
摘要:联合查找算法是并查集数据结构一种应用。并查集是一种树型的数据结构,其保持着用于处理一些不相交集合的合并及查询问题。的特征是删除节点。目前就职于腾讯事业部,从事神经机器翻译工作。
5. TF - Graph模块
TF把神经网络模型表达成一张拓扑结构的Graph,Graph中的一个节点表示一种计算算子。Graph从输入到输出的Tensor数据流动完成了一个运算过程,这是对类似概率图、神经网络等连接式算法很好的表达,同时也是对Tensor + Flow的直观解释。
5.1 Graph视图
Tensorflow采用符号化编程,形式化为Graph计算图。Graph包含节点(Node)、边(Edge)、NameScope、子图(SubGraph),图 5 1是Graph的拓扑描述。
Ø 节点分为计算节点(Compute Node)、起始点(Source Node)、终止点(Sink Node)。起始点入度为0,终止点出度为0。
Ø NameScope为节点创建层次化的名称,图 3 4中的NameSpace类型节点就是其中一种体现。
Ø 边分为普通边和依赖边(Dependecy Edge)。依赖边表示对指定的计算节点有依赖性,必须等待指定的节点计算完成才能开始依赖边的计算。

图 5 1 Graph的拓扑描述
图 5 2是Graph的UML视图模型,左侧GraphDef类为protobuf中定义的graph结构,可将graph结构序列化和反序列化处理,用于模型保存、模型加载、分布式数据传输。右侧Graph类为/core/graph模块中定义的graph结构,完成graph相关操作,如构建(construct),剪枝(pruning)、划分(partitioning)、优化(optimize)、运行(execute)等。GraphDef类和Graph类可以相关转换,如图中中间部分描述,函数Graph::ToGraphDef()将Graph转换为GraphDef,函数ConvertGraphDefToGraph将GraphDef转换为Graph,借助这种转换就能实现Graph结构的网络传输。
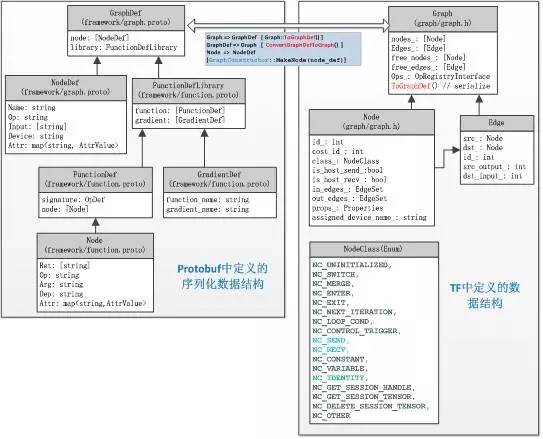
图 5 2 Graph的UML视图
Graph-UML图中还定义了Node和Edge。Node定义函数操作和属性信息,Edge连接源节点和目标节点。类NodeDef中定义了Op、Input、Device、Attr信息,其中Device可能是CPU、GPU设备,甚至是ARM架构的设备,说明Node是与设备绑定的。类FunctionDefLibrary主要是为了描述各种Op的运算,包括Op的正向计算和梯度计算。FunctionDef的定义描述见图 5 3。

图 5 3 FunctionDef的定义
图 5 4是FunctionDef举例,对MatMulGrad的梯度描述,其中包含函数参数定义、函数返回值定义、模板数据类型定义、节点计算逻辑。

图 5 4 FunctionDef举例:MatMulGrad
5.2 Graph构建
有向图(DAG)由节点和有向边组成。本章节主要讲述TF如何利用
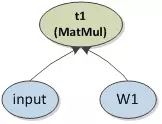
图 5 5 Graph简单示例
图 5 5中图计算表达式包含3个节点,2条边,描述为字符串形式如下。


5.3 Graph局部执行
Graph的局部执行特性允许使用者从任意一个节点输入(feed),并指定目标输出节点(fetch)。图 5 6是TF白皮书中描述Graph局部执行的图。[15]
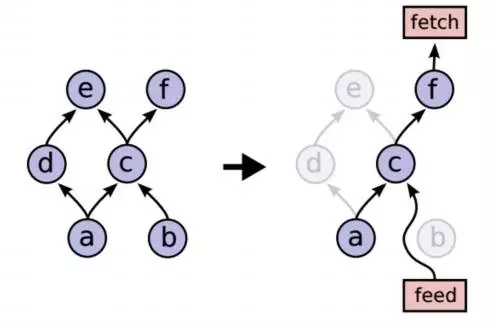
图 5 6 Graph局部执行

5.4 Graph设备分配
TF具有高度设备兼容性,支持X86和Arm架构,支持CPU、GPU运算,可运行于Linux、MacOS、Android和IOS系统。而且,TF的设备无关性特征在多设备分布式运行上也非常有用。
Graph中每个节点都分配有设备编号,表示该节点在相应设备上完成计算操作。用户既可以手动指定节点设备,也可以利用TF自动分配算法完成节点设备分配。设备自动算法需要权衡数据传输代价和计算设备的平衡,尽可能充分利用计算设备,减少数据传输代价,从而提高计算性能。
Graph设备分配用于管理多设备分布式运行时,哪些节点运行在哪个设备上。TF设备分配算法有两种实现算法,第一种是简单布放算法(Simple Placer),第二种基于代价模型(Cost Model)评估。简单布放算法按照指定规则布放,比较简单粗放,是早期版本的TF使用的模型,并逐步被代价模型方法代替。
5.4.1 Simple Placer算法
TF实现的Simple Placer设备分配算法使用union-find方法和启发式方法将部分不相交且待分配设备的Op节点集合合并,并分配到合适的设备上。
Union-find(联合-查找)算法是并查集数据结构一种应用。并查集是一种树型的数据结构,其保持着用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。Union-find定义了两种基本操作:Union和Find。
Ø Find:确定元素属于哪一个子集。它可以被用来确定两个元素是否属于同一子集。
Ø Union:将两个子集合并成同一个集合。即将一个集合的根节点的父指针指向另一个集合的根节点。
启发式算法(Heuristic Algorithm)定义了节点分配的基本规则。Simple Placer算法默认将起始点和终止点分配给CPU,其他节点中GPU的分配优先级高于CPU,且默认分配给GPU:0。启发式规则适用于以下两种场景:
Ø 对于符合GeneratorNode条件(0-indegree, 1-outdegree, not ref-type)的节点,让node与target_node所在device一致,参见图 5 7。

