
摘要:基于深度学习的,主要是基于单张低分辨率的重建方法,即。而基于深度学习的通过神经网络直接学习分辨率图像到高分辨率图像的端到端的映射函数。
超分辨率技术(Super-Resolution)是指从观测到的低分辨率图像重建出相应的高分辨率图像,在监控设备、卫星图像和医学影像等领域都有重要的应用价值。SR可分为两类:从多张低分辨率图像重建出高分辨率图像和从单张低分辨率图像重建出高分辨率图像。基于深度学习的SR,主要是基于单张低分辨率的重建方法,即Single Image Super-Resolution (SISR)。
SISR是一个逆问题,对于一个低分辨率图像,可能存在许多不同的高分辨率图像与之对应,因此通常在求解高分辨率图像时会加一个先验信息进行规范化约束。在传统的方法中,这个先验信息可以通过若干成对出现的低-高分辨率图像的实例中学到。而基于深度学习的SR通过神经网络直接学习分辨率图像到高分辨率图像的端到端的映射函数。
本文介绍几个较新的基于深度学习的SR方法,包括SRCNN,DRCN, ESPCN,VESPCN和SRGAN等。
1.SRCNN
Super-Resolution Convolutional Neural Network (SRCNN, PAMI 2016, http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html)是较早地提出的做SR的卷积神经网络。该网络结构十分简单,仅仅用了三个卷积层。
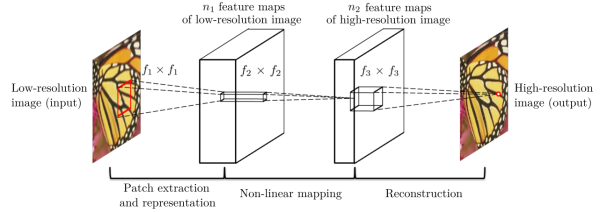
该方法对于一个低分辨率图像,先使用双三次(bicubic)插值将其放大到目标大小,再通过三层卷积网络做非线性映射,得到的结果作为高分辨率图像输出。作者将三层卷积的结构解释成与传统SR方法对应的三个步骤:图像块的提取和特征表示,特征非线性映射和最终的重建。
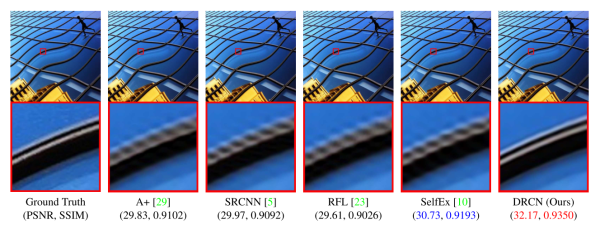
三个卷积层使用的卷积核的大小分为为9x9, 1x1和5x5,前两个的输出特征个数分别为64和32. 该文章分别用Timofte数据集(包含91幅图像)和ImageNet大数据集进行训练。相比于双三次插值和传统的稀疏编码方法,SRCNN得到的高分辨率图像更加清晰,下图是一个放大倍数为3的例子。
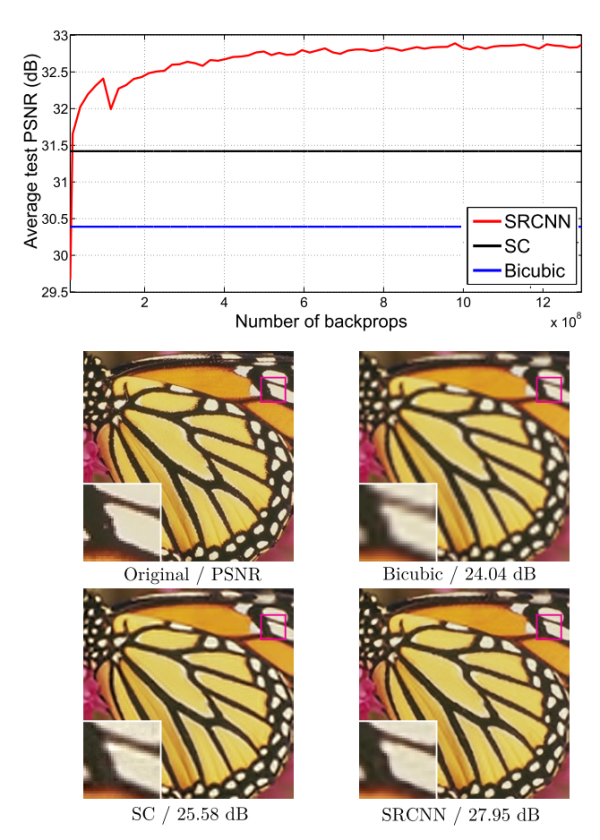
对SR的质量进行定量评价常用的两个指标是PSNR(Peak Signal-to-Noise Ratio)和SSIM(Structure Similarity Index)。这两个值越高代表重建结果的像素值和金标准越接近,下图表明,在不同的放大倍数下,SRCNN都取得比传统方法好的效果。

