
摘要:中科院自动化所,中科院大学和南昌大学的一项合作研究,提出了双路径,通过单一侧面照片合成正面人脸图像,取得了当前较好的结果。研究人员指出,这些合成的图像有可能用于人脸分析的任务。恢复的图像的质量严重依赖于训练过程中的先验或约束条件。
中科院自动化所(CASIA),中科院大学和南昌大学的一项合作研究,提出了双路径 GAN(TP-GAN),通过单一侧面照片合成正面人脸图像,取得了当前较好的结果。研究人员提出了一个像人类一样能够考虑整体和局部信息的 GAN 结构,合成的图像非常逼真且很好地保留了身份特征,并且可以处理大量不同姿势的照片。研究人员指出,这些合成的图像有可能用于人脸分析的任务。

首先,让我们来看上面这张图,中间一栏是侧面 90°照片,你能看出计算机根据侧面照合成的正脸是左边一栏,还是右边一栏吗?
答案将在文末揭晓。
作为补充信息,下面这张图全部是计算机合成的,展示了从90°、75°和45°的轮廓的合成正面人脸视图。

根据侧面照片合成正面人脸一直是个难题,现在,由中科院自动化所(CASIA)、中科院大学和南昌大学的 Rui Huang、Shu Zhang、Tianyu Li、Ran He 合作的一项研究,首次解决了这一个问题,他们受人类视觉识别过程启发,结合对抗生成网络(GAN)的强大性能,提出了一个双路径 GAN(TP-GAN),能够在关注整体结构的同时,处理人脸面部细节,在不同的角度、光照条件都取得了很好的结果。不仅如此,这种方法还能够处理大量不同姿势的照片。
作者表示,他们这项工作是使用合成的人脸图像进行图像识别任务的首次有效尝试。
作者在论文中写道,他们的这项工作主要贡献在于三个方面:
1)提出了一个像人类一样能够考虑整体和局部信息的 GAN 结构,能够根据单一的图像合成正面人脸视图,合成的图像非常逼真且很好地保留了身份特征,而且可以应对大量不同的姿势。
2)将从数据分布(对抗训练)得来的先验知识,和人脸领域知识(对称性、身份保留损失)结合起来,将从三维物体投射到二维图像空间时固有的缺失信息较精确地恢复了出来。
3)展示了一个“通过生成进行识别”(recognition via generation)的框架的可能性,并且在大量不同姿势下取得了目前较好的识别结果。
真实应用场景中,不同姿势的识别没有很好的解决方案
虽然计算机识别图像已经在多个基准数据集中超越了人类,但真实应用场景中,对于不同姿势的识别问题仍然没有得到很好地解决。
现有方法可以分为两类,一类是采用手绘的(hand-crafted)特征或学习不同姿态的特征,另一类则是致力于在大量不同姿态的人脸中获取(recover)一个正面人脸视图,然后用这个视图进行人脸识别。
但是,第一类方法由于要在不变和可识别之间做出权衡,往往无法有效处理大量不同的姿势。
第二类方法,早期的尝试是先将二维图像与通用或有确切身份的3D模型对齐,然后利用三维几何变换渲染正面人脸视图。但是,这种方法遇到大量不同姿势的图像时,纹理损失严重,性能也不好。
近来,有研究者提出了由数据驱动的深度学习方法,让系统在学习估计正面视图的同时,分辨身份和姿势表征。虽然结果喜人,但合成的图像在细节方面有所欠缺,再一次地,这种方法也无法很好应对大量不同的姿势,因此合成的图像也无法用于法医取证或属性估计。
更重要的是,从优化的角度看,从观察到的不完全侧面脸部恢复正面视图,本身就是一个不合理而且也没有很好定义的问题。恢复的图像的质量严重依赖于训练过程中的先验或约束条件。
以往的方法通常采用配对监督学习的方式(pairwise supervision),极少在训练过程中引入约束条件(constraints),因此,才导致合成的图像模糊不清。
TP-GAN:受人类视觉启发,结合 GAN 强大的性能
当人类在进行视觉合成的时候,我们首先是通过观察到的侧脸,在以往的经验/知识基础上,推测出整张脸的结构(或草图)。然后,我们会将注意力转向脸部的细节,比如眼睛、鼻子、嘴唇,将这些细节在刚才那张草图上“填满”。
受此启发,作者提出了一个有两条路径的深度架构(TP-GAN),用于正面人脸图像合成。这两条路径,一条专注于推理全局结构,另一条则推理局部的纹理,分别得到两个特征地图。这两个特征图会融合在一起,用于接下来的最终合成。
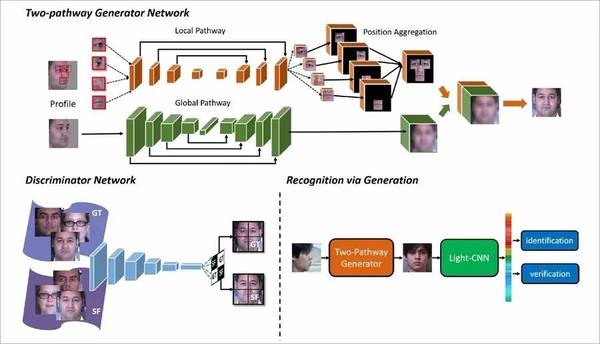
TP-GAN总结构示意图。生成器包含两个路径,一个处理全局信息,一个处理局部变换。判别器在合成的正面(SF)视图和真实相片(GT)。
不仅如此,作者还将正面人脸分布的信息并入了一个生成对抗网络(GAN),由此对恢复过程进行了很好的约束。
GAN 在二维数据分布建模方面的卓越性能(capacity)极大地改善了很多不合理的低级视觉问题,比如超分辨率和修复(inpainting)。
组合多种 Loss,合成缺失部分,保留面部突出特征
作者还根据人脸是对称结构这一点,提出了一个对称性损失(symmetry loss),用于补全被遮挡住的部分。

