
摘要:如果将小磁针看作神经元,磁针状态看作激发与抑制,也可以用来构建深度学习的模型,或者玻尔兹曼机。这么多的基础理论,展现了深度学习中的无处不在的物理本质。
最近朋友圈里有大神分享薛定谔的滚,一下子火了,“当一个妹子叫你滚的时候,你永远不知道她是在叫你滚还是叫你过来抱紧”,这确实是一种十分纠结的状态,而薛定谔是搞不清楚的,他连自己的猫是怎么回事还没有弄清楚。虽然人们对于薛定谔头脑中那只被放射性物质残害的猫的生死一直众说纷纭,斯特恩·盖拉赫却在实验中,实实在在看到了,我们身处的这个物理世界的量子性,也就是既生又死、既真又假、既梦又醒、既粒又波、既此又彼的存在,按照老子的说法是,玄之又玄,众妙之门。
量子性是这个世界已知的基本特征,未来的世界是我们的,也是你们的,但归根结底是量子的:通讯将是量子的,计算将是量子的,人工智能也将是量子的。这个物理世界运行的基本逻辑,决定了我们身边的一切。不要再纠结是庄周做梦变成了蝴蝶、还是蝴蝶做梦变成了庄周,不要再迷惑南科大朱老师的物质意识的鸡与蛋的问题,拿起你的手机使劲往地上一摔,你就知道这个世界是客观的还是主观的了。
当然量子性不一定是终极真理,还有许多神秘的现象需要解释,比如有鬼魅般超距作用的量子纠缠。但要相信,从牛顿到麦克斯韦,从爱因斯坦到波尔,人类不断了解和认知这个世界的本质,比如能量守恒,比如不可逆的熵增,比如质能方程,比如量子性。这些物理的本质渗透到周遭的方方面面,而火热的深度学习,学的就是现实生活的事物,通过观测推演获取这些事物的内在逻辑,因而是处处遵从这些物理原理的。
大部分的现代神经网络算法都是利用较大似然法(Maximum Likelyhood)训练的,IanGoodfellow 与Yoshua Bengio更是在他们著的《深度学习》一书中详述了利用香农的信息熵构建深度学习损失函数的通用形式:
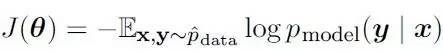
这些神经网络“似”的什么“然”呢?损失函数中的条件概率、信息熵向我们传达一个怎样的思想呢?在《迷人的数据与香农的视角》(http://mp.weixin.qq.com/s/qgWU6qbEsgXP6GKTVvE6Hg)一文中,我曾经讨论过香农熵与热力学熵的关系:“每一个热力学系统对外表现出宏观的特征,温度、压力、体积等”,“而其内部却是由无数不确定位置、速度、形态的分子原子组成”,“那些无约束,充分发展了的随机变量,达到了势能较低的稳定状态”,对外展现的信息由此势能较低状态的概率分布决定。换种形式,可以将该状态的概率分布的对数,定义为此系统携带的信息量,也就是香农熵。所以这里“似”的“然”就是一种较低势能状态,或者说对外展现出较大信息熵的状态。
而这个较大似然,不是没有条件的,注意到“充分发展”这个说法了吗?“充分发展”的系统是一种相对稳定的系统。我在《站在香农与玻尔兹曼肩上,看深度学习的术与道》(http://mp.weixin.qq.com/s/T6YWQY2yUto4eZa3lEgY3Q)文中强调过,“通过训练寻找这些概率分布函数,其中隐含着一个基本假设,就是系统是处于相对稳定状态的,一个急速演进中的开放系统,概率的方法应该是不适合的”,“又比如玻尔兹曼机,基于哈密尔顿自由能的分布其实都是有隐含的系统相对稳定假设的(玻尔兹曼分布是“平衡态”气体分子的能量分布律)。对于非稳定系统,就得求助于普利高津了”。所以使用诸如RBM(Restricted Boltzmann Machines)之类的深度学习算法的时候,我们首先需要研究一下问题域是不是相对稳定的。
上文中提到的“玻尔兹曼分布”,是描述理想气体在受保守外力作用、或保守外力场的作用不可忽略时,处于热平衡态下的气体分子按能量的分布规律:
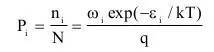
这里的 q 叫做配分函数(Partition Function),就是系统中粒子在不同能量级上的分布,它是连接微观粒子状态与宏观状态的桥梁,是整个统计力学的核心。不仅对于气体粒子,玻尔兹曼分布同样被证实适用其他微观到宏观的状态演化,比如著名的Ising Model。Ising Model最初是用来解释铁磁物质的相变(磁铁加热到一定温度以上出现磁性消失)的,模型标定每个小磁针两个状态(+1 -1),所有N个粒子的状态组合是一个"配置",则系统共有2的N次方个"配置",该系统的数量众多“配置”的不同能量级分布服从“玻尔兹曼分布”:
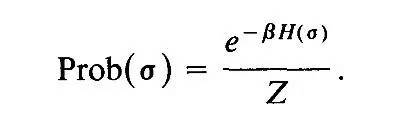
因模型简单与高度抽象,IsingModel被广泛应用于自然科学与社会科学等众多领域。如果将小磁针看作神经元,磁针状态看作激发与抑制,Ising Model 也可以用来构建深度学习的Hopfield模型,或者玻尔兹曼机 。Hopfield Associative Memory (HAM)是经典的神经网络,它仅包含显式神经单元,给这些单元赋予能量,经过推导,我们可以得到这个神经网络的配分函数和自由能表达式,看起来是不是似曾相识?

