
摘要:所有操作都是节点形式表示的,包括计算节点和非计算节点。采用回合通信机制,类似生产者消费者的消息信箱。解析器将协议内存块解析为张量,放入队列中,其中命名和类型要与写入的一致。目前就职于腾讯事业部,从事神经机器翻译工作。
4. TF – Kernels模块
TF中包含大量Op算子,这些算子组成Graph的节点集合。这些算子对Tensor实现相应的运算操作。图 4 1列出了TF中的Op算子的分类和举例。

图 4 1 TensorFlow核心库中的部分运算
4.1 OpKernels 简介
OpKernel类(core/framework/op_kernel.h)是所有Op类的基类。继承OpKernel还可以自定义新的Op类。用的较多的Op如(MatMul, Conv2D, SoftMax, AvgPooling, Argmax等)。
所有Op包含注册(Register Op)和实现(正向计算、梯度定义)两部分。
所有Op类的实现需要overide抽象基函数 void Compute(OpKernelContext* context),实现自身Op功能。用户可以根据需要自定义新的Op操作,参考[12]。
TF中所有Op操作的属性定义和描述都在 ops/ops.pbtxt。如下Add操作,定义了输入参数x、y,输出参数z。

4.2 UnaryOp & BinaryOp
UnaryOp和BinaryOp定义了简单的一元操作和二元操作,类定义在/core/kernels/ cwise_ops.h文件,类实现在/core/kernels/cwise_op_*.cc类型的文件中,如cwise_op_sin.cc文件。
一元操作全称为Coefficient-wise unary operations,一元运算有abs, sqrt, exp, sin, cos,conj(共轭)等。如abs的基本定义:

二元操作全称为Coefficient-wise binary operations,二元运算有add,sub, div, mul,mod等。如sum的基本定义:

4.3 MatMul
4.3.1 Python相关部分
在Python脚本中定义matmul运算:

根据Ops名称MatMul从Ops库中找出对应Ops类型
创建ops节点

创建ops节点并指定相关属性和设备分配

4.3.2 C++相关部分
Python脚本通过swig调用进入C接口API文件core/client/tensor_c_api.cc,调用TF_NewNode函数生成节点,同时还需要指定输入变量,TF_AddInput函数设置first输入变量,TF_AddInputList函数设置other输入变量。这里op_type为MatMul,first输入变量为a,other输入变量为b。

创建节点根据节点类型从注册的Ops工厂中生成,即TF通过工厂模式把一系列Ops注册到Ops工厂中。其中MatMul的注册函数为如下

4.3.3 MatMul正向计算
MatMul的实现部分在core/kernels/matmul_op.cc文件中,类MatMulOp继承于OpKernel,成员函数Compute完成计算操作。

MatMul的测试用例core/kernels/matmul_op_test.cc文件,要调试这个测试用例,可通过如下方式:

在TF中MatMul实现了CPU和GPU两个版本,其中CPU版本使用Eigen库,GPU版本使用cuBLAS库。
CPU版的MatMul使用Eigen库,调用方式如下:

简而言之就是调用eigen的constract函数。
GPU版的MatMul使用cuBLAS库,准确而言是基于cuBLAS的stream_executor库。Stream executor是google开发的开源并行计算库,调用方式如下:

其中stream类似于设备句柄,可以调用stream executor中的cuda模块完成运算。
4.3.4 MatMul梯度计算
MatMul的梯度计算本质上也是一种kernel ops,描述为MatMulGrad。MatMulgrad操作是定义在grad_ops工厂中,类似于ops工厂。定义方式如下:

MatmulGrad由FDH(Function Define Helper)完成定义,

其中attr_adj_x="transpose_a" ax0=false, ax1=true, attr_adj_y= "transpose_b", ay0=true, ay1=false, *g属于FunctionDef类,包含MatMul的梯度定义。
从FDH定义中可以看出MatMulGrad本质上还是MatMul操作。在矩阵求导运算中:
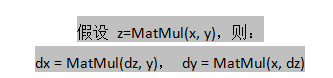
MatMulGrad的测试用例core/ops/math_grad_test.cc文件,要调试这个测试用例,可通过如下方式:

4.4 Conv2d
关于conv2d的python调用部分和C++创建部分可参考MatMul中的描述。
4.4.1 Conv2d正向计算部分
TF中conv2d接口如下所示,简单易用:
实现部分在core/kernels/conv_ops.cc文件中,类Conv2DOp继承于抽象基类OpKernel。
Conv2DOp的测试用例core/kernels/eigen_spatial_convolutions_test.cc文件,要调试这个测试用例,可通过如下方式:

Conv2DOp的成员函数Compute完成计算操作。
为方便描述,假设tf.nn.conv2d中input参数的shape为[batch, in_rows, in_cols, in_depth],filter参数的shape为[filter_rows, filter_cols, in_depth, out_depth]。
首先,计算卷积运算后输出tensor的shape。
Ø 若padding=VALID,output_size = (input_size - filter_size + stride) / stride;
Ø 若padding=SAME,output_size = (input_size + stride - 1) / stride;
其次,根据计算结果给输出tensor分配内存。
然后,开始卷积计算。Conv2DOp实现了CPU和GPU两种模式下的卷积运算。同时,还需要注意input tensor的输入格式,通常有NHWC和NCHW两种格式。在TF中,Conv2d-CPU模式下目前仅支持NHWC格式,即[Number, Height, Weight, Channel]格式。Conv2d-GPU模式下以NCHW为主,但支持将NHWC转换为NCHW求解。C++中多维数组是row-major顺序存储的,而Eigen默认是col-major顺序的,则C++中[N, H, W, C]相当于Eigen中的[C, W, H, N],即dimention order是相反的,需要特别注意。
Conv2d-CPU模式下调用Eigen库函数。

Eigen库中卷积函数的详细代码参见图 4 2。
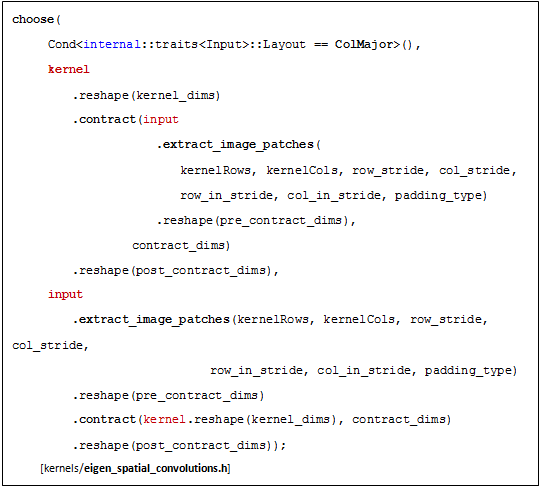
图 4 2 Eigen卷积运算的定义
Ø Tensor:: extract_image_patches () 为卷积或池化操作抽取与kernel size一致的image patches。该函数的定义在eigen3/unsupported/Eigen/CXX11/src/Tensor/ TensorBase.h中,参考该目录下ReadME.md。
Ø Tensor:: extract_image_patches () 的输出与input tensor的data layout有关。设input tensor为ColMajor格式[NHWC],则image patches输出为[batch, filter_index, filter_rows, filter_cols, in_depth],并reshape为[batch * filter_index, filter_rows * filter_cols * in_depth],而kernels维度为[filter_rows * filter_cols * in_depth, out_depth],然后kernels矩阵乘image patches得到输出矩阵[batch * filter_index, out_depth],并reshape为[batch, out_rows, out_cols, out_depth]。
Conv2d-GPU模式下调用基于cuDNN的stream_executor库。若input tensor为NHWC格式的,则先转换为NCHW格式

调用cudnn库实现卷积运算:

计算完成后再转换成HHWC格式的

4.4.2 Conv2d梯度计算部分
Conv2D梯度计算公式,假设output=Conv2d(input, filter),则

Conv2D梯度计算的测试用例core/kernels/eigen_backward_spatial_convolutions_test.cc文件,要调试这个测试用例,可通过如下方式:
Conv2d的梯度计算函数描述为Conv2DGrad。Conv2DGrad操作定义在grad_ops工厂中。注册方式如下:

Conv2DGrad由FDH(Function Define Helper)完成定义,参见图 4 3。

图 4 3 Conv2DGrad的函数定义
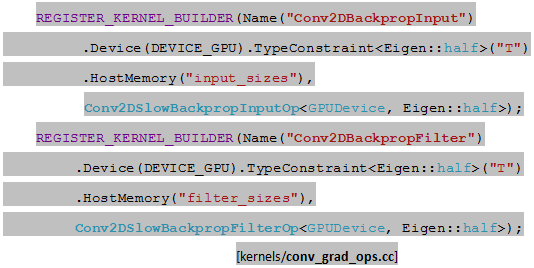
Conv2DGrad梯度函数定义中依赖Conv2DBackpropInput和Conv2DBackpropFilter两种Ops,二者均定义在kernels/conv_grad_ops.cc文件中。
Conv2DBackpropInputOp和Conv2DBackpropFilterOp的实现分为GPU和CPU版本。
Conv2D运算的GPU版实现定义在类Conv2DSlowBackpropInputOp
Conv2D运算的CPU版有两种实现形式,分别为custom模式和fast模式。Custom模式基于贾扬清在caffe中的思路实现,相关类是Conv2DCustomBackpropInputOp
根据Conv2DGrad的函数定义,从代码分析Conv2D-GPU版的实现代码,即分析Conv2DBackpropInput和Conv2DBackpropFilter的实现方式。
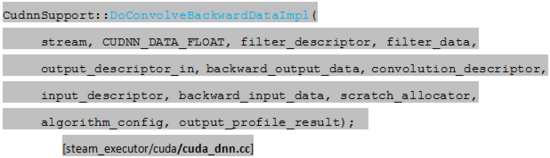
Conv2DSlowBackpropInputOp的成员函数Compute完成计算操作。
Compute实现部分调用stream executor的相关函数,需要先获取库的stream句柄,再调用卷积梯度函数。

stream executor在卷积梯度运算部分仍然是借助cudnn库实现的。
4.4.3 MaxPooling计算部分
在很多图像分类和识别问题中都用到了池化运算,池化操作主要有较大池化(max pooling)和均值池化(avg pooling),本章节主要介绍较大池化的实现方法。调用TF接口可以很容易实现池化操作。

Eigen库中较大池化的详细描述如下:
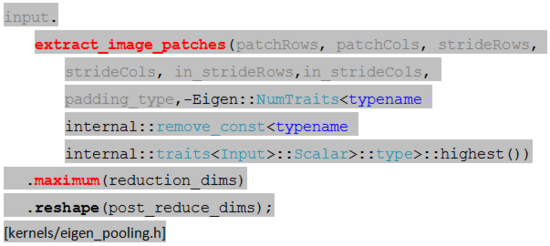
其中较大池化运算主要分为两步,第一步中extract_image_patch为池化操作抽取与kernel size一致的image patches,第二步计算每个image patch的较大值。
4.5 SendOp & RecvOp
TF所有操作都是节点形式表示的,包括计算节点和非计算节点。在跨设备通信中,发送节点(SendOp)和接收节点(RecvOp)为不同设备的两个相邻节点完成完成数据通信操作。Send和Recv通过TCP或RDMA来传输数据。
TF采用Rendezvous(回合)通信机制,Rendezvous类似生产者/消费者的消息信箱。引用TF描述如下:

TF的消息传递属于采用“发送不阻塞/接收阻塞”机制,实现场景有LocalRendezvous
(本地消息传递)、RpcRemoteRendezvous (分布式消息传递)。除此之外还有IntraProcessRendezvous用于本地不同设备间通信。
TF会在不同设备的两个相邻节点之间添加Send和Recv节点,通过Send和Recv之间进行通信来达到op之间通信的效果,如图 4 4右子图所示。图中还涉及到一个优化问题,即a->b和a->c需要建立两组send/recv连接的,但两组连接是可以共用的,所以合并成一组连接。
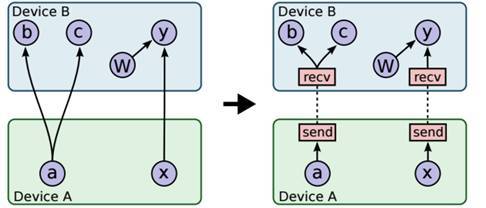
图 4 4 Graph跨设备通信
Send和Recv分别对应OpKernel中的SendOp和RecvOp两个类(kernels/sendrecv_ops.h)。
SendOp的计算函数。