困难场景。面部特征,包括胡须、眼镜,TP-GAN 都保留了下来。最右边一栏,上面那张图将脸颊恢复了出来,下面那张图则是侧面看不见额头,但 TP-GAN 成功地将额头恢复了出来。
为了忠实地保留一个人脸部最突出的特征,作者在压缩特征空间中除了像素级别的 L1 loss,还使用了一个感知损失(perceptual loss)。
最后,关键一环,将身份保留损失(identity preserving loss)整合进来,实现忠实的正面脸部合成,图像质量得到大幅提升。

TP-GAN 根据不同姿势合成的结果。从左到右:90°、75°、45°、60°、30°和 15°。最后一栏是真实相片。

在不同的光线条件下合成的结果。上面一行是合成结果,下面一行是原始照片。
作者指出,这些图像有可能用于人脸分析的任务。
论文 | 超越脸部旋转:使用整体和局部感知 GAN 生成逼真、保留特征的正面人脸图像

使用单一脸部图像合成逼真的正面脸部视图在人脸识别领域中有着广泛的应用。尽管此前有研究试图从大量面部数据中寻求解决方案,也即数据驱动的深度学习方法,但这个问题仍然具有挑战性,因为它本质上是个不合理的问题(ill-posed)。
本文提出了双通道生成对抗网络(Two-Pathway Generative Adversarial Network,TP-GAN),通过同时感知全局结构和局部细节,合成逼真的正面人脸视图。
除了常用的全局编码器-解码器网络之外,论文还提出了4个定位标记的补丁网络(landmark located patch networks)处理局部纹理。除了全新的架构,我们将这个不合理的问题进行了很好的转化,引入了对抗性损失(adversarial loss)、对称性损失(symmetry loss)和身份保留损失(identity preserving loss)的组合。这一损失的组合能够利用正面脸部的分布和预训练识别深度脸部模型(pre-trained discriminative deep face models),指导身份保留推理从正面脸部视图合成侧面照。不同于以往的深度学习模型主要依靠中间特征用于识别的方法,我们的方法直接利用合成的、保留身份的图像用于下游任务,比如人脸识别和归因估计。实验结果表明,我们的方法不仅在视觉上令人信服,也在多种人脸识别中超越了现有较佳方法。
对了,还有一开始问题的答案:左边一栏是 TP-GAN 合成的结果。你答对了吗?
论文地址:https://arxiv.org/pdf/1704.04086.pdf
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4525.html
摘要:实现这一应用的基本思想方法是将图像的每一列用向量来表示,计算每一个的平均值,从而得到一个向量。标准加强学习模型通常要求建立一个奖励函数,用于向代理机器反馈符合预期的行为。来源更多信息自学成才让好奇驱动计算机学习在很多 还记得《射雕英雄传》中老顽童发明的左右互搏术吗? 表面上看,左手与右手互为敌手,斗得不可开交。实际上,老顽童却凭借此练就了一门绝世武功。 这样的故事似乎只能发生在小说中。然而,...
摘要:一段时间以来,我一直在尝试使用生成神经网络制作人物肖像。生成图像的质量与低分辨率输出实现密切相关。在第一阶段,根据给定描述生成相对原始的形状和基本的色彩,得出低分辨图像。使用生成的图像比现有方法更加合理逼真。 一段时间以来,我一直在尝试使用生成神经网络制作人物肖像。早期试验基于类似 Deep Dream 的方法,但最近我开始将精力集中在 GAN 上面。当然,无论在什么时候,高精度和较精确的细...
摘要:据报道,生成对抗网络的创造者,前谷歌大脑著名科学家刚刚正式宣布加盟苹果。他将在苹果公司领导一个机器学习特殊项目组。在加盟苹果后会带来哪些新的技术突破或许我们很快就会看到了。 据 CNBC 报道,生成对抗网络(GAN)的创造者,前谷歌大脑著名科学家 Ian Goodfellow 刚刚正式宣布加盟苹果。他将在苹果公司领导一个「机器学习特殊项目组」。虽然苹果此前已经缩小了自动驾驶汽车研究的规模,但...
摘要:作者在论文中将这种新的谱归一化方法与其他归一化技术,比如权重归一化,权重削减等,和梯度惩罚等,做了比较,并通过实验表明,在没有批量归一化权重衰减和判别器特征匹配的情况下,谱归一化改善生成的图像质量,效果比权重归一化和梯度惩罚更好。 就在几小时前,生成对抗网络(GAN)的发明人Ian Goodfellow在Twitter上发文,激动地推荐了一篇论文:Goodfellow表示,虽然GAN十分擅长...
摘要:该研究成果由韩国团队发表于论文地址训练数据恰当的训练数据有助于提高网络训练性能。在将损失函数应用于输入图像之前,用输入图像替换了掩模外部的图像的剩余部分。总体损失函数如下其中,发生器用进行训练,鉴别器用进行训练。 为一个设计师,是否整天因为繁琐枯燥的修图工作不胜其烦?现在,一款基于GAN的AI修图大师可以将你从这类工作中解放出来。修轮廓、改表情、生发、加耳环、去眼镜、补残图,你能想到的它都能...

阅读 2296·2019-08-30 15:54
阅读 2021·2019-08-30 13:49
阅读 715·2019-08-29 18:44
阅读 862·2019-08-29 18:39
阅读 1149·2019-08-29 15:40
阅读 1572·2019-08-29 12:56
阅读 3190·2019-08-26 11:39
阅读 3140·2019-08-26 11:37