2.DRCN
SRCNN的层数较少,同时感受野也较小(13x13)。DRCN (Deeply-Recursive Convolutional Network for Image Super-Resolution, CVPR 2016, http://cv.snu.ac.kr/research/DRCN/)提出使用更多的卷积层增加网络感受野(41x41),同时为了避免过多网络参数,该文章提出使用递归神经网络(RNN)。网络的基本结构如下:

与SRCNN类似,该网络分为三个模块,第一个是Embedding network,相当于特征提取,第二个是Inference network, 相当于特征的非线性变换,第三个是Reconstruction network,即从特征图像得到最后的重建结果。其中的Inference network是一个递归网络,即数据循环地通过该层多次。将这个循环进行展开,就等效于使用同一组参数的多个串联的卷积层,如下图所示:

其中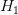 到
到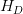 是D个共享参数的卷积层。DRCN将每一层的卷积结果都通过同一个Reconstruction Net得到一个重建结果,从而共得到D个重建结果,再把它们加权平均得到最终的输出。另外,受到ResNet的启发,DRCN通过skip connection将输入图像与
是D个共享参数的卷积层。DRCN将每一层的卷积结果都通过同一个Reconstruction Net得到一个重建结果,从而共得到D个重建结果,再把它们加权平均得到最终的输出。另外,受到ResNet的启发,DRCN通过skip connection将输入图像与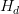 的输出相加后再作为Reconstruction Net的输入,相当于使Inference Net去学习高分辨率图像与低分辨率图像的差,即恢复图像的高频部分。
的输出相加后再作为Reconstruction Net的输入,相当于使Inference Net去学习高分辨率图像与低分辨率图像的差,即恢复图像的高频部分。
实验部分,DRCN也使用了包含91张图像的Timofte数据集进行训练。得到的效果比SRCNN有了较大提高。
3.ESPCN
在SRCNN和DRCN中,低分辨率图像都是先通过上采样插值得到与高分辨率图像同样的大小,再作为网络输入,意味着卷积操作在较高的分辨率上进行,相比于在低分辨率的图像上计算卷积,会降低效率。 ESPCN(Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network,CVPR 2016, https://github.com/Tetrachrome/subpixel)提出一种在低分辨率图像上直接计算卷积得到高分辨率图像的高效率方法。
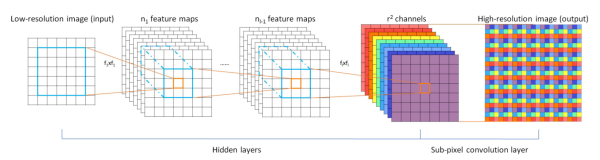
ESPCN的核心概念是亚像素卷积层(sub-pixel convolutional layer)。如上图所示,网络的输入是原始低分辨率图像,通过两个卷积层以后,得到的特征图像大小与输入图像一样,但是特征通道为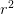 (
( 是图像的目标放大倍数)。将每个像素的
是图像的目标放大倍数)。将每个像素的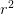 个通道重新排列成一个r x r的区域,对应于高分辨率图像中的一个r x r大小的子块,从而大小为
个通道重新排列成一个r x r的区域,对应于高分辨率图像中的一个r x r大小的子块,从而大小为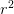 x H x W的特征图像被重新排列成1 x rH x rW大小的高分辨率图像。这个变换虽然被称作sub-pixel convolution, 但实际上并没有卷积操作。
x H x W的特征图像被重新排列成1 x rH x rW大小的高分辨率图像。这个变换虽然被称作sub-pixel convolution, 但实际上并没有卷积操作。
通过使用sub-pixel convolution, 图像从低分辨率到高分辨率放大的过程,插值函数被隐含地包含在前面的卷积层中,可以自动学习到。只在最后一层对图像大小做变换,前面的卷积运算由于在低分辨率图像上进行,因此效率会较高。

重建效果上,用PSNR指标看来ESPCN比SRCNN要好一些。对于1080HD的视频图像,做放大四倍的高分辨率重建,SRCNN需要0.434s而ESPCN只需要0.029s。

4. VESPCN
在视频图像的SR问题中,相邻几帧具有很强的关联性,上述几种方法都只在单幅图像上进行处理,而VESPCN( Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation, arxiv 2016)提出使用视频中的时间序列图像进行高分辨率重建,并且能达到实时处理的效率要求。其方法示意图如下,主要包括三个方面:

一是纠正相邻帧的位移偏差,即先通过Motion estimation估计出位移,然后利用位移参数对相邻帧进行空间变换,将二者对齐。二是把对齐后的相邻若干帧叠放在一起,当做一个三维数据,在低分辨率的三维数据上使用三维卷积,得到的结果大小为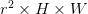 。三是利用ESPCN的思想将该卷积结果重新排列得到大小为
。三是利用ESPCN的思想将该卷积结果重新排列得到大小为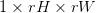 的高分辨率图像。
的高分辨率图像。
Motion estimation这个过程可以通过传统的光流算法来计算,DeepMind 提出了一个Spatial Transformer Networks, 通过CNN来估计空间变换参数。VESPCN使用了这个方法,并且使用多尺度的Motion estimation:先在比输入图像低的分辨率上得到一个初始变换,再在与输入图像相同的分辨率上得到更较精确的结果,如下图所示:
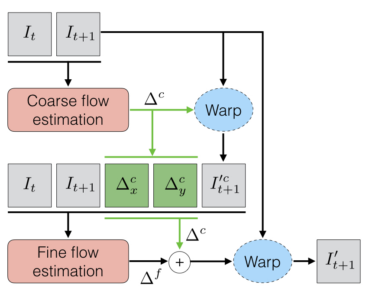
由于SR重建和相邻帧之间的位移估计都通过神经网路来实现,它们可以融合在一起进行端到端的联合训练。为此,VESPCN使用的损失函数如下:
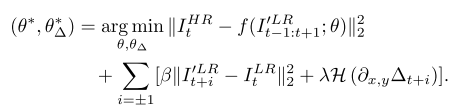
第一项是衡量重建结果和金标准之间的差异,第二项是衡量相邻输入帧在空间对齐后的差异,第三项是平滑化空间位移场。下图展示了使用Motion Compensation 后,相邻帧之间对得很整齐,它们的差值图像几乎为0.
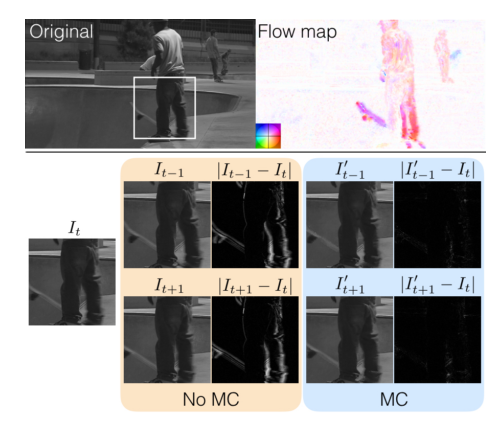
从下图可以看出,使用了Motion Compensation,重建出的高分辨率视频图像更加清晰。

5.SRGAN
SRGAN (Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, https://arxiv.org/abs/1609.04802, 21 Nov, 2016)将生成式对抗网络(GAN)用于SR问题。其出发点是传统的方法一般处理的是较小的放大倍数,当图像的放大倍数在4以上时,很容易使得到的结果显得过于平滑,而缺少一些细节上的真实感。因此SRGAN使用GAN来生成图像中的细节。
传统的方法使用的代价函数一般是最小均方差(MSE),即
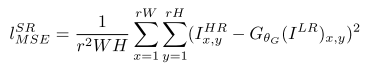
该代价函数使重建结果有较高的信噪比,但是缺少了高频信息,出现过度平滑的纹理。SRGAN认为,应当使重建的高分辨率图像与真实的高分辨率图像无论是低层次的像素值上,还是高层次的抽象特征上,和整体概念和风格上,都应当接近。整体概念和风格如何来评估呢?可以使用一个判别器,判断一副高分辨率图像是由算法生成的还是真实的。如果一个判别器无法区分出来,那么由算法生成的图像就达到了以假乱真的效果。
因此,该文章将代价函数改进为
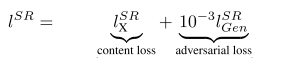
第一部分是基于内容的代价函数,第二部分是基于对抗学习的代价函数。基于内容的代价函数除了上述像素空间的最小均方差以外,又包含了一个基于特征空间的最小均方差,该特征是利用VGG网络提取的图像高层次特征:
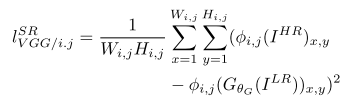
对抗学习的代价函数是基于判别器输出的概率:
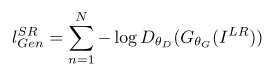
其中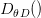 是一个图像属于真实的高分辨率图像的概率。
是一个图像属于真实的高分辨率图像的概率。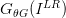 是重建的高分辨率图像。SRGAN使用的生成式网络和判别式网络分别如下:
是重建的高分辨率图像。SRGAN使用的生成式网络和判别式网络分别如下:
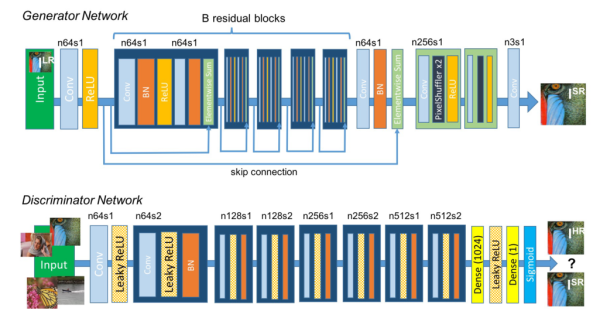
该方法的实验结果如下