SendOp作为发送方需要先获取封装ctx消息,然后借助Rendezvous模块发送给接收方。
RecvOp的计算函数如下。
RecvOp作为接收方借助Rendezvous模块获取ctx消息。
其中parsed变量是类ParsedKey的实例。图 5‑5是Rendezvous封装的ParsedKey消息实体示例。

4.6 ReaderOp & QueueOp
4.6.1 TF数据读取
TF系统定义了三种数据读取方式[13]:
Ø 供给数据(Feeding): 在TensorFlow程序运行的每一步, 通过feed_dict来供给数据。
Ø 从文件读取数据: 在TensorFlow图的起始, 让一个输入管线(piplines)从文件中读取数据放入队列,通过QueueRunner供给数据,其中队列可以实现多线程异步计算。
Ø 预加载数据: 在TensorFlow图中定义常量或变量来保存所有数据,如Mnist数据集(仅适用于数据量比较小的情况)。
除了以上三种数据读取方式外,TF还支持用户自定义数据读取方式,即继承ReaderOpKernel类创建新的输入读取类[14]。本章节主要讲述通过piplines方式读取数据的方法。
Piplines利用队列实现异步计算
从piplines读取数据也有两种方式:一种是读取所有样本文件路径名转换成string tensor,使用input_producer将tensor乱序(shuffle)或slice(切片)处理放入队列中;另一种是将数据转化为TF标准输入格式,即使用TFRecordWriter将样本数据写入tfrecords文件中,再使用TFRecordReader将tfrecords文件读取到队列中。
图 4 6描述了piplines读取数据的第一种方式,这些流程通过节点和边串联起来,成为graph数据流的一部分。
从左向右, 第一步 是载入文件列表,使用convert_to_tensor函数将文件列表转化为tensor,如cifar10数据集中的image_files_tensor和label_tensor。
第二步是使用input_producer将image_files_tensor和label_tensor放入图中的文件队列中,这里的input_producer作用就是将样本放入队列节点中,有string_input_producer、range_input_producer和slice_input_producer三种,其中slice_input_producer的切片功能支持乱序,其他两种需要借助tf.train.shuffle_batch函数作乱序处理,有关三种方式的具体描述可参考tensorflow/python/training/input.py注释说明。
第三步是使用tf.read_file()读取队列中的文件数据到内存中,使用解码器如tf.image.decode_jpeg()解码成[height, width, channels]格式的数据。
最后就是使用batch函数将样本数据处理成一批批的样本,然后使用session执行训练。
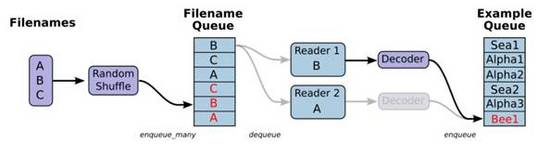
图 4 6 使用piplines读取数据
4.6.2 TFRecords使用
TFRecords是TF支持的标准文件格式,这种格式允许将任意的数据转换为TFRecords支持的文件格式。TFRecords方法需要两步:第一步是使用TFRecordWriter将样本数据写入tfrecords文件中,第二步是使用TFRecordReader将tfrecords文件读取到队列中。
图 4 7是TFRecords文件写入的简单示例。tf.train.Example将数据填入到Example协议内存块(protocol buffer),将协议内存块序列化为一个字符串,通过TFRecordWriter写入到TFRecords文件,图中定义了label和image_raw两个feature。Example协议内存块的定义请参考文件core/example/example.proto。

图 4 7 TFRecordWriter写入数据示例
图 4 8是TFRecords文件读取的简单示例。tf.parse_single_example解析器将Example协议内存块解析为张量,放入example队列中,其中features命名和类型要与Example写入的一致。

