
摘要:判别器胜利的条件则是很好地将真实图像自编码,以及很差地辨识生成的图像。
先看一张图:
下图左右两端的两栏是真实的图像,其余的是计算机生成的。

过渡自然,效果惊人。
这是谷歌本周在 arXiv 发表的论文《BEGAN:边界均衡生成对抗网络》得到的结果。这项工作针对 GAN 训练难、控制生成样本多样性难、平衡鉴别器和生成器收敛难等问题,提出了改善。
尤其值得注意的,是作者使用了很简单的结构,经过常规训练,取得了优异的视觉效果。
作者在论文中写道,他们的主要贡献是:
一个简单且具有鲁棒性的 GAN 架构,使用标准的训练步骤实现了快速、稳定的收敛
一种均衡的概念,用于平衡判别器和生成器(判别器往往在训练早期就以压倒性优势胜过生成器)
一种控制在图像多样性与视觉质量之间权衡的新方法
用于近似衡量收敛的方法,据我们所知,目前发表过的这类方法另外只有一种,那就是 Wasserstein GAN(WGAN)
GAN 的结构特点和理论优势
在介绍 BEGAN 之前,有必要回顾一下 GAN 和 EBGAN(Engry-Based GAN,基于能量的 GAN)。它们是 BEGAN 的基础。
中国科学院计算技术研究所智能信息处理重点实验室助理教授杨双在她发表在“深度学习大讲坛”的文章《解读 GAN 及其 2016 年度进展》当中,做了很好的介绍。我们在取得授权后引用了介绍 GAN 和 EBGAN 的相关部分。
首先是基本的 GAN 模型。
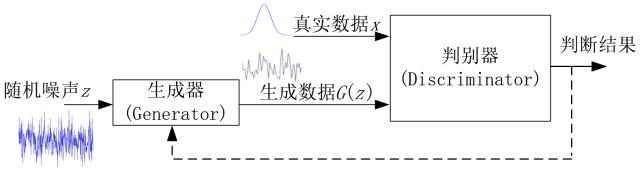
“原始 GAN 模型的基本框架如上图所示,其主要目的是要由判别器 D 辅助生成器 G 产生出与真实数据分布一致的伪数据。模型的输入为随机噪声信号 z;该噪声信号经由生成器 G 映射到某个新的数据空间,得到生成的数据 G(z);接下来,由判别器 D 根据真实数据 x 与生成数据 G(z) 的输入来分别输出一个概率值或者说一个标量值,表示 D 对于输入是真实数据还是生成数据的置信度,以此判断 G 的产生数据的性能好坏;当最终 D 不能区分真实数据 x 和生成数据 G(z) 时,就认为生成器 G 达到了最优。
“D 为了能够区分开两者,其目标是使 D(x) 与 D(G(z)) 尽量往相反的方向跑,增加两者的差异,比如使 D(x) 尽量大而同时使 D(G(z)) 尽量小;而 G 的目标是使自己产生的数据在 D 上的表现 D(G(z)) 尽量与真实数据的表现 D(x) 一致,让 D 不能区分生成数据与真实数据。因此,这两个模块的优化过程是一个相互竞争相互对抗的过程,两者的性能在迭代过程中不断提高,直到最终 D(G(z)) 与真实数据的表现 D(x) 一致,此时 G 和 D 都不能再进一步优化。”
杨双介绍说,GAN 除了提供了一种对抗训练的框架,另一个重要贡献是其收敛性的理论证明。
“作者通过将 GAN 的优化过程进行分解,从数学推导上严格证明了:在假设 G 和 D 都有足够的 capacity 的条件下,如果在迭代过程中的每一步,D 都可以达到当下在给定 G 时的最优值,并在这之后再更新 G ,那么最终 Pg 就一定会收敛于Pdata。也正是基于上述的理论,原始文章中是每次迭代中优先保证 D 在给定当前 G 下达到最优,然后再去更新 G 到最优,如此循环迭代完成训练。这一证明为 GAN 的后续发展奠定了坚实基础,使其没有像许多其它深度模型一样只是被应用而没有广而深的改进。”
判别器:借鉴基于能量的GAN
杨双在《解读 GAN 及其 2016 年度进展》当中介绍,对 GAN 模型的理论框架层面的改进工作主要可以归纳为两类:一类是从第三方的角度(不是从GAN 模型本身)看待 GAN 并进行改进和扩展的方法;第二类是从 GAN 模型框架的稳定性、实用性等角度出发对模型本身进行改进的工作。
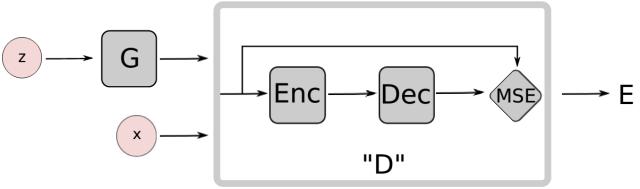
其中,“EBGAN 是 Yann LeCun 课题组提交到 ICLR2017的一个工作,从能量模型的角度对 GAN 进行了扩展。EBGAN 将判别器看做是一个能量函数,这个能量函数在真实数据域附近的区域中能量值会比较小,而在其他区域(即非真实数据域区域)都拥有较高能量值。因此,EBGAN 中给予 GAN 一种能量模型的解释,即生成器是以产生能量最小的样本为目的,而判别器则以对这些产生的样本赋予较高的能量为目的。
“从能量模型的角度来看待判别器和 GAN 的好处是,我们可以用更多更宽泛的结构和损失函数来训练 GAN 结构,比如文中就用自编码器(AE)的结构来作为判别器实现整体的GAN 框架,如下图所示:
在训练过程中,EBGAN 比 GAN 展示出了更稳定的性能,也产生出了更加清晰的图像,如下图所示。

