
摘要:本文将分享一些自己关于深度学习模型调试技巧的总结思考以为主。不过以卷积神经网络为代表的深层神经网络一直被诟病,这对于模型在工业界的应用推广还是带来了一定的阻碍。
作者杨军,从事大规模机器学习系统研发及应用相关工作。
本文将分享一些自己关于深度学习模型调试技巧的总结思考(以CNN为主)。
最近因为一些需要,参与了一些CNN建模调参的工作,出于个人习性,我并不习惯于通过单纯的trial-and-error的方式来调试经常给人以”black-box”印象的Deep Learning模型。所以在工作推进过程中,花了一些时间去关注了深度学习模型调试以及可视化的资料(可视化与模型调试存在着极强的联系,所以在后面我并没有对这两者加以区分),这篇文章也算是这些工作的一个阶段性总结。
这里总结的内容,对于模型高手来说,应该说都是基本的know-how了。
我本人是计算机体系结构专业出身,中途转行做算法策略,所以实际上我倒是在大规模机器学习系统的开发建设以及训练加速方面有更大的兴趣和关注。不过机器学习系统这个领域跟常规系统基础设施(比如Redis/LevelDB以及一些分布式计算的基础设施等)还有所区别,虽然也可以说是一种基础设施,但是它跟跑在这个基础设施上的业务问题有着更强且直接的联系,所以我也会花费一定的精力来关注数据、业务建模的技术进展和实际问题场景。
说得通俗一些,对自己服务的业务理解得更清晰,才可能设计开发出更好的算法基础设施。
另外在进入文章主体之前想声明的是,这篇文章对于Deep Learning的入门者参考价值会更高,对于Deep Learning老手,只期望能聊作帮助大家技术总结的一个余闲读物而已。
文章的主要内容源于Stanford CS231n Convolutional Neural Networks for Visual Recognition课程[1]里介绍的一些通过可视化手段,调试理解CNN网络的技巧,在[1]的基础上我作了一些沿展阅读,算是把[1]的内容进一步丰富系统化了一下。限于时间精力,我也没有能够把里面提到的所有调试技巧全部进行尝试,不过在整理这篇文章的时候,我还是参考了不止一处文献,也结合之前以及最近跟一些朋友的技术交流沟通,对这些方法的有效性我还是有着很强的confidence。
1、Visualize Layer Activations
通过将神经网络隐藏层的激活神经元以矩阵的形式可视化出来,能够让我们看到一些有趣的insights。
在[8]的头部,嵌入了一个web-based的CNN网络的demo,可以看到每个layer activation的可视化效果。

在[14]里为几种不同的数据集提供了CNN各个layer activation的可视化效果示例,在里头能够看到CNN模型在Mnist/CIFAR-10这几组数据集上,不同layer activation的图形化效果。
原则上来说,比较理想的layer activation应该具备sparse和localized的特点。
如果训练出的模型,用于预测某张图片时,发现在卷积层里的某个feature map的activation matrix可视化以后,基本跟原始输入长得一样,基本就表明出现了一些问题,因为这意味着这个feature map没有学到多少有用的东西。
2、Visualize Layer Weights
除了可视化隐藏层的activation以外,可视化隐藏层的模型weight矩阵也能帮助我们获得一些insights。
这里是AlexNet的第一个卷积层的weight可视化的示例:

通常,我们期望的良好的卷积层的weight可视化出来会具备smooth的特性(在上图也能够明显看到smooth的特点),参见下图(源于[13]):

这两张图都是将一个神经网络的第一个卷积层的filter weight可视化出来的效果图,左图存在很多的噪点,右图则比较平滑。出现左图这个情形,往往意味着我们的模型训练过程出现了问题。
3、Retrieving Images That Maximally Activate a Neuron
为了理解3提到的方法,需要先理解CNN里Receptive Field的概念,在[5][6]里关于Receptive Field给出了直观的介绍:

如果用文字来描述的话,就是对应于卷积核所生成的Feature Map里的一个neuron,在计算这个neuron的标量数值时,是使用卷积核在输入层的图片上进行卷积计算得来的,对于Feature Map的某个特定neuron,用于计算该neuron的输入层数据的local patch就是这个neuron的receptive field。
而对于一个特定的卷积层的Feature Map里的某个神经元,我们可以找到使得这个神经元的activation较大的那些图片,然后再从这个Feature Map neuron还原到原始图片上的receptive field,即可以看到是哪张图片的哪些region maximize了这个neuron的activation。在[7]里使用这个技巧,对于某个pooling层的输出进行了activation maximization可视化的工作:

不过,在[9]里,关于3提到的方法进行了更为细致的研究,在[9]里,发现,通过寻找maximizing activation某个特定neuron的方法也许并没有真正找到本质的信息。因为即便是对于某一个hidden layer的neurons进行线性加权,也同样会对一组图片表现出相近的semantic亲和性,并且,这个发现在不同的数据集上得到了验证。
如下面在MNIST和ImageNet数据集上的观察:




4.Embedding the Hidden Layer Neurons with t-SNE
这个方法描述起来比较直观,就是通过t-SNE[10]对隐藏层进行降维,然后以降维之后的两维数据分别作为x、y坐标(也可以使用t-SNE将数据降维到三维,将这三维用作x、y、z坐标,进行3d clustering),对数据进行clustering,人工review同一类图片在降维之后的低维空间里是否处于相邻的区域。t-SNE降维以后的clustering图往往需要在较高分辨率下才能比较清楚地看到效果,这里我没有给出引用图,大家可以自行前往这里[15]里看到相关的demo图。
使用这个方法,可以让我们站在一个整体视角观察模型在数据集上的表现。
5.Occluding Parts of the Image
这个方法在[11]里被提出。我个人非常喜欢这篇文章,因为这篇文章写得非常清晰,并且给出的示例也非常直观生动,是那种非常适合推广到工业界实际应用场景的论文,能够获得ECCV 2014 best paper倒也算在意料之中。
在[11]里,使用了[12]里提出的Deconvolutional Network,对卷积层形成的feature map进行reconstruction,将feature map的activation投影到输入图片所在的像素空间,从而提供了更直观的视角来观察每个卷积层学习到了什么东西,一来可以帮助理解模型;二来可以指导模型的调优设计。
[11]的工作主要是在AlexNet这个模型上做的,将Deconvolutional Network引入到AlexNet模型以后的大致topology如下:
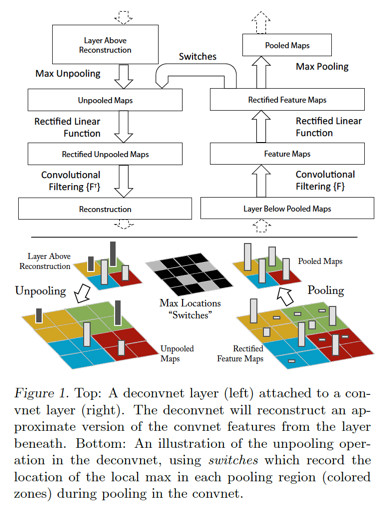
上图里,右边是正常的卷积神经网络,左边是Deconv Net,Deconv Net的输入是卷积神经网络的某个卷积层/pooling层的输出,另外,在Deconv Net与右边的卷积神经网络之间存在一个Switches连接通道,用于执行Deconv net里的Unpooling操作。注意上图的一个细节,Deconv Net的Unpooling操作,实际上是pooling操作的一个近似逆函数,而非较精确逆函数。
在AlexNet模型上使用Deconv Net对feature map进行input image space投影的效果示例如下:

从上面这个示例图里能够看得出来,不同的feature map,使用Deconv Net进行reconstruction,会投影出不同描述粒度的图片,比如低层的layer reconstruction出来的会是边缘性质的图像,而高层的layer reconstruction出来的则可能会是狗的脸部,计算器的轮廓等更general性质的图像。
另外,通过Deconv Net还可以观察训练过程中,feature map的演化情况,基本的作法就是将每个卷积层里,activation较大的feature map使用Deconv Net进行reconstruction,以epoch为时间粒度,观察这些feature map reconstructed image的变化趋势,比如下图:

能够看到,低层的feature map比较快就会收敛,而高层的feature map则需要较长epoch的训练时长才会收敛。
接下来回到[11]里提出的"Occluding Parts of the Image”的方法,这个方法描述起来并不复杂:对于一张输入图片,使用一个小尺寸的灰度方块图作为掩模,对该原始图片进行遍历掩模,每作一次掩模,计算一下CNN模型对这张掩模后图片的分类预测输出,同时,找到一个在训练集上activation较大的feature map,每作一次掩模,记录下来以掩模图片作为输入数据之后的feature map矩阵,将所有掩模所产生的这些feature map矩阵进行elementwise相加,就可以观察到掩模图片的不同区域对分类预测结果以及feature map的activation value的影响。示例图如下:

上图的第一列是原始图片。
第二列是在训练集上选出了layer 5上的activation行为最显著的一个feature map之后,对第一列的原始图片使用一个灰度小色块进行occluding之后,所生成的该feature map的activation value进行sum up之后的可视图。
第三列是这个feature map(这个是在没有occluding的image上应用CNN模型生成的feature map)使用Deconv Net投影到input image space上的图像。能够看得出来,第三列所reconstruct出的image与第二列中受occluding操作影响较大的区域明显是相重合的。
最后说一下我的感受,卷积神经网络自从2012年以AlexNet模型的形态在ImageNet大赛里大放异彩之后,就成为了图像识别领域的标配,甚至现在文本和语音领域也开始在使用卷积神经网络进行建模了。不过以卷积神经网络为代表的深层神经网络一直被诟病“black-box”,这对于DL模型在工业界的应用推广还是带来了一定的阻碍。
对于”black-box”这个说法,一方面,我觉得确实得承认DL这种model跟LR、GBDT这些shallow model相比,理解、调试的复杂性高了不少。想像一下,理解一个LR或是GBDT模型的工作机理,一个没有受到过系统机器学习训练的工程师,只要对LR或GBDT的基本概念有一定认识,也大致可以通过ad-hoc的方法来进行good case/bad case的分析了。而CNN这样的模型,理解和调试其的技巧,则往往需要资深的专业背景人士来提出,并且这些技巧也都还存在一定的局限性。
对于LR模型来说,我们可以清晰地描述一维特征跟目标label的关系(即便存在特征共线性或是交叉特征,也不难理解LR模型的行为表现),而DL模型,即便这几年在模型的可解释性、调试技巧方面有不少研究人员带来了新的进展,在我来看也还是停留在一个相对”rough”的控制粒度,对技巧的应用也还是存在一定的门槛。
另一方面,我们应该也对学术界、工业界在DL模型调试方面的进展保持一定的关注。我自己的体会,DL模型与shallow model的应用曲线相比,目前还是存在一定的差异的。从网上拉下来一个pre-trained好的模型,应用在一个跟pre-trained模型相同的应用场景,能够快速地拿到7,80分的收益,但是,如果应用场景存在差异,或者对模型质量要求更高,后续的模型优化往往会存在较高的门槛(这也是模型调试、可视化技巧发挥用武之地的地方),而模型离线tune好以后,布署到线上系统的overhead也往往更高一些,不论是在线serving的latency要求(这也催生了一些新的商业机会,比如Nervana和寒武纪这样的基于软硬件协同设计技术的神经网络计算加速公司),还是对memory consumption的需求。
以前有人说过一句话“现在是个人就会在自己的简历上写自己懂Deep Learning,但其实只有1%的人知道怎样真正design一个DL model,剩下的只是找来一个现成的DL model跑一跑了事”。这话听来刺耳,但其实有几分道理。
回到我想表达的观点,一方面我们能够看到DL model应用的门槛相较于shallow model要高,另一方面能够看到这个领域的快速进展。所以对这个领域的技术进展保持及时的跟进,对于模型的设计调优以及在业务中的真正应用会有着重要的帮助。
像LR、GBDT这种经典的shallow model那样,搞明白基本建模原理就可以捋起袖子在业务中开搞,不需要再分配太多精力关注模型技术的进展的工作方式,在当下的DL建模场景,我个人认为这种技术工作的模式并不适合。也许未来随着技术、工具平台的进步,可以把DL也做得更为易用,到那时,使用DL建模的人也能跟现在使用shallow model一样,可以从模型技术方面解放出更多精力,用于业务问题本身了。
References:
[1]. Visualizing what ConvNets Learn. CS231n Convolutional Neural Networks for Visual Recognition
CS231n Convolutional Neural Networks for Visual Recognition
