
摘要:实验蒙特祖玛的复仇蒙特祖玛的复仇是上最难的游戏之一。图蒙特祖玛的复仇的学习曲线在第一个房间中学习的子目标的可视化呈现。结论如何创建一个能够学习将其行为分解为有意义的基元,然后重新利用它们以更有效地获取新的行为,这是一个长期存在的研究问题。
论文题目:分层强化学习的 FeUdal 网络(FeUdal Networks for Hierarchical Reinforcement Learning)
论文下载地址:https://arxiv.org/pdf/1703.01161.pdf

摘要
我们提出 FeUdal 网络(FuNs) :一种用于分层强化学习的新架构。我们的方法受到 Dayan 和 Hinton 提出的 feudal 强化学习方法的启发,通过在多个层上解耦端到端学习获取能力和效用,允许网络利用不同的时间分辨率。我们的框架使用一个 Manager 模块和一个 Worker 模块。Manager 在较低的时间分辨率下工作,并设置传递给 Worker,由 Worker 实行的抽象目标。Worker 在环境的每个点上都生成原始的动作。FuN 的解耦结构有几个好处:除了利用很长时间尺度的信用分配,它还鼓励与 Manager 设置的不同目标相关的子策略的出现。这些特性允许 FuN 在涉及长期信用分配或记忆的任务上显著优于基线代理(baseline agent)。我们论证了我们提出的系统在 ATARI 套件和 3D DeemMind Lab 环境下执行一系列任务的性能。
模型
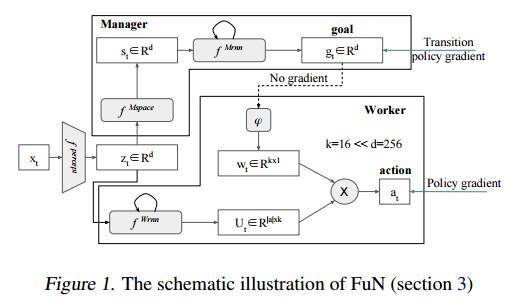
FuN 是什么呢?FuN 是一个模块化的神经网络,由两个模块组成,分别是 Worker 模块和 Manager 模块。Manager 模块在内部计算潜在的状态表示 st,然后输出目标向量 gt。Worker 模块根据对外部的观察、自己的状态以及 Manager 的目标产生行动。Manager 和 Worker 共享一个感知模块,该模块从环境 xt 获取观察并计算一个共享的中间表示 zt。Manager 的目标 gt 使用一个近似的过渡策略梯度进行训练。这是一种特别有效的策略梯度训练方式,利用了 Worker 的行为最终会与设置的目标方向一致的知识。然后,Worker 通过内在激励进行训练,以产生能达到这些目标方向的动作。图1描绘了整体的设计,以下是公式:
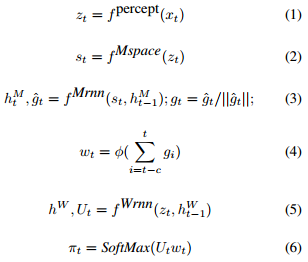
其中,Manager 和 Worker 都是回归的。这里 hM 和 hW 分别对应 Manager 和 Worker 的内部状态。线性变换 φ 将目标 gt 映射到嵌入向量 wt∈Rk,然后通过乘积与矩阵 Ut(Worker 输出的)组合以产生策略π,即相对于原始动作的概率向量。
有关目标嵌入和如何训练 FuN 的详细信息,请参见论文 3.1~3.3 节。架构细节参见论文第4节。
实验
我们的实验的目的是证明 FuN 能学习非平凡(non-trivial),有帮助,而且可解释的子策略和子目标,以及验证该架构的组件。论文先描述了实验设置的技术细节,然后在 5.1 节介绍 FuN 在公认很难的 ATARI 游戏《蒙特祖玛的复仇》(Montezuma’s revenge)上的表现,5.2节比较了在更多的 ATARI 游戏上 FuN 模型和 LSTM 基线的差异,利用了不同的贴现因子(discount factors)和 BPTT 长度。5.3 节呈现了 FuN 在 3D 环境中的一组视觉记忆任务的结果。5.4 节介绍了 FuN 的一项消融研究,验证了我们的设计选择。
实验1:《蒙特祖玛的复仇》(Montezuma’s revenge)
《蒙特祖玛的复仇》是 ALE 上最难的游戏之一(Bellemare et al., 2012)。这个游戏有致命的陷阱和稀疏的奖励,对代理来说很具挑战性。我们不得不扩大并加强了对 LSTM 基线的超参数搜索(hyper-parameter search),以发现模型的进展。 我们对 LSTM 基线的多个不同超参数配置进行了实验,并找到了较好的配置。
我们注意到,FuN 学习的开始时间更早,而且获得了更高的分数。LSTM 需要 > 300 epochs 才达到400分,对应于解决第一个房间(取钥匙,开门);它一直停留在这个分数,直到大约 900 epochs 时才开始进一步探索。FuN 则在解决第一个房间后不到 200 epochs 就立即开始进一步的探索,最终进入了其他几个房间,得分高达 2600 分。
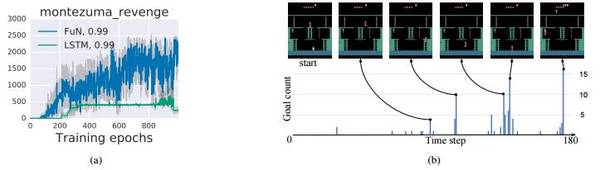
图2. a)蒙特祖玛的复仇的学习曲线;b)FuN 在第一个房间中学习的子目标的可视化呈现。
实验2:ATARI 游戏

