
摘要:谷歌表示,在一些情况下,系统的翻译准确度能够接近人类翻译水平。年月,谷歌推出了新型的翻译系统。因此,相比以往任何翻译系统,谷歌的新型翻译系统更加接近人类大脑的翻译方式。
作为全球 AI 语言翻译服务的领先者之一,2016年9月,谷歌推出了新型的翻译系统,Google Neural Machine Translation(GNMT),能让翻译系统不再像以往那样逐字逐字地翻译,而是从整体上分析句子,大幅提升了机器翻译的质量。谷歌表示,在一些情况下,GNMT 系统的翻译准确度能够接近人类翻译水平。本篇文章分析了 google 新型翻译系统的技术实现。

2016年9月,谷歌推出了新型的翻译系统。自此,翻译系统获得了诸多有意思的发展。本篇文章将用尽可能简洁的语句为大家介绍该新型翻译系统。
早期版本的翻译系统是基于短语的机器翻译,即 PBMT(Phrase-based Machine Translation)。PBMT 会将输入的句子分成一组单词或者短语,并将其多带带翻译。这显然不是较佳的翻译策略,完全忽略了整个语句的上下文之间的联系。而新型翻译系统使用的是谷歌神经机器翻译,即 GNMT(Google Neural Machine Translation)。该模型改进了传统的 NMT。接下来,让我们看看 GNMT 是如何工作的。
编码器
在理解编码器之前,我们必须先了解一下 LSTM(Long-Short-Term-Memory) 单元。简单来说,LSTM 单元就是一个具有记忆概念的神经网络。LSTM 通常用于“学习”时间序列或者时间数据中的某些模式。在任意指定的点,LSTM 都能接受新的向量输入,并且使用“新的输入+上下文之间的联系”这样的组合生成预期的输出结果:
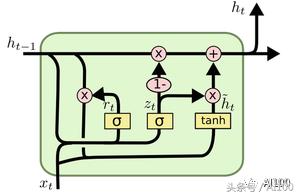
上图中,xt 表示在时间点 t 时的输入数据,ht-1 表示从时间点 t-1 传过来的上下文信息。如果 xt 的维度是 d,那么 ht-1 的维度就是 2d,ht-1 是以下两个向量的级联:
在最后一个时间步长 t-1(短期记忆),相同 LSTM 的预期输出;
另外一个编码长期记忆的 d 维度向量——也称为单元状态。
第二部分通常不用于架构中的下一个组件。相反,它在下一个步骤中会被相同的 LSTM 所使用。通常,在伴有预期输出的同时,我们会使用大量带标签的序列数据来训练 LSTM 模型。这会让我们知道应该重新训练或者保留输入哪些部分,以及如何用数学表达处理 xt 和 ht-1 ,进而得出 ht。如果你想更好地了解 LSTM,那么我推荐 Christopher Olah 写的这篇博客:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/。
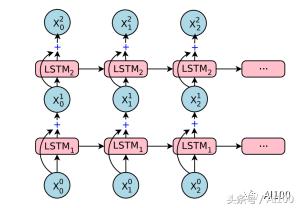
LSTM 也可以按下图方式展开:
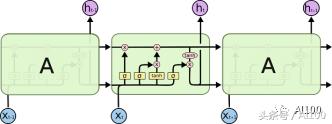
不要担心,上图中均为同一个 LSTM 单元的副本(因此采用相同的训练方式),每个单元的输出会反馈到下一个输入。这允许我们可以一次性地输入整个向量集合(实际上,是一整个时间序列),而不用分次多带带向 LSTM 的副本中输入。
GNMT 的编码器网络本质上是一个堆栈 LSTM。
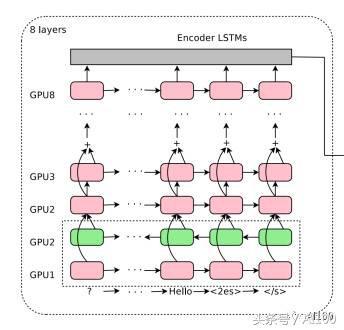
所有水平方向的粉红色/绿色框都是“展开的” LSTM。因此,上图中的模型具有8个堆叠的 LSTM。整个架构的输入是一个句子中的有序集标记,每个都以向量的形式表示。请注意,我说的是标记,而不是一个词。在预处理过程中,GNMT 负责将所有的词分解成标记或者片段,然后将这些标记或者片段输入到神经网络中。这会使框架(至少部分地)能够理解某些没见过的复杂词汇。
