
摘要:最近,等人对于英伟达的四种在四种不同深度学习框架下的性能进行了评测。本次评测共使用了种用于图像识别的深度学习模型。深度学习框架和不同网络之间的对比我们使用七种不同框架对四种不同进行,包括推理正向和训练正向和反向。一直是深度学习方面最畅销的。
最近,Pedro Gusmão 等人对于英伟达的四种 GPU 在四种不同深度学习框架下的性能进行了评测。本次评测共使用了 7 种用于图像识别的深度学习模型。
第一个评测对比不同 GPU 在不同神经网络和深度学习框架下的表现。这是一个标准测试,可以在给定 GPU 和架构的情况下帮助我们选择合适的框架。
第二个测试则对比每个 GPU 在不同深度学习框架训练时的 mini-batch 效率。根据以往经验,更大的 mini-batch 意味着更高的模型训练效率,尽管有时会出现例外。在本文的最后我们会对整个评测进行简要总结,对涉及到的 GPU 和深度学习架构的表现进行评价。
GPU、深度学习框架和不同网络之间的对比
我们使用七种不同框架对四种不同 GPU 进行,包括推理(正向)和训练(正向和反向)。这对于构建深度学习机器和选择合适的框架非常有意义。我们发现目前在网络中缺乏对于此类研究的对比。
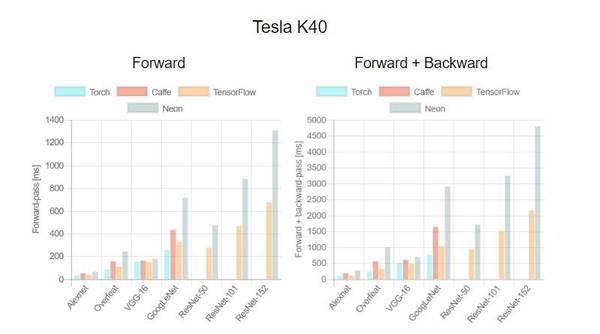
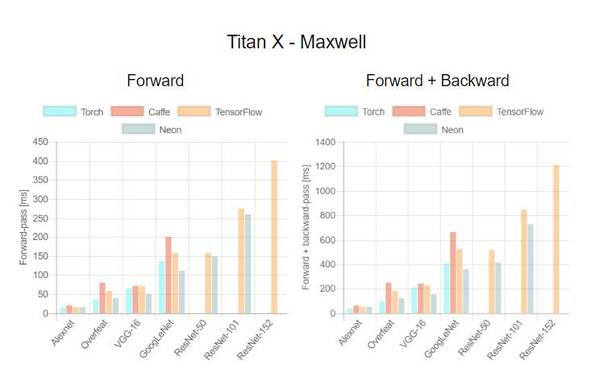
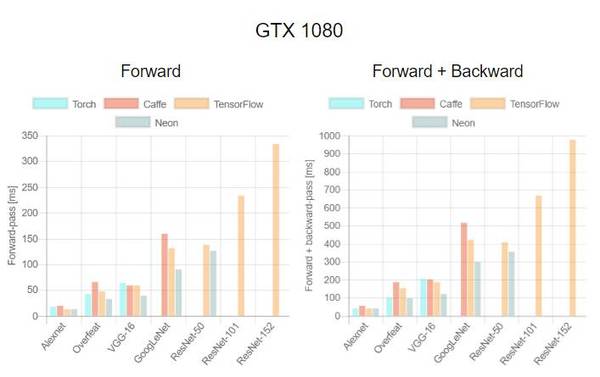
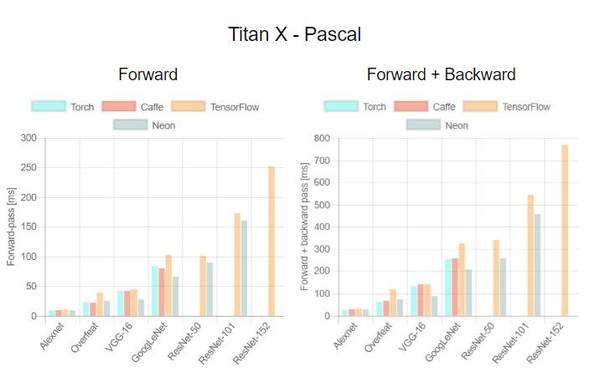
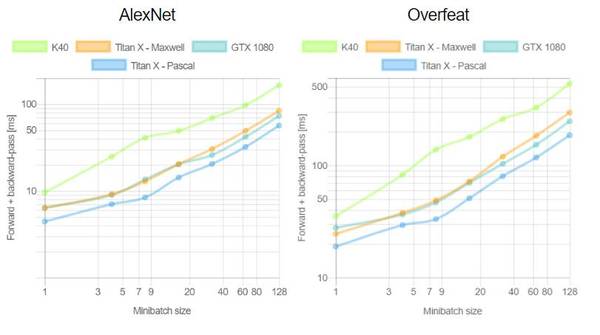
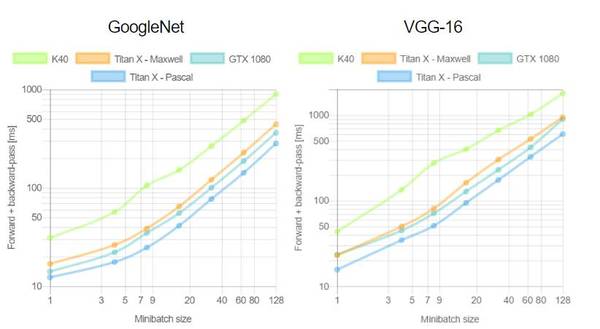
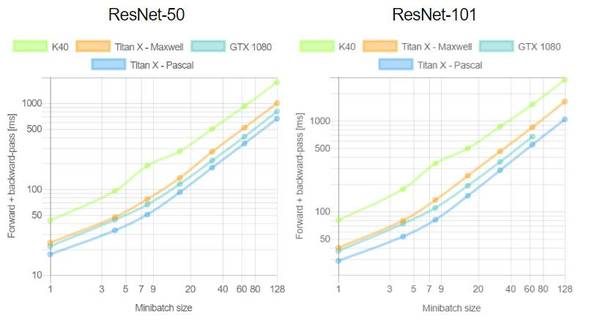
这是首次针对不同 GPU(Tesla K40,Titan-X Maxwell,GTX 1080 和 Titan-X Pascal)与不同网络(AlexNet,Overfeat,Oxford VGG,GoogLeNet,ResNet-50,ResNet-101 和 ResNet-52)在不同深度学习框架下(Torch,Caffe,TensorFlow 和 Neon)的评测。在评测中,除了 Neon,所有框架都使用了英伟达 cuDNN 5.1。我们在每个 minibatch 里使用了 64 个取样,每次进行超过 100 次推理和训练。图表中缺失的数据意味着该次测试遭遇内存不足。
用于 TensorFlow 的 Minibatch 效率
训练深度学习框架时知道每个 minibatch 中的样本数量将会加快训练。在第二个测评中,我们分析了 minibatch 尺寸与训练效率的对比。由于 TensorFlow 1.0.0 极少出现内存不足的情况,我们只使用它进行这项评测。这次实验中我们重新评估了 100 次运行中的平均正向通过时间和和正向+反向通过时间。

测评分析
关于第一个测评,我们注意到,Neon 几乎总是能为 Titans 和 GTX 1080 导出较好的结果,而对 K40 的优化最差。这是因为 Neon 针对 Maxwell 和 Pascal 架构做了优化。Tesla K40,作为一个 Kepler GPU,缺少这样低层级的优化。Torch 在所有架构中都可以输出好结果,除了被用在现代 GPU 和更深的模型时。这又一次成了 Neon 发挥作用的时候。最后,我们指出 TensorFlow 是一个可以训练所有网络的框架,并且不会出现内存不足的情况,这是我们继续使用它作为第二个测评的框架的原因。