生成器:借鉴 Wasserstein GAN
谷歌的这篇新论文提出的 BEGAN(Boundary Equilibrium GAN),将 AE 作为判别器,在架构上与 EBGAN 十分类似。
在生成器方面,BEGAN 则借鉴了 Wasserstein GAN 定义 loss 的思路。作者在论文中写道,“我们的方法使用从 Wasserstein 距离衍生而来的 loss 去匹配自编码 loss 分布。”
今年年初 WGAN 论文发布时,也在业界引发热议,当时新智元转载了郑华滨发表在知乎专栏的文章《令人拍案叫绝的 Wasserstein GAN,彻底解决 GAN 训练不稳定问题》。
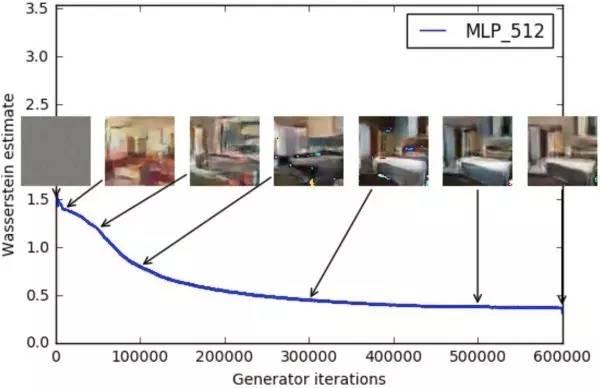
在 WGAN 中,判别器近似的 Wasserstein 距离与生成器的生成图片质量高度相关,如下所示:
相比传统 GAN 直接匹配数据分布,EBGAN 使用一种新的方法,将 loss 基于判别器的重构误差。作者通过一个额外的均衡条件,让生成器和判别器相互平衡。作者表示,他们的方法训练起来更方便,与传统 GAN 技巧相比架构也更简单。
EBGAN:简单模型,效果惊艳
回到我们介绍的 BEGAN,BEGAN 的架构十分简单,几乎所有都是 3×3 卷积,sub-sampling 或者 upsampling,没有 dropout、批量归一化或者随机变分近似。
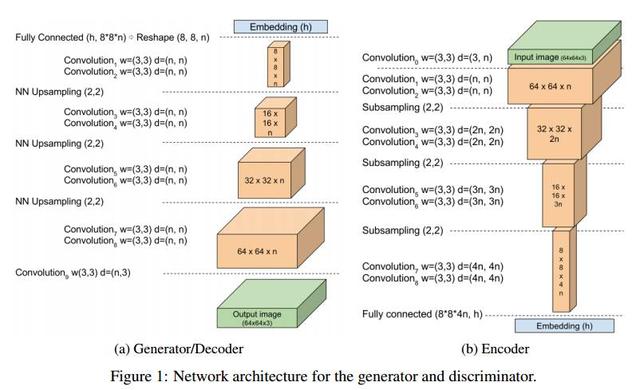
判别器是 loss 为 L1 的自编码器,生成器每生成一幅图,这幅图判别器能够在 loss 很小的情况下自编码,生成器就算胜利。判别器胜利的条件则是①很好地将真实图像自编码,以及②很差地辨识生成的图像。
这篇论文的另一个贡献是提出了一个衡量生成样本多样性的超参数 γ:生成样本 loss 的预期与真实样本 loss的预期之比。这个超参数能够均衡 D 和 G,从而稳定训练过程。如果生成器表现太好,就侧重判别器。
不仅如此,这个超参数 γ 还提供了一个可以衡量的指标,用于判断收敛,最终也对应图像的质量。

摘要
我们提出了一种新的用于促成训练时生成器和判别器实现均衡(Equilibrium)的方法,以及一个配套的 loss,这个 loss 由 Wasserstein distance 衍生而来,Wasserstein distance 则是训练基于自编码器的生成对抗网络(GAN)使用的。此外,这种新的方法还提供了一种新的近似收敛手段,实现了快速稳定的训练和很高的视觉质量。我们还推导出一种能够控制权衡图像多样性和视觉质量的方法。在论文里我们专注于图像生成任务,在更高的分辨率下建立了视觉质量的新里程碑。所有这些都是使用相对简单的模型架构和标准的训练流程实现的。

测试结果:上面是基于能量的GAN(EBGAN)与边界均衡 GAN(BEGAN)的对比,后者由显著提升;下面展示展示了超参数 γ 值不同情况的对比,可以看出 γ 值越大图片质量越高。
参考资料
杨双,【青年学者专栏】解读GAN及其 2016 年度进展,深度学习大讲堂
郑华滨,令人拍案叫绝的Wasserstein GAN,知乎专栏
商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4503.html
摘要:一段时间以来,我一直在尝试使用生成神经网络制作人物肖像。生成图像的质量与低分辨率输出实现密切相关。在第一阶段,根据给定描述生成相对原始的形状和基本的色彩,得出低分辨图像。使用生成的图像比现有方法更加合理逼真。 一段时间以来,我一直在尝试使用生成神经网络制作人物肖像。早期试验基于类似 Deep Dream 的方法,但最近我开始将精力集中在 GAN 上面。当然,无论在什么时候,高精度和较精确的细...

阅读 847·2021-10-09 09:58
阅读 695·2021-08-27 16:24
阅读 1781·2019-08-30 14:15
阅读 2425·2019-08-30 11:04
阅读 2145·2019-08-29 18:43
阅读 2206·2019-08-29 15:20
阅读 2766·2019-08-26 12:20
阅读 1693·2019-08-26 11:44