以“Pteromerhanophobia”词为例,即使你可能并不知道它是什么意思,但是却可以知道这个词具有恐惧的意思,因为它是基于“phobia”标记的。谷歌将这种方法称为 Wordpiece 建模,在其训练阶段,需要从巨大的词库中分解词汇,依据的是统计学习。
在使用堆栈 LSTM 的时候,每一层都会根据上一层反馈给它的时间序列得出一个模式。越往上层,越能看到更多的抽象模式,上层的模式是从下层学到的。例如,最底层看到的可能是一组点,接下来的一层将会是一条线,其下一层看到的将是由线条组成的诸个多边形,再接下来,你会看到从多边形中学习得到的一个对象……当然,这是有限制的,取决于使用堆栈 LSTM 的数量和使用方法。并不是 LSTM 越多越好,因为最终你会发现训练这个模型太慢了,而且非常困难。
除了堆栈 LSTM,上面的这种架构还有一些有趣的方面。
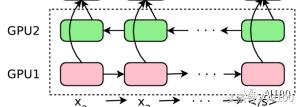
你会看到底部的第二层是绿色的。这是因为箭头——即句子中的标记顺序,在这一层是相反的。这意味着,第二个 LSTM 会以相反的顺序看到整个句子。这样做的原因很简单:当你把某个句子看作整体时,其中任意一个单词的“语境”都将包含其前面和其后面的单词。两个最底层的 LSTM 都将原始的句子作为输入,但是两者的方向是不同的。第三个 LSTM 层从前面两个层获得双向输入——基本上,覆盖了给定句子的正向和逆向语境。之后的每一层,都是如此,从上一层句子中的上下文关系,学习更高级的模式。
你可能已经注意到了,从第五层开始出现了“+”号。这是一种残差学习的形式。残差学习从第五层开始发生:对于第 N+1 层,其输入数据是第 N 层和第 N-1 层输出的叠加产物。在深度学习的许多应用问题中,残差学习已经被证明可以提高准确性并减少梯度消失(http://neuralnetworksanddeeplearning.com/chap5.html)等问题。直观地说,你可以认为残差学习是一种跨层保存信息的方法。如果你想更好地理解残差学习,那么你可以阅读以下链接中 Quora 问题的答案(https://www.quora.com/What-is-an-intuitive-explanation-of-Deep-Residual-Networks)。
最后,你可以在编码器输入的末尾看到额外的<2es>和字符。表示“输入结束”。另一方面,<2es>字符表示的是目标语言——在本次实例中,表示的是西班牙语。把目标语言作为框架的输入,是 GNMT 一个独特之处。这样做的好处是可以提高翻译的质量。
注意模块和解码器
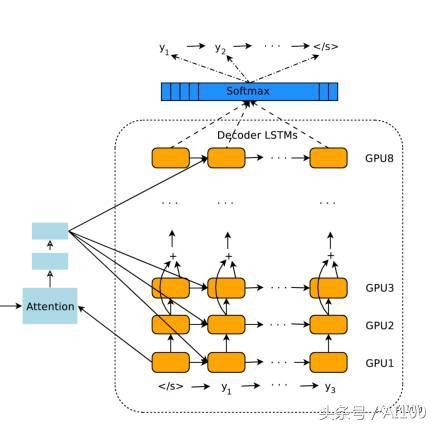
编码器产生一组有序输出向量(每个输入标记对应一个输出向量)。然后将这些有序向量输入到注意模块和解码器的框架中。在很大程度上,解码器的设计和编码器的设计非常相似,都是堆栈 LSTM 和残差链接。接下来,让我们讨论一下解码器和编码器的不同之处。
我已经提到,GNMT 是将整个句子作为输入。然而,直觉上却认为,对于解码器即将产生的所有标记,不应该对输入语句中所有向量(标记)都赋予相等的权重。例如,当你写出故事的一部分时,你的焦点应该缓慢漂移到其余的部分。在 GNMT 中,这项工作由注意模块完成。注意模块获得的输入是编码器的完整输出和解码器的向量。这使得它可以“理解”已经翻译了哪些部分,然后指示解码器将注意力转移到编码器输出向量的其他部分。
