
摘要:深度学习浪潮这些年来,深度学习浪潮一直冲击着计算语言学,而看起来年是这波浪潮全力冲击自然语言处理会议的一年。深度学习的成功过去几年,深度学习无疑开辟了惊人的技术进展。
机器翻译、聊天机器人等自然语言处理应用正随着深度学习技术的进展而得到更广泛和更实际的应用,甚至会让人认为深度学习可能就是自然语言处理的终极解决方案,但斯坦福大学计算机科学和语言学教授 Christopher D. Manning 并不这么看,他认为深度学习确实能在自然语言处理领域有很大作为,但却并不能取代计算语言学。
深度学习浪潮
这些年来,深度学习浪潮一直冲击着计算语言学,而看起来 2015 年是这波浪潮全力冲击自然语言处理(NLP)会议的一年。然而,一些专家预测其带来的破坏最后还会更糟糕。2015 年,除了法国里尔召开的 ICML 大会,还有另外一个几乎同样大的事件:2015 深度学习研讨会(2015 Deep Learning Workshop)。该研讨会以一个 panel 讨论结束,正如 Neil Lawrence 在该 panel 上所说的:「NLP 有点(kind of)像是深度学习机器车灯前的一只兔子,等着被压扁。」很明显,计算语言学界需要慎重了!它会是我的道路的终点吗?这些压路机般的预测来自哪里?
2015 年 6 月,巴黎 Facebook 人工智能实验室开幕上,负责人 Yann LeCun 说:「深度学习的下一大步是自然语言理解,不只是给机器理解单个词的能力,而是理解整个句子、段落的能力。」
在 2014 年 11 月的 Reddit AMA(Ask Me Anything/随便问)问答上,Geoff Hinton 说:「我认为接下来 5 年,最令人激动的领域将会是理解文本和视频。如果 5 年内我们还没有在看过 YouTube 视频后能说出发生了什么的东西,我会感到很失望。数年内,我们将会把深度学习安置到能够放进耳朵那样的芯片上,并造出像巴别鱼(《银河系漫游指南》中出现的:如果你把一条巴别鱼塞进耳朵,就能立刻理解以任何形式的语言对你说的任何事情。)那样的英语解码芯片。」
此外,现代深度学习的另一位泰斗 Yoshua Bengio,也逐渐增加了他们团队在语言方面的研究,包括最近在神经机器翻译系统上令人激动的新研究。

从左到右:Russ Salakhutdinov(卡耐基梅隆大学机器学习系副教授)、Rich Sutton(阿尔伯塔大学计算机科学教授)、Geoff Hinton(在谷歌工作的认知心理学家和计算机科学家)、Yoshua Bengio(因在人工神经网络和深度学习的工作而知名的计算机科学家)和 2016 年讨论机器智能的一个 panel 的主持人 Steve Jurvetson,机器之心当时对此论坛进行了现场报道,参阅:《 | Hinton、Bengio、Sutton 等巨头聚首多伦多:通过不同路径实现人工智能的下一个目标 》
不只是深度学习研究者这么认为。机器学习领军人物 Michael Jordan 在 2014 年 9 月的 AMA 问答上被问到「如果在研究上你获得了 10 亿美元投入一个大项目,你想做什么?」他回答说,「我会使用这 10 亿美元建立一个专注于自然语言处理的 NASA 级项目,包括所有的方面(语义、语用等)。」他继续补充说,「我非常理性地认为 NLP 如此迷人,能让我们专注于高度结构化的推断问题上,在『什么是思想』这样的问题上直入核心,但明显更实际。它无疑也是一种能让世界变得更好的技术。」嗯,听起来不错。那么,计算语言学研究人员应该害怕吗?我认为,不!回到 Geoff Hinton 前面提到的巴别鱼,我们要把《银河系漫游指南》拿出来看看,其封面上用大而友好的字写着「不要惊慌」。
深度学习的成功
过去几年,深度学习无疑开辟了惊人的技术进展。这里我就不再详介,但举个例子说明。谷歌最近的一篇博客介绍了 Neon,也就是用于的 Google Voice 新的转录系统。在承认旧版的 Google Voice 语音邮件转录不够智能之后,谷歌在博客中介绍了 Neon 的开发,这是一个能够提供更准确转录的语音邮件系统,例如,「(Neon)使用一种长短期记忆深度循环神经网络(长舒一口气,whew!),我们将转录的错误率降低了 49%。」我们不都在梦想开发一种新方法,能够将之前较高级结果的错误率降低一半吗?