从定量评价结果上来看,PSNR和SSIM这两个指标评价的是重建结果和金标准在像素值空间的差异。SRGAN得到的评价值不是较高。但是对于MOS(mean opinion score)的评价显示,SRGAN生成的高分辨率图像看起来更真实。

参考资料
1, Dong, Chao, et al. "Image super-resolution using deep convolutional networks." IEEE transactions on pattern analysis and machine intelligence 38.2 (2016): 295-307.
2, Kim, Jiwon, Jung Kwon Lee, and Kyoung Mu Lee. "Deeply-recursive convolutional network for image super-resolution." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
3, Shi, Wenzhe, et al. "Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
4, Caballero, Jose, et al. "Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation." arXiv preprint arXiv:1611.05250 (2016).
5, Jaderberg, Max, Karen Simonyan, and Andrew Zisserman. "Spatial transformer networks." Advances in Neural Information Processing Systems. 2015.
6, Ledig, Christian, et al. "Photo-realistic single image super-resolution using a generative adversarial network." arXiv preprint arXiv:1609.04802 (2016).
7,深度对抗学习在图像分割和超分辨率中的应用
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4487.html
摘要:深度学习已经在图像分类检测分割高分辨率图像生成等诸多领域取得了突破性的成绩。另一个问题是深度学习的模型比如卷积神经网络有时候并不能很好地学到训练数据中的一些特征。本文通过最近的几篇文章来介绍它在图像分割和高分辨率图像生成中的应用。 深度学习已经在图像分类、检测、分割、高分辨率图像生成等诸多领域取得了突破性的成绩。但是它也存在一些问题。首先,它与传统的机器学习方法一样,通常假设训练数据与测试数...
摘要:在这种场景下网易云信可以在接收的终端上通过超分辨率技术,恢复视频质量,极大地提升了移动端用户的体验。云信通过人工智能深度学习将低分辨率视频重建成高分辨率视频模糊图像视频瞬间变高清,为移动端为用户带来极致视频体验。 泛娱乐应用成为主流,社交与互动性强是共性,而具备这些特性的产品往往都集中在直播、短视频、图片分享社区等社交化娱乐产品,而在这些产品背后的黑科技持续成为关注重点,网易云信在网易...
摘要:音频超分辨率旨在重建一个以较低分辨率波形作为输入的高分辨率音频波形。由于受到深度学习成功应用于图像超分辨率的启发,我最近致力于使用深层神经网络来完成原始音频波形的上采样。上采样块使用子像素卷积,其沿着一个维度重新排列信息以扩展其他维度。 音频超分辨率旨在重建一个以较低分辨率波形作为输入的高分辨率音频波形。在诸如流式音频和音频恢复之类的领域中,这种类型的上采样存在着若干种潜在应用。一个传统的解...
摘要:深度学习方法是否已经强大到可以使科学分析任务产生最前沿的表现在这篇文章中我们介绍了从不同科学领域中选择的一系列案例,来展示深度学习方法有能力促进科学发现。 深度学习在很多商业应用中取得了前所未有的成功。大约十年以前,很少有从业者可以预测到深度学习驱动的系统可以在计算机视觉和语音识别领域超过人类水平。在劳伦斯伯克利国家实验室(LBNL)里,我们面临着科学领域中最具挑战性的数据分析问题。虽然商业...

阅读 3295·2021-09-23 11:55
阅读 2658·2021-09-13 10:33
阅读 1689·2019-08-30 15:54
阅读 3112·2019-08-30 15:54
阅读 2378·2019-08-30 10:59
阅读 2387·2019-08-29 17:08
阅读 1819·2019-08-29 13:16
阅读 3606·2019-08-26 12:25