堆栈 LSTM 解码器会根据编码器的输入信息和注意模块的相关命令不断输出向量。这些向量会被输入到 softmax 层中。在这里,你可以将 softmax 层看作是一个概率分布生成器。基于来自最顶层 LSTM 的输入向量,softmax 层为每个可能的输出标记分配概率(请注意,因为目标语言已经提供给了编码器,因此信息已经被传播了)。最后输出获得较大概率的标记。
一旦解码器 softmax 层决定当前标记是 (或句末),那么整个过程将会停止。请注意,解码器解码的步骤数不必完全等同于编码器编码的步骤数,因为在每个计算步骤上都倾注了很多精力。
总的来说,这就是你能看到的完整的翻译过程:
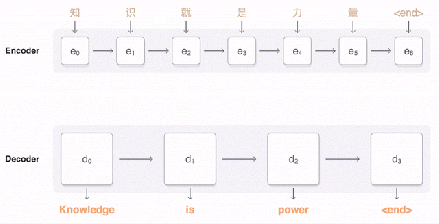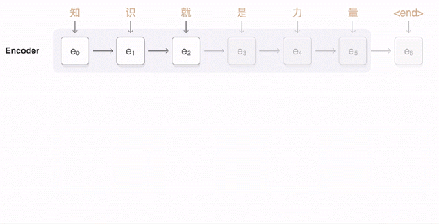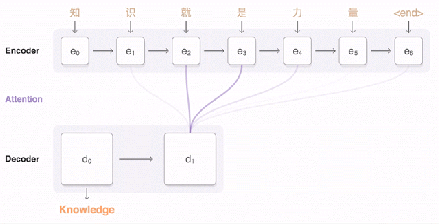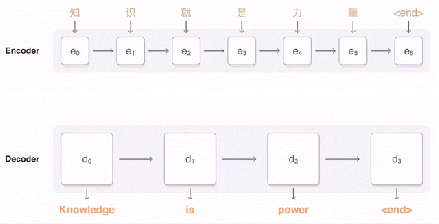
训练和 Zero-Shot 翻译
通过大量的(输入、目标语言)句子集合来训练完整的框架(编码器+注意+解码器)。在某种意义上,在将标记从输入句子转换成适当的向量格式时,体系结构“知道”输入的是什么语言。并且,目标语言也是输入参数的一部分。深度 LSTM 的高度在于,神经网络会通过一种称为反向传播/梯度下降(Backpropagation/GradientDescent,https://codesachin.wordpress.com/2015/12/06/backpropagation-for-dummies/)的算法,来训练这些数据:
GNMT 团队还发现了另外一个惊人的现象:如果只是向框架中输入目标语言,就能实现 Zero-Shot 翻译!这意味着:在训练期间,如果我们提供英语→日语和英语→韩语翻译,那么 GNMT 可以自动地实现日语→韩语的翻译,并且完成得非常好!事实上,这也是 GNMT 项目的较大成就。从直觉上来说,编码器产生的是一种通用语言形式。不管我用何种语言来表达“狗”这个单词,最终你都会联想到一只友好的狗狗——从本质上来说,是概念意义上的“狗”。这个“概念”是由编码器产生的,不会考虑语言的限制。事实上,有些文章甚至认为,谷歌的 AI 发明出了一个独特的语言系统。
将目标语言作为输入,这可以让 GNMT 较为容易地使用相同的神经网络利用任意语言对进行训练,同时也使得 Zero-Shot 翻译成为可能。因此,相比以往任何翻译系统,谷歌的新型翻译系统更加接近人类大脑的翻译方式。
如果想对该领域有进一步的了解,可以阅读以下文章:
First blog post about GNMT onthe Google Research Blog. (Corresponding Research Paper)
https://research.googleblog.com/2016/09/a-neural-network-for-machine.html
https://arxiv.org/pdf/1609.08144v2.pdf
Second blog post aboutZero-Shot Translations. This one made the biggest splash. (CorrespondingResearch Paper)
https://research.googleblog.com/2016/11/zero-shot-translation-with-googles.html
https://arxiv.org/pdf/1611.04558v1.pdf
A great NYTimes article thattells the story behind this Google Translate.