图3:在 See Quest 游戏上学习的子策略的可视化呈现。我们对随机目标进行了抽样,并将其作为一个恒定条件喂入 Worker,然后记录它的行为。我们只过滤了船只的图像并平均帧,得到代理空间位置的热图。从左到右:i)游戏的示例帧;ii)由 LSTM 基线学习的策略;iii)由 FuN 学习的完整策略,随后是一组不同的子策略。注意子策略集中在可玩空间的不同区域方式。子政策3用于游上海面获得氧气。
实验3:迷宫游戏上的记忆
DeepMind Lab 是从 OpenArena 扩展的第一人称 3D 游戏平台。它是一个视觉上较为复杂的 3D 环境,代理的操作对应移动和方向。我们使用4个不同的水平来测试代理的长期信用分配(long-term credit assignment)和视觉记忆:水迷宫(Water maze),T型迷宫(T-maze),和 Non-match。
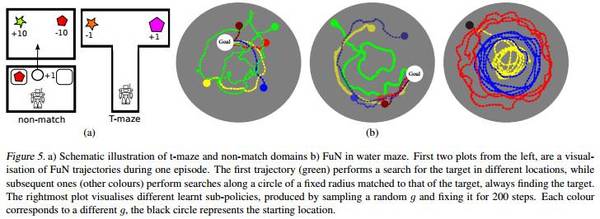
图5:a)T-maze 和 Non-match 域;b)水迷宫中的 FuN 的示意图。
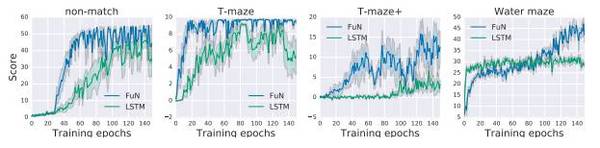
图6:迷宫游戏上记忆任务的训练曲线。
结论
如何创建一个能够学习将其行为分解为有意义的基元(primitives),然后重新利用它们以更有效地获取新的行为,这是一个长期存在的研究问题。这个问题的解决方案或许会是具有通用智力和能力的智能体出现的重要的敲门砖。这篇论文介绍了FeUdal 网络,这是一种新的架构,它将子目标(sub-goals)表示为潜在的状态空间(latent state space)的方向,该方向接着转变为有意义的行为基元(behavioural primitives)。FuN 明确地将发现和设置子目标的模块和通过原始动作生成行为的模块分开。这就创造了一个稳定的自然层次结构,并且允许两个模块以互补的方式学习。
我们的实验证明,该方法能让长期信用分配和记忆更易处理。这也为进一步的研究提供了许多途径,例如:可以通过在多个时间尺度上设置目标来构建更深的分层结构,将代理扩展到具有稀疏激励和部分可观察性的真实大环境下。FuN 的模块化结构也适用于迁移学习和多任务学习,即学习的行为基元可以被重新利用已获取新的复杂技能,或者 Manager 的过渡性策略可以转移到具有不同化身的代理商。
论文地址:https://arxiv.org/pdf/1703.01161.pdf
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4476.html
摘要:文本谷歌神经机器翻译去年,谷歌宣布上线的新模型,并详细介绍了所使用的网络架构循环神经网络。目前唇读的准确度已经超过了人类。在该技术的发展过程中,谷歌还给出了新的,它包含了大量的复杂案例。谷歌收集该数据集的目的是教神经网络画画。 1. 文本1.1 谷歌神经机器翻译去年,谷歌宣布上线 Google Translate 的新模型,并详细介绍了所使用的网络架构——循环神经网络(RNN)。关键结果:与...
摘要:相信大家近日对的算法和背后整个人工智能产业的发展很感兴趣,小编因此翻译了采访人工智能领域重要人物施米德休教授的文章。如今很多人在讨论人工智能的潜力,提出一些问题,比如机器是否可以像一个人一样学习,人工智能是否会超越人类的智慧,等等。 3月9日至3月15日,谷歌 AlphaGo 将在韩国首尔与李世石进行5场围棋挑战赛。截止今日,李世石已经连输两局。相信大家近日对 AlphaGo 的算法和...

阅读 1775·2021-10-18 13:34
阅读 3971·2021-09-08 10:42
阅读 1601·2021-09-02 09:56
阅读 1648·2019-08-30 15:54
阅读 3186·2019-08-29 18:44
阅读 3341·2019-08-26 18:37
阅读 2262·2019-08-26 12:13
阅读 510·2019-08-26 10:20