[2]. Matthew Zeiler. Visualizing and Understanding Convolutional Networks. Visualizing and Understanding Convolutional Networks.
[3]. Daniel Bruckner. deepViz: Visualizing Convolutional Neural Networks for Image Classification.
[4]. ConvNetJS MNIST Demo. ConvNetJS MNIST demo
[5]. Receptive Field. CS231n Convolutional Neural Networks for Visual Recognition
[6]. Receptive Field of Neurons in LeNet. deep learning
[7]. Ross Girshick. Rich feature hierarchies for accurate object detection and semantic segmentation
Tech report. Arxiv, 2011.
[8]. CS231n: Convolutional Neural Networks for Visual Recognition. Stanford University CS231n: Convolutional Neural Networks for Visual Recognition
[9]. Christian Szegedy. Intriguing properties of neural networks. Arxiv, 2013.
[10]. t-SNE. t-SNE – Laurens van der Maaten
[11]. Matthew D.Zeiler. Visualizing and Understanding Convolutional Networks. Arxiv, 2011.
[12]. Matthew D.Zeiler. Adaptive Deconvolutional Networks for Mid and High Level Feature Learning, ICCV 2011.
[13]. Neural Networks Part 3: Learning and Evaluation. CS231n Convolutional Neural Networks for Visual Recognition
[14]. ConvNetJS---Deep Learning in Your Browser.ConvNetJS: Deep Learning in your browser
[15]. Colah. Visualizing MNIST: An Exploration of Dimensionality Reduction.
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4485.html
摘要:特征匹配改变了生成器的损失函数,以最小化真实图像的特征与生成的图像之间的统计差异。我们建议读者检查上使用的损失函数和相应的性能,并通过实验验证来设置。相反,我们可能会将注意力转向寻找在生成器性能不佳时不具有接近零梯度的损失函数。 前 言GAN模型相比较于其他网络一直受困于三个问题的掣肘: 1. 不收敛;模型训练不稳定,收敛的慢,甚至不收敛; 2. mode collapse; 生成器产生的...
摘要:可以参见以下相关阅读创造更多数据上一小节说到了有了更多数据,深度学习算法通常会变的更好。 导语我经常被问到诸如如何从深度学习模型中得到更好的效果的问题,类似的问题还有:我如何提升准确度如果我的神经网络模型性能不佳,我能够做什么?对于这些问题,我经常这样回答,我并不知道确切的答案,但是我有很多思路,接着我会列出了我所能想到的所有或许能够给性能带来提升的思路。为避免一次次罗列出这样一个简单的列表...
摘要:二阶动量的出现,才意味着自适应学习率优化算法时代的到来。自适应学习率类优化算法为每个参数设定了不同的学习率,在不同维度上设定不同步长,因此其下降方向是缩放过的一阶动量方向。 说到优化算法,入门级必从SGD学起,老司机则会告诉你更好的还有AdaGrad / AdaDelta,或者直接无脑用Adam。可是看看学术界的paper,却发现一众大神还在用着入门级的SGD,最多加个Moment或者Nes...

阅读 2258·2023-04-25 14:56
阅读 2712·2021-11-16 11:44
阅读 2796·2021-09-22 15:00
阅读 1961·2019-08-29 16:55
阅读 2240·2019-08-29 14:04
阅读 2385·2019-08-29 11:23
阅读 3738·2019-08-26 10:46
阅读 1966·2019-08-22 18:43