为什么计算语言学家不需要担心
Michael Jordan 在 AMA 中给出了两个理由解释为什么他认为深度学习不能解决 NLP 问题,「尽管现在的深度学习研究倾向于围绕 NLP,但(1)我仍旧不相信它在 NLP 上的结果强于视觉;(2)我仍旧不相信在 NLP 的案例中强于视觉。这种方法就是将巨量数据和黑箱的学习架构结合起来」在第一个论点上,Jordan 很正确:目前,在高层语言处理问题上,深度学习还无法像语音识别、视觉识别那样极大降低错误率。尽管也有所成果,但不像降低 25% 或 50% 的错误率那样骤然。而且可以很轻松地遇见这种情况还将持续。真正的巨大收获可能只在信号处理任务上有可能。
语言学领域的人,NLP 领域的人,才是真正的设计者。
另一方面,第二个 我。然而,对于为什么 NLP 不需要担忧深度学习,我确实有自己的两个理由:(1) 对于我们领域内最聪明、在机器学习方面最具影响力的人来说 NLP 才是需要聚焦的问题领域,这很美妙; (2) 我们的领域是语言技术的领域(domain)科学;它不是关于机器学习的较佳方法——中心问题仍然是领域问题。这个领域问题不会消失。Joseph Reisinger 在其博客上写道:「我经常在初创公司做通用机器学习,坦诚讲,这是一个相当荒谬的想法。机器学习并不是毫无差别的累活,它没有像 EC2 那样商品化,并比编码更接近于设计。」
从这个角度看,语言学领域的人、NLP 领域的人,才是真正的设计者。近期的 ACL 会议已经过于关注数量、关注突破较高级成果了。可称之为 Kaggle 竞赛。该领域的更多努力应该面向问题、方法以及架构。最近,我同合作者一直专注的一件事是开发普遍依存关系(Universal Dependencies)。目标是开发出通用的句法依存表征、POS 和特征标记集。这只是一个例子,该领域还有其他的设计努力,比如抽象含义表征(Abstract Meaning Representation)的思路。
语言的深度学习
深度学习到底在哪些方面帮助了自然语言处理?从使用分布式词表征,即使用真实值向量表征词与概念来看,到目前为止,NLP 并没有从深度学习(使用更抽象的层级表征提升泛化能力)获得较大的提高。所有词之间的相似性如具有密集和多维度表征,那么将在但不仅限于 NLP 中十分有用。事实上,分布式表征的重要性唤起了早期神经网络的「分布式并行处理」浪潮,而那些方法更具有更多的认知科学导向性焦点(Rumelhart 和 McClelland 1986)。这种方法不仅能更好地解释类人的泛化,同时从工程的角度来说,使用小维度和密集型词向量允许我们对大规模语境建模,从而大大提高语言模型。从这个角度来看,提高传统的词 n-gram 模型顺序会造成指数级的稀疏性并似乎会在概念性上破产。
智能需要能从知道小的部分理解整个大的事物。
我确实相信深度模型会很有用的。在深度表征中发生的共享在理论上可以给出指数级的表征优势,并在实际上提升学习系统的性能。构建深度学习系统的一般方法是优秀而强大的:在端到端学习框架中,研究人员定义了模型的架构和较好的损失函数(loss function),然后对模型的参数和表征进行自组织学习以最小化该损失。我们接下来会了解最近所研究的深度学习系统:神经机器翻译(neural machine translation/Sutskever, Vinyals, and Le 2014; Luong et al 2015)。
最后,我一直主张更多地关注模型的语义合成性,特别是语言和一般人工智能方面上。智能需要能从知道小的部分理解整个大的事物。尤其是语言,理解小说和复杂句子的关键在于能否从较小的部分(单词和短语)构建整体的意义。
最近,许多论文展示了如何从由「深度学习」方法的分布式词表征来提升系统性能的方法,如 word2vec (Mikolov et al. 2013) 或 GloVe (Pennington, Socher, and Manning 2014)。然而,这并不是构建深度学习模型,我也希望未来有更多的人关注强语言学的问题,即我们能否在深度学习系统上构建语义合成功能。
连接计算语言学和深度学习的科学问题
我不鼓励人们为了使用词向量来增长一点性能而努力研究,我建议我们可以回到一些有趣的语言学和认知性问题上,这些问题将促进非分类表征和神经网络方法的发展。
自然语言中非分类现象的一个例子是动名词 V-ing 形式(如 driving)的 POS。这种形式在动词形式和名词性动名词之间的经典描述是具有歧义的。事实上,真实情况是更复杂的,因为 V-ing 形式能出现在 Chomsky (1970) 的四种核心类别中:

更有趣的是,有证据表明其不仅有歧义,同时还混合了名词-动词的状态。例如,作为名词的经典语言学文本和限定词一同出现,而作为动词的经典语言学文本采用的是直接对象。然而,众所周知动名词名词化可以同时做到这两件事情:
1. The not observing this rule is that which the world has blamed in our satorist. (Dryden, Essay Dramatick Poesy, 1684, page 310)
2. The only mental provision she was making for the evening of life, was the collecting and transcribing all the riddles of every sort that she could meet with. (Jane Austen, Emma, 1816)
3. The difficulty is in the getting the gold into Erewhon. (Sam Butler, Erewhon Revisited, 1902)
这通常是在短语结构树形图的层次中通过某种类别的变更操作进行分析,但有证据表明,这个其实是语言中非分类行为的一种情况。
确实,这个解释早期用于 Ross (1972) 的「squish」案例。历时的(Diachronically),V-ing 形式表现出动词化的增长历史,但在许多时期,它表现出非常离散的状态。如我们在这个领域找到的明确评估判断:
4. Tom"s winning the election was a big upset.
5. This teasing John all the time has got to stop.
6. There is no marking exams on Fridays.
7. The cessation hostilities was unexpected.
限定词和动词对象的众多组合听起来并不是很好,但还是比通过派生词素(如-ation)名词化对象好多了。Houston (1985, page 320) 表明,V-ing 形式到离散词性分类的分配要比连续型解释在-ing 和-in 的语言交替性差得多(预测意义上)。他还认为「语法类别存在于一个连续统一体,它们在类别之间没有明确的边界。」
我的一个研究生同学 Whitney Tabor 探讨了一个不同而有趣的案例。Tabor (1994) 研究了 kind of 和 sort of 用法的不同,我在 1999 年的教科书(Manning and Schutze 1999)介绍性章节中使用了该案例。名词 kind 或 sort 能构成名词性短语,或者作为副词性修饰语的限制:
8. [That kind [of knife]] isn"t used much.
9. We are [kind of] hungry.
有趣的是,歧义性形式存在重新分析的路径,如下面的语料对,它们展示了一种形式是如何从另一种形式出现的。
10. [a [kind [of dense rock]]]
11. [a [[kind of] dense] rock]
Tabor (1994) 讨论了古典英语为什么存在 kind,但极少或根本没有 kind of 的用法。从中世纪英语开始,为再分析提供生长地的歧义语境开始出现(案例 (13) 中的是 1570 年的语句),随后的非歧义案例限制性修饰语出现了(案例(14)是 1830 年的语句):
12. A nette sent in to the see, and of alle kind of fishis gedrynge (Wyclif,1382)
13. Their finest and best, is a kind of course red cloth (True Report,1570)
14. I was kind of provoked at the way you came up (Mass. Spy,1830)
这是一段没有同步性(synchrony)的历史。
读者们,你们留意到了我在第一段中引用的那个例子吗?
15. NLP is kind of like a rabbit in the headlights of the deep learning machine (Neil Lawrence, DL workshop panel, 2015)
Whitney Tabor 使用一个小型的深度循环神经网络(具有两个隐藏层)对这个演化过程进行了建模。他在 1994 年利用与斯坦福的 Dave Rumelhart 一起工作的机会完成了该项研究。
就在最近,开始有一些新的研究工作旨在驾驭用于建模和解释语言差异与变化的分布式表征的力量。事实上,Sagi, Kaufmann, and Clark (2011) 使用了更加传统的研究方法——潜在语义分析(Latent Semantic Analysis)来生成分布式语词表征,展现分布式表征如何能捕捉到某个语义变化:随着时间的推移,被指称的对象范围的扩大和缩小。比如,在古英语(Old English)中,deer 是指任一动物,但在中世纪以及现代英语中,这个单词被用来清楚指称某科动物。dog 和 hound 的意思调了个个儿:在中世纪英语中,hound 被用来指称任何一种犬科动物,但是现在却被用来指称某特定子类,dog 的使用情况正好相反。
现在 NLP 对于机器学习和产业应用问题是如此关键,生活在这样一个时代我们应该感到兴奋和高兴。
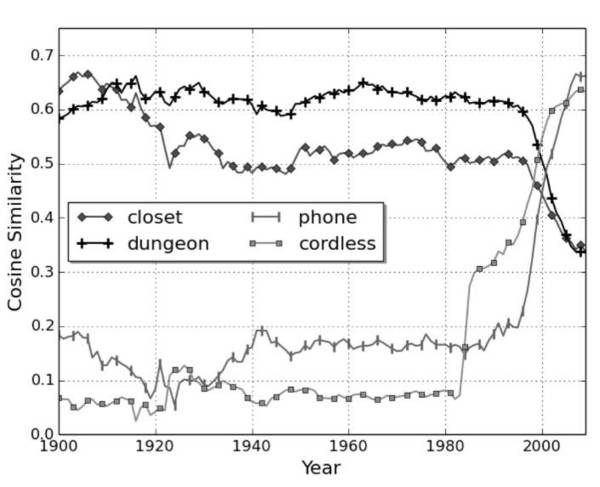
图 1:cell 与四个其它单词的余弦相似度随时间变化而变化(其中 1.0 表示较大相似度,0.0 表示无相似度)。