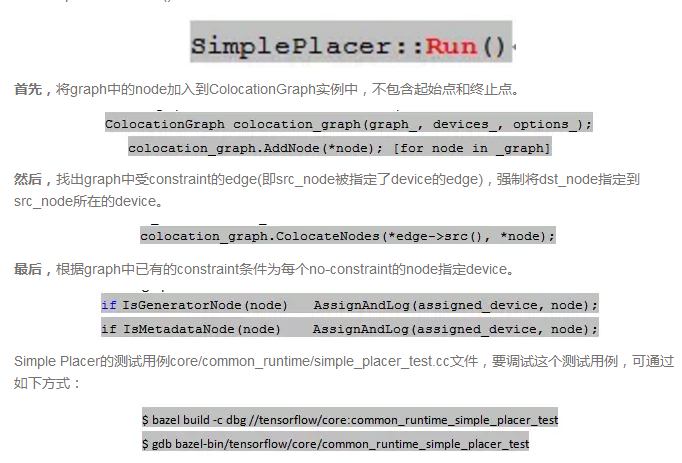
TF中Simple Placer的实现定义在文件core/common_runtime/simple_placer.cc。文件中主要定义了两个类:ColocationGraph和SimplePlacer。ColocationGraph类利用Union-find算法将节点子集合合并成一个节点集合,参考成员函数ColocationGraph:: ColocateNodes实现。SimplePlacer类实现节点分配过程,下面将主要介绍SimplePlacer:: Run()函数的实现过程。
5.4.2 代价模型
TF使用代价模型(Cost Model)会在计算流图生成的时候模拟每个device上的负载,并利用启发式策略估计device上的完成时间,最终找出预估时间较低的graph设备分配方案。[1]
Cost model预估时间的方法有两种:
Ø 使用启发式的算法,通过把输入和输出的类型以及tensor的大小输入进去,得到时间的预估
Ø 使用模拟的方法,对图的计算进行一个模拟,得到各个计算在其可用的设备上的时间。
启发式策略会根据如下数据调整device的分配:节点任务执行的总时间;单个节点任务执行的累计时间;单个节点输出数据的尺寸。

图 5 9代价模型UML视图
TF中代价模型的实现定义在文件core/graph/costmodel.cc和core/common_runtime/ costmodel_manager.cc,其UML视图参见图 5 9。
Cost model manager从graph创建cost model,再评估计算时间,如下。



Ø Function Inlining (函数内联)
函数内联处理可减少方法调用的成本。在TF中包含以下几种方法:
Ø RemoveListArrayConverter(g):” Rewrites _ListToArray and _ArrayToList to a set of Identity nodes”.
Ø RemoveDeadNodes(g):删除DeatNode。DeatNode的特征是”not statefull, not _Arg, not reachable from _Retval”.
Ø RemoveIdentityNodes(g):删除Identity节点。如n2=Identity(n1) + Identity(n1); 优化后: n2=n1 + n1;
Ø FixupSourceAndSinkEdges(g):固定source和sink的边
Ø ExpandInlineFunctions(runtime, g):展开内联函数的嵌套调用
其中_ListToArray、_ArrayToList、_Arg、_Retval均在core/ops/function_ops.cc中定义。
Graph优化相关测试文件在common_runtime/function_test.cc,调试方法:

作者简介:

姚健,毕业于中科院计算所网络数据实验室,毕业后就职于360天眼实验室,主要从事深度学习和增强学习相关研究工作。目前就职于腾讯MIG事业部,从事神经机器翻译工作。联系方式: yao_62995@163.com
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4497.html
摘要:近日它们交锋的战场就是动态计算图,谁能在这场战争中取得优势,谁就把握住了未来用户的流向。所以动态框架对虚拟计算图的构建速度有较高的要求。动态计算图问题之一的多结构输入问题的高效计 随着深度学习的发展,深度学习框架之间竞争也日益激烈,新老框架纷纷各显神通,想要在广大DeepLearner的服务器上占据一席之地。近日它们交锋的战场就是动态计算图,谁能在这场战争中取得优势,谁就把握住了未来用户的流...
摘要:基准测试我们比较了和三款,使用的深度学习库是和,深度学习网络是和。深度学习库基准测试同样,所有基准测试都使用位系统,每个结果是次迭代计算的平均时间。 购买用于运行深度学习算法的硬件时,我们常常找不到任何有用的基准,的选择是买一个GPU然后用它来测试。现在市面上性能较好的GPU几乎都来自英伟达,但其中也有很多选择:是买一个新出的TITAN X Pascal还是便宜些的TITAN X Maxwe...

阅读 1860·2021-11-24 10:21
阅读 1293·2021-09-22 15:25
阅读 3215·2019-08-30 15:55
阅读 757·2019-08-30 15:54
阅读 3520·2019-08-30 14:20
阅读 1705·2019-08-30 14:06
阅读 681·2019-08-30 13:11
阅读 3207·2019-08-29 16:43