关于第二个测评,一般来说更大的 minibatch 可以减少每个样本的运行时间继而减少每个 epoch 的训练时间。正如我们在上图看到的,当使用 VGG 网络时,GTX 1080 需要 420.28 毫秒为一个 64 样本的 minibatch 运行正反向通过;相同的配置训练 128 个样本需要 899.86 毫秒,是前者的两倍还要再多出 60 毫秒。此外,我们注意到对于所有大小为 8 的 minibatch 中的网络,Tesla K40 有一个下凹曲率; Titan X Pascal 在使用相同 batch 大小的更浅架构上(例如 AlexNet 和 Overfeat)表现出上凹曲率。下凹曲率表明有效率在下降而上凹曲率则相反。更有趣的是 minibatch 大小的特殊取值也意味着更明显的效率。分析两个 GPU 将有助于解释这为什么会发生。
附录
以下是对测评中使用的 GPU 还有架构和框架版本的扼要介绍。
GPU
1.Tesla K40:
K40 具有 2880 个 cuda 内核,745MHz 的基本频率和可达 288GB/s 的内存宽带的 12G GDDR5 RAM。这是一个基于 Kepler 架构的服务器 GPU,具备 3.5Tflops 的计算能力。K40 已经停产,但仍被广泛用于很多数据中心,了解其性能对于我们将来是否要购买新硬件很有帮助。
2.Titan X Maxwell:
Titan X 是具有 5.1Tflops 计算能力、用于 Maxwell 架构的旗舰消费级 GPU。它具有 3072 cuda 内核,1000MHz 的基本频率,传送速率为 336.5GB/s 的 12G GDDR5。考虑到其硬件规格和大多数深度学习应用仅依靠于单精度浮点运算,Titan X Maxwell 目前能用 750 美元左右买到,被认为是基于起始价格为 1000 美元的 GPU 的服务器的较佳替换方案。
3.GTX 1080:
GTX 1080 是英伟达目前生产的高端游戏 GPU,售价 599 美元。它具备 2560 个 cuda 内核,1607MHz 的基本频率,提供 320GB/s 宽带的 8GB GDDR5X。先进的 Pascal 架构为其带来了 6.1Tflops 的计算能力。
4.Titan X Pascal:
Titan X Pascal 一直是深度学习方面最畅销的 GPU。它具备 3584 cuda 内核,1417MHz 的基本频率,提供 480GB/s 内存宽带的 12GB GDDR5X。它比 GTX 1080 有更强大的计算能力(约 11Tflops),目前标价 1200 美元。尽管消费者趋之若鹜,英伟达目前在官方网站上直销 Titan X Pascal,每个消费者限购 2 块。
此外,在 3 月 10 日售价 699 美元,计算能力 11.34Tflops 的 GeForce GTX 1080Ti 推出以后,消费者拥有了 Titan X 以外的另一个选择。
神经网络
1.AlexNet:
2012 年,Alex Krizhevsky 使用五层卷积、三层完全连接层的 CNN 网络赢得了 ImageNet 竞赛(ILSVRC)。AlexNet 证明了 CNN 在分类问题上的有效性(15.3% 错误率),而此前的图片识别错误率高达 25%。这一网络的出现对于计算机视觉在深度学习上的应用具有里程碑意义。
2.Overfeat:
2013 年,Overfeat 通过降低第一层的步幅改进了 AlexNet 的架构,让图片识别错误率降低至 14.2%。这一方法证明了卷积神经网络使用同步分类、本地化和图片中对象检测的方式可以增加图片识别任务的准确度。
3.VGG Network:
2014 年,牛津大学的研究人员通过训练 11 到 19 层的卷积神经网络证明了深度对于图像识别任务的重要性。他们的工作表明,使用 3×3 空间内核的两个连续卷积层比使用单个 5×5 卷积层具有更高的准确性,同时这一优势也能为非线性层带来帮助。此外,作者证明 19 层 CNN 输出的结果与 16 层网络具有相似的精度,这暴露了当时技术训练深度 CNN 的困难。最后,VGG Net 进一步将 ILSVRC-2014 分类任务中的错误率减少到了 7.3%。
4.GoogLeNet:
该方式由谷歌研究人员于 2014 年推出,它是由 22 层卷积神经网络构成的模型,它被称为 Inception,是由并行和串行的网络进行的级联。网络分类器的误差为 6.67%。
5.残差网络:
在 2015 年,微软研究院的学者提出了一种新的 CNN 架构——残差网络(ResNet)。在残差网络中,残差块的任务是学习连续输出的表示差异。这一方法通过 110 层模型在 ImageNet 竞赛时达到了 3.57% 的误差率。
本次评测中使用的深度学习架构版本:
Caffe: commit 746a77e6d55cf16d9b2d4ccd71e49774604e86f6
Torch7: commit d03a42834bb1b674495b0c42de1716b66cc388f1
Nervana Neon: 1.8.1
TensorFlow: 1.0.0
原文地址:http://add-for.com/blog/nvidia-dgx-1-supercomputer-join-our-community-based-deep-learning-benchmark/
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4472.html
摘要:在两个平台三个平台下,比较这五个深度学习库在三类流行深度神经网络上的性能表现。深度学习的成功,归因于许多层人工神经元对输入数据的高表征能力。在年月,官方报道了一个基准性能测试结果,针对一个层全连接神经网络,与和对比,速度要快上倍。 在2016年推出深度学习工具评测的褚晓文团队,赶在猴年最后一天,在arXiv.org上发布了的评测版本。这份评测的初版,通过国内AI自媒体的传播,在国内业界影响很...
摘要:但年月,宣布将在年终止的开发和维护。性能并非最优,为何如此受欢迎粉丝团在过去的几年里,出现了不同的开源深度学习框架,就属于其中典型,由谷歌开发和支持,自然引发了很大的关注。 Keras作者François Chollet刚刚在Twitter贴出一张图片,是近三个月来arXiv上提到的深度学习开源框架排行:TensorFlow排名第一,这个或许并不出意外,Keras排名第二,随后是Caffe、...

阅读 1958·2021-11-09 09:46
阅读 2542·2019-08-30 15:52
阅读 2511·2019-08-30 15:47
阅读 1379·2019-08-29 17:11
阅读 1786·2019-08-29 15:24
阅读 3553·2019-08-29 14:02
阅读 2499·2019-08-29 13:27
阅读 1258·2019-08-29 12:32



