
摘要:李理卷积神经网络之简介是一种防止模型过拟合的技术,这项技术也很简单,但是很实用。原文链接李理三层卷积网络和的实现卷积神经网络的原理已经在推荐李理卷积神经网络之的原理及实现以及李理卷积神经网络之二文中详细讲过了,这里我们看怎么实现。
《李理:卷积神经网络之Dropout》
4. Dropout
4.1 Dropout简介
dropout是一种防止模型过拟合的技术,这项技术也很简单,但是很实用。它的基本思想是在训练的时候随机的dropout(丢弃)一些神经元的激活,这样可以让模型更鲁棒,因为它不会太依赖某些局部的特征(因为局部特征有可能被丢弃)。
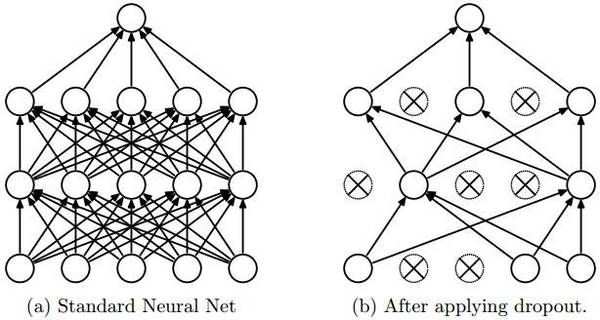
上图a是标准的一个全连接的神经网络,b是对a应用了dropout的结果,它会以一定的概率(dropout probability)随机的丢弃掉一些神经元。
4.2 Dropout的实现
实现Dropout最直观的思路就是按照dropout的定义来计算,比如上面的3层(2个隐藏层)的全连接网络,我们可以这样实现:
""" 最原始的dropout实现,不推荐使用 """p = 0.5 # 保留一个神经元的概率,这个值越大,丢弃的概率就越小。def train_step(X):
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = np.random.rand(*H1.shape) < p # first dropout mask
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = np.random.rand(*H2.shape) < p # second dropout mask
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3 # 反向梯度计算,代码从略def predict(X):
H1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale the activations
H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # NOTE: scale the activations
out = np.dot(W3, H2) + b3
我们看函数 train_step,正常计算第一层的激活H1之后,我们随机的生成dropout mask数组U1。它生成一个0-1之间均匀分布的随机数组,然后把小于p的变成1,大于p的变成0。极端的情况,p = 0,则所有数都不小于p,因此U1全是0;p=1,所有数都小于1,因此U1全是1。因此越大,U1中1越多,也就keep的越多,反之则dropout的越多。
然后我们用U1乘以H1,这样U1中等于0的神经元的激活就是0,其余的仍然是H1。
第二层也是一样的道理。
predict函数我们需要注意一下。因为我们训练的时候会随机的丢弃一些神经元,但是预测的时候就没办法随机丢弃了【我个人觉得也不是不能丢弃,但是这会带来结果会不稳定的问题,也就是给定一个测试数据,有时候输出a有时候输出b,结果不稳定,这是实际系统不能接受的,用户可能认为你的模型有”bug“】。那么一种”补偿“的方案就是每个神经元的输出都乘以一个p,这样在”总体上“使得测试数据和训练数据是大致一样的。比如一个神经元的输出是x,那么在训练的时候它有p的概率keep,(1-0)的概率丢弃,那么它输出的期望是p x+(1-p) 0=px。因此测试的时候把这个神经元乘以p可以得到同样的期望。
原文链接:
http://geek.csdn.net/news/detail/161276
《李理:三层卷积网络和vgg的实现》
卷积神经网络的原理已经在【推荐】李理:卷积神经网络之Batch Normalization的原理及实现以及《李理:卷积神经网络之Dropout》二文中详细讲过了,这里我们看怎么实现。
5.1 cell1-2
打开ConvolutionalNetworks.ipynb,运行cell1和2
5.2 cell3 实现最原始的卷积层的forward部分
打开layers.py,实现conv_forward_naive里的缺失代码:
N, C, H, W = x.shape
F, _, HH, WW = w.shape
stride = conv_param["stride"]
pad = conv_param["pad"]
H_out = 1 + (H + 2 * pad - HH) / stride
W_out = 1 + (W + 2 * pad - WW) / stride out = np.zeros((N,F,H_out,W_out))
# Pad the input
x_pad = np.zeros((N,C,H+2*pad,W+2*pad))
for n in range(N):