https://www.nytimes.com/2016/12/14/magazine/the-great-ai-awakening.html?_r=0
本文作者 Sachin Joglekar 是 Google 的一位软件工程师,目前是一名机器学习爱好者。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4469.html
摘要:三人造神经元工作原理及电路实现人工神经网络人工神经网络,缩写,简称神经网络,缩写,是一种模仿生物神经网络的结构和功能的数学模型或计算模型。神经网络是一种运算模型,由大量的节点或称神经元,或单元和之间相互联接构成。 一、与传统计算机的区别1946年美籍匈牙利科学家冯·诺依曼提出存储程序原理,把程序本身当作数据来对待。此后的半个多世纪以来,计算机的发展取得了巨大的进步,但冯·诺依曼架构中信息存储...
摘要:今年月,谷歌发布了。在谷歌内部被称为的方法中,一个控制器神经网络可以提出一个子模型架构,然后可以在特定任务中对其进行训练和评估质量。对于整个领域来说,一定是下一个时代发展重点,并且极有可能是机器学习的大杀器。 为什么我们需要 AutoML?在谈论这个问题之前,我们需要先弄清楚机器学习的一般步骤。其实,不论是图像识别、语音识别还是其他的机器学习项目,其结构差别是很小的,一个效果好的模型需要大量...
摘要:引擎可以是一个标准的解释器,也可以是一个将编译成某种形式的字节码的即时编译器。和其他引擎最主要的差别在于,不会生成任何字节码或是中间代码。不使用中间字节码的表示方式,就没有必要用解释器了。 原文地址:https://blog.sessionstack.com... showImg(https://segmentfault.com/img/bVVwZ8?w=395&h=395); 数周之...
摘要:经钱盾反诈实验室研究发现,该批恶意应用属于新型。可信应用商店绕过杀毒引擎,这样病毒自然能轻松入侵用户手机。安全建议建议用户安装钱盾等手机安全软件,定期进行病毒扫描。 背景近期,一批伪装成flashlight、vides和game的应用,发布在google play官方应用商店。经钱盾反诈实验室研究发现,该批恶意应用属于新型BankBot。Bankbot家族算得上是银行劫持类病毒鼻祖,在...
摘要:言简意赅地说,我们的这款即时视觉翻译,用到了深度神经网络,技术。您是知道的,深度学习的计算量是不容小觑的。因为如果字符扭曲幅度过大,为了识别它,神经网络就会在过多不重要的事物上,使用过高的信息密度,这就大大增加深度神经网络的计算量。 前几天谷歌更新了它们的翻译App,该版本有诸多提升的地方,其中较大的是提升了所谓字镜头实时视频翻译性能和通话实时翻译性能。怎么提升的呢?字镜头技术首创者、Goo...

阅读 1501·2021-09-22 15:43
阅读 2208·2019-08-30 15:54
阅读 1205·2019-08-30 10:51
阅读 2136·2019-08-29 18:35
阅读 469·2019-08-26 11:58
阅读 2523·2019-08-26 11:38
阅读 2487·2019-08-23 18:35
阅读 3709·2019-08-23 18:33





