是良性的。
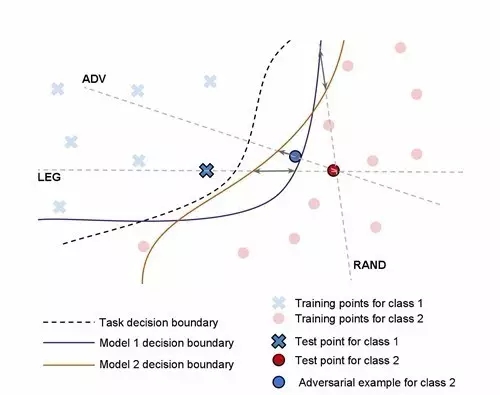
图三:这三个方向(Legitimate, Adversarial 和 Random)被用来测量两个模型决策边界之间的距离。灰色双端箭头表示两个模型在每个方向上的边界间距离。
更准确地说,我们发现,当进入远离数据点的任何方向,在到达决策边界之前行进的平均距离大于该方向上两个模型的决策边界的分开距离。因此,对抗微扰有足够的能力将数据点发送到远离模型的决策边界,并能够在不同的架构的其它模型中迁移。
可迁移的限制
鉴于迁移性的经验普遍性,我们很自然地会问迁移性是否能通过数据集的简单属性、模型类或训练算法来解释。我们考虑以下几点非正式的假设:
如果两个模型对一些模型都能实现低误差,同时对对抗样本表现出低的鲁棒性,这些对抗样本能在模型间迁移。
这个假设是悲观的:这意味着如果一个模型对它自己的对抗样本没有足够的抵抗力,那么它就不能合理地抵御来自其它模型的对抗样本(例如,前面提及到的黑盒子攻击)。然而,虽然在某些情况下,该假设与实际相符,但是我们的研究表明,在一般情况下,假设与实际并不相符。
我们为一组简单的模型类集合找到了针对上述假设形式的数据分布的充分条件。 即是,我们证明了模型不可知扰动的迁移性。这些对抗样本能够有效地攻击线性模型。然而,理论和经验都表明,对抗样本能够在更高阶模型(如二次模型)中迁移。
然而,我们通过构建了一个MNIST数据集的变体来展示了一个与上述假设不符的反例,因为对抗样本不能在线性和二次模型之间迁移。实验表明,迁移性不是非健壮的机器学习模型的固有属性。这表明有可能防御黑匣子的攻击——至少对于可能的攻击模型类的一个子集是满足的——尽管目标模型并不是如此健壮足以抵御它自己的对抗样本。
论文地址:https://arxiv.org/pdf/1704.03453v1.pdf
参考资料
http://karpathy.github.io/2015/03/30/breaking-convnets/
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4526.html
摘要:是世界上最重要的研究者之一,他在谷歌大脑的竞争对手,由和创立工作过不长的一段时间,今年月重返,建立了一个探索生成模型的新研究团队。机器学习系统可以在这些假的而非真实的医疗记录进行训练。今年月在推特上表示是的,我在月底离开,并回到谷歌大脑。 理查德·费曼去世后,他教室的黑板上留下这样一句话:我不能创造的东西,我就不理解。(What I cannot create, I do not under...
摘要:自年提出生成对抗网络的概念后,生成对抗网络变成为了学术界的一个火热的研究热点,更是称之为过去十年间机器学习领域最让人激动的点子。 自2014年Ian Goodfellow提出生成对抗网络(GAN)的概念后,生成对抗网络变成为了学术界的一个火热的研究热点,Yann LeCun更是称之为过去十年间机器学习领域最让人激动的点子。生成对抗网络的简单介绍如下,训练一个生成器(Generator,简称G...
摘要:但年在机器学习的较高级大会上,苹果团队的负责人宣布,公司已经允许自己的研发人员对外公布论文成果。苹果第一篇论文一经投放,便在年月日,斩获较佳论文。这项技术由的和开发,使用了生成对抗网络的机器学习方法。 GANs「对抗生成网络之父」Ian Goodfellow 在 ICCV 2017 上的 tutorial 演讲是聊他的代表作生成对抗网络(GAN/Generative Adversarial ...
摘要:可以想象,监督式学习和增强式学习的不同可能会防止对抗性攻击在黑盒测试环境下发生作用,因为攻击无法进入目标策略网络。我们的实验证明,即使在黑盒测试中,使用特定对抗样本仍然可以较轻易地愚弄神经网络策略。 机器学习分类器在故意引发误分类的输入面前具有脆弱性。在计算机视觉应用的环境中,对这种对抗样本已经有了充分研究。论文中,我们证明了对于强化学习中的神经网络策略,对抗性攻击依然有效。我们特别论证了,...

阅读 642·2021-11-18 13:12
阅读 1379·2021-11-15 11:39
阅读 2531·2021-09-23 11:22
阅读 6279·2021-09-22 15:15
阅读 3712·2021-09-02 09:54
阅读 2362·2019-08-30 11:10
阅读 3298·2019-08-29 14:13
阅读 2958·2019-08-29 12:49