for c in range(C):
x_pad[n,c] = np.pad(x[n,c],(pad,pad),"constant", constant_values=(0,0))
for n in range(N):
for i in range(H_out):
for j in range(W_out):
current_x_matrix = x_pad[n, :, i * stride: i * stride + HH, j * stride:j * stride + WW]
for f in range(F):
current_filter = w[f]
out[n,f,i,j] = np.sum(current_x_matrix*current_filter)
out[n,:,i,j] = out[n,:,i,j]+b
我们来逐行来阅读上面的代码
5.2.1 第1行
首先输入x的shape是(N, C, H, W),N是batchSize,C是输入的channel数,H和W是输入的Height和Width
5.2.2 第2行
参数w的shape是(F, C, HH, WW),F是Filter的个数,HH是Filter的Height,WW是Filter的Width
5.2.3 第3-4行
从conv_param里读取stride和pad
5.2.4 第5-6行
计算输出的H_out和W_out
5.2.5 第7行
定义输出的变量out,它的shape是(N, F, H_out, W_out)
5.2.6 第8-11行
对x进行padding,所谓的padding,就是在一个矩阵的四角补充0。
首先我们来熟悉一下numpy.pad这个函数。
In [19]: x=np.array([[1,2],[3,4],[5,6]])
In [20]: x
Out[20]:
array([[1, 2],
[3, 4],
[5, 6]])
首先我们定义一个3*2的矩阵
然后给它左上和右下都padding1个0。
In [21]: y=np.pad(x,(1,1),"constant", constant_values=(0,0))
In [22]: y
Out[22]:
array([[0, 0, 0, 0],
[0, 1, 2, 0],
[0, 3, 4, 0],
[0, 5, 6, 0],
[0, 0, 0, 0]])
我们看到3*2的矩阵的上下左右都补了一个0。
我们也可以只给左上补0:
In [23]: y=np.pad(x,(1,0),"constant", constant_values=(0,0))
In [24]: y
Out[24]:
array([[0, 0, 0],
[0, 1, 2],
[0, 3, 4],
[0, 5, 6]])
了解了pad函数之后,上面的代码就很容易阅读了。对于每一个样本,对于每一个channel,这都是一个二位的数组,我们根据参数pad对它进行padding。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4475.html
摘要:显示了残差连接可以加速深层网络的收敛速度,考察了残差网络中激活函数的位置顺序,显示了恒等映射在残差网络中的重要性,并且利用新的架构可以训练极深层的网络。包含恒等映射的残差有助于训练极深层网络,但同时也是残差网络的一个缺点。 WRN Wide Residual NetworksSergey Zagoruyko, Nikos Komodakis Caffe实现:https://github...
摘要:在本文中,快捷连接是为了实现恒等映射,它的输出与一组堆叠层的输出相加见图。实验表明见图,学习得到的残差函数通常都是很小的响应值,表明将恒等映射作为先决条件是合理的。 ResNet Deep Residual Learning for Image RecognitionKaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun Caffe实现:ht...
摘要:年,发表,至今,深度学习已经发展了十几年了。年的结构图图片来自于论文基于图像识别的深度卷积神经网络这篇文章被称为深度学习的开山之作。还首次提出了使用降层和数据增强来解决过度匹配的问题,对于误差率的降低至关重要。 1998年,Yann LeCun 发表Gradient-Based Learning Applied to Document Recognition,至今,深度学习已经发展了十几年了...

阅读 2396·2023-04-25 14:22
阅读 3795·2021-11-15 18:12
阅读 1336·2019-08-30 15:44
阅读 3261·2019-08-29 15:37
阅读 781·2019-08-29 13:49
阅读 3507·2019-08-26 12:11
阅读 945·2019-08-23 18:28
阅读 1638·2019-08-23 14:55