图 4 8 TFRecrodReader读取数据示例
4.6.3 ReaderOps分析
ReaderOpsKernel类封装了数据读取的入口函数Compute,通过继承ReaderOpsKernel类可实现各种自定义的数据读取方法。图 4 9是ReaderOp相关的UML视图。
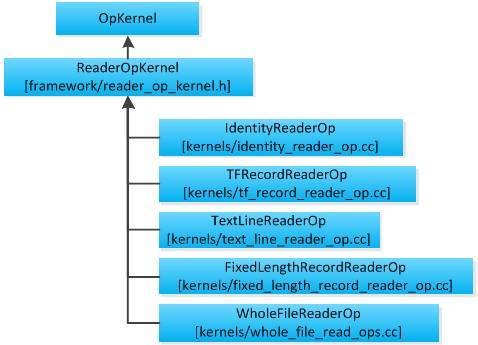
图 4 9 ReaderOp相关的UML视图
ReaderOpKernel子类必须重新定义成员函数SetReaderFactory实现对应的数据读取逻辑。TFRecordReaderOp的读取方法定义在TFRecordReader类中。
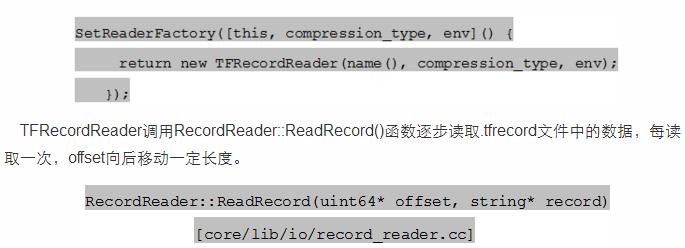
其中offset的计算方式。

作者简介:

姚健,毕业于中科院计算所网络数据实验室,毕业后就职于360天眼实验室,主要从事深度学习和增强学习相关研究工作。目前就职于腾讯MIG事业部,从事神经机器翻译工作。联系方式: yao_62995@163.com
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4498.html
摘要:为了进一步了解的逻辑,图对和进行了展开分析。另外,在命名空间中还隐式声明了控制依赖操作,这在章节控制流中相关说明。简述是高效易用的开源库,有效支持线性代数,矩阵和矢量运算,数值分析及其相关的算法。返回其中一块给用户,并将该内存块标识为占用。 3. TF 代码分析初步3.1 TF总体概述为了对TF有整体描述,本章节将选取TF白皮书[1]中的示例展开说明,如图 3 1所示是一个简单线性模型的TF...
摘要:简介读取数据共有三种方法当运行每步计算的时候,从获取数据。数据直接预加载到的中,再把传入运行。在中定义好文件读取的运算节点,把传入运行时,执行读取文件的运算,这样可以避免在和执行环境之间反复传递数据。本文讲解的代码。 简介 TensorFlow读取数据共有三种方法: Feeding:当TensorFlow运行每步计算的时候,从Python获取数据。在Graph的设计阶段,用place...
摘要:据公告称,和的包装库使用了不安全的函数来反序列化编码的机器学习模型。简单来看,序列化将对象转换为字节流。据悉,本次漏洞影响与版本,的到版本均受影响。作为解决方案,在宣布弃用之后,团队建议开发者以替代序列化,或使用序列化作为替代。 ...
摘要:近日它们交锋的战场就是动态计算图,谁能在这场战争中取得优势,谁就把握住了未来用户的流向。所以动态框架对虚拟计算图的构建速度有较高的要求。动态计算图问题之一的多结构输入问题的高效计 随着深度学习的发展,深度学习框架之间竞争也日益激烈,新老框架纷纷各显神通,想要在广大DeepLearner的服务器上占据一席之地。近日它们交锋的战场就是动态计算图,谁能在这场战争中取得优势,谁就把握住了未来用户的流...

阅读 2174·2019-08-29 16:53
阅读 2746·2019-08-29 16:07
阅读 2107·2019-08-29 13:13
阅读 3308·2019-08-26 13:57
阅读 1380·2019-08-26 13:31
阅读 2499·2019-08-26 13:22
阅读 1275·2019-08-26 11:43
阅读 2135·2019-08-23 17:14