Kulkarni et al. (2015) 使用神经词嵌入(neural word embeddings)建模词义的转变,例如,过去一个世纪来 gay 的含义的转变(根据 Google Books Ngrams 语料库)。在一个最近的 ACL 研讨会上,Kim et al. (2014) 采用了一个相似方法——使用 word2vec——查看词义的最近变化。例如,图 1 中,2000 年左右他们表明 cell 的词义如何从接近于 closet 和 dungeon 迅速改变为接近于 phone 和 cordless。在这一语境中一个词的含义是超出词的所有含义的平均值,并通过使用频率加权。
分布式表征的科学应用越来越多,利用深度学习为语言现象建模,是神经网络之前兴起的两大特点。后来,由于网络上引用和确定深度学习研究工作上有些混乱,我认为有两个几乎不再被提及的人:Dave Rumelhart 和 Jay McClelland。从圣地亚哥的并行分布式处理研究小组开始,他们的研究项目就旨在从更加科学和认知的角度研究神经网络。
利用神经网络来解决规则统领下的语言行为(rule-governed linguistic behavior)问题是否妥当?现在,研究人员对此提出了一些好的质疑。资历老一些的研究人员应该还记得,多年前有关这一问题的论战让 Steve Pinker 声名鹊起,也奠定了他六位研究生职业生涯的基石。篇幅有限,我就不在这里展开了。但是,从结果上来看,我认为那一场争论富有成效。争论过后,Paul Smolensky 进行了大量研究工作,研究基础分类系统如何出现,以及如何在一个神经基质中表征出来(Smolensky and Legendre 2006)。实际上,人们认为 Paul Smolensky 在兔子洞里陷得太深,他将大部分精力投入到研究一种新的音系分类模型——最优化理论(Optimality Theory)((Prince and Smolensky 2004)中。很多早期的科研工作被忽略掉了。在自然语言处理领域,回过头来强调语言的认知和科学调查重要性,而不是几乎完全使用研究工程模型,这是有好处的。
总而言之,我认为我们应该为生活在自然语言处理被视为机器学习和工业应用问题核心的时代而感到激动。我们的未来是光明的,但每个人都应该更多地思考问题、架构、认知科学和人类语言的细节。我们需要探讨语言是如何学习、处理,又是如何产生变化的,而不是一次次在基准测试中冲击业内较佳。
原文链接:http://mitp.nautil.us/article/170/last-words-computational-linguistics-and-deep-learning
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4524.html
摘要:在过去几年中,深度学习改变了整个人工智能的发展。在本文中,我将介绍年深度学习的一些主要进展,与年深度学习进展版本一样,我没有办法进行详尽的审查。最后的想法与去年的情况一样,年深度学习技术的使用持续增加。 在过去几年中,深度学习改变了整个人工智能的发展。深度学习技术已经开始在医疗保健,金融,人力资源,零售,地震检测和自动驾驶汽车等领域的应用程序中出现。至于现有的成果表现也一直在稳步提高。在学术...
摘要:于月日至日在意大利比萨举行,主会于日开始。自然语言理解领域的较高级科学家受邀在发表主旨演讲。深度学习的方法在这两方面都能起到作用。下一个突破,将是信息检索。深度学习在崛起,在衰退的主席在卸任的告别信中这样写到我们的大会正在衰退。 SIGIR全称ACM SIGIR ,是国际计算机协会信息检索大会的缩写,这是一个展示信息检索领域中各种新技术和新成果的重要国际论坛。SIGIR 2016于 7月17...
摘要:深度学习近年来在中广泛使用,在机器阅读理解领域也是如此,深度学习技术的引入使得机器阅读理解能力在最近一年内有了大幅提高,本文对深度学习在机器阅读理解领域的技术应用及其进展进行了归纳梳理。目前的各种阅读理解任务中完形填空式任务是最常见的类型。 关于阅读理解,相信大家都不陌生,我们接受的传统语文教育中阅读理解是非常常规的考试内容,一般形式就是给你一篇文章,然后针对这些文章提出一些问题,学生回答这...

阅读 1747·2021-11-16 11:44
阅读 2474·2021-10-11 11:07
阅读 4243·2021-10-09 09:41
阅读 729·2021-09-22 15:52
阅读 3259·2021-09-09 09:33
阅读 2805·2019-08-30 15:55
阅读 2326·2019-08-30 15:55
阅读 882·2019-08-30 15:55