不过HAM模型有不少显而易见的缺点(无法一层层提取潜变量的信息),Hinton因而创造了有隐含神经元的RBM。
在《迷人的数据与香农的视角》与《站在香农与玻尔兹曼肩上,看深度学习的术与道》两文中,我反复介绍了自己的“顿悟”:“事物由不同层次的随机变量展现出来的信息来表达,不同层次上的随机变量携带不同的信息,共同组合影响上一层的随机变量的信息表达,而随机变量对外表达的信息则取决于该随机变量的条件概率分布”。如果要给这个“顿悟”找个科学的解释,最合适就是尺度重整化(ScaleRenormalization)了。Charles H Martin博士2015年在其文章 《Why Deep Learning Works II: theRenormalization Group》提到,在神经网络中引入隐含节点就是尺度重整化。
每次尺度变换后,我们计算系统有效的哈密尔顿能量,作用在新的特征空间(潜变量空间),合理的尺度重整化保持了系统哈密尔顿自由能的不变性。注意这里的能量守恒,它确保了尺度重整化的合理性。每一次尺度变换后,自由能保持不变。F =-lnZ, 这里Z是配分函数(上文的q),是一个能量(不同能级上粒子数)的概率分布,Z不变,即能量的概率分布不变,就是要求潜变量的特征空间中的大尺度“粒子”能满足原来能量的概率分布。重整化群给出了损失函数,也就是不同层的F自由能的差异, 训练就是来最小化这个差异。
这么多的基础理论,展现了深度学习中的无处不在的物理本质。我还可以举几个大家熟悉的例子,激发思考:CNN 中卷积的意义是什么,平滑输入特征对最终的模型为什么是有效的,为什么池化(pooling)很实用?动量(Momentum)优化方法为什么比普通的SGD快,而且适用高曲率的场合? 为什么Dropout是高效、低能耗的 规则化(Regularization)方法?为何Lecun新提出的EBGAN有更好的收敛模式和生成高分辨率图像的可扩展性?不一而足,深度学习实验室应该多欢迎一些物理背景的学者参与进来啊!
人法地,地法天,天法道,道法自然。在女生节、女神节里,对身边可爱、聪慧、善良、温婉、贤惠与伟大的女性同胞多一声祝福,衷心希望男同胞不要收到“薛定谔的滚”!用智慧的头脑,不断重整化我们的认知、态度,让和谐与美好成为较大似然。
作者简介
王庆法,阳光保险集团大数据中心副总经理兼首席架构师、平台部总经理,首席数据官联盟专家组成员,16年在数据库、分布式系统、机器学习以及云计算等领域,从事软件开发、架构设计、产品创新与管理。热衷于基于市场的数据产品的创新与落地。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4474.html
摘要:薛定谔的猫以上内容是前提,友情提示,如你有理解模糊之处,请先阅读对应的文章。这个例子告诉大家薛定谔的猫混入了的字典中,而且答案是,打开笼子,这只猫就会死亡。 showImg(https://segmentfault.com/img/remote/1460000019217212?w=1880&h=1253); 本文原创并首发于公众号【Python猫】,未经授权,请勿转载。原文地址:ht...
摘要:本人旨在让你了解当前人工智能应用最普遍的智能推荐引擎,其背后的设计理念,以及一些更深度的思考。传统的智能推荐引擎对用户进行多维度的数据采集数据过滤数据分析,然后建模,而人工智能时代的推荐引擎在建立模型步骤中加入训练测试验证。 We shape our tools and afterwards our tools shape us. ...
摘要:发布年月日,代号名称为的发布正式版本。目前,最新的系列版本为年月日发布的版本,主要是对的安全更新。发布于年月初发布,代号薛定谔的猫,搭载和。 文章来源:程序员的资料库 Linux 和开源软件在过去的一年里面都取得了不小的进步。在这个特殊日子里面,我们对 2013 年这一年业界发生的重要事情分成了三个方面:Linux 发行版、重要周年庆祝活动、曾引起业界较大关注的事件这三个方面进行了梳理...

阅读 1292·2021-11-22 13:54
阅读 1483·2021-11-22 09:34
阅读 2776·2021-11-22 09:34
阅读 4147·2021-10-13 09:39
阅读 3397·2019-08-26 11:52
阅读 3410·2019-08-26 11:50
阅读 1583·2019-08-26 10:56
阅读 1975·2019-08-26 10:44




