
摘要:可以想象,监督式学习和增强式学习的不同可能会防止对抗性攻击在黑盒测试环境下发生作用,因为攻击无法进入目标策略网络。我们的实验证明,即使在黑盒测试中,使用特定对抗样本仍然可以较轻易地愚弄神经网络策略。

机器学习分类器在故意引发误分类的输入面前具有脆弱性。在计算机视觉应用的环境中,对这种对抗样本已经有了充分研究。论文中,我们证明了对于强化学习中的神经网络策略,对抗性攻击依然有效。我们特别论证了,现有的制作样本的技术可以显著降低训练策略在测试时的性能。我们的威胁模型认为对抗攻击会为神经网络策略的原始输入引入小的干扰。针对对抗样本攻击,我们通过白盒测试和黑盒测试, 描述了任务和训练算法中体现的脆弱程度。 无论是学习任务还是训练算法,我们都观测到了性能的显著下降,即使对抗干扰微小到无法被人类察觉的程度。
深度学习和深度强化学习最近的进展使得涵盖了从原始输入到动作输出的end-to-end学习策略变为可能。深度强化学习算法的训练策略已经在Atari 游戏和围棋中取得了骄人的成绩,展现出复杂的机器操纵技巧,学习执行了运动任务,并在显示世界中进行了无人驾驶。
这些策略由神经网络赋予了参数,并在监督式学习中表现出对于对抗性攻击的脆弱性。例如,对训练用于分类图像的卷积神经网络,添加进入输入图像的干扰可能会引起网络对图像的误分,而人类却看不出加入干扰前后的图像有何不同。论文中,我们会研究经过深度强化学习训练的神经网络策略,是否会受到这样的对抗样本的影响。
不同于在学习过程中处理修正后的训练数据集的监督式学习,在增强式学习中,这些训练数据是在整个训练过程中逐渐被收集起来的。换句话说,用于训练策略的算法,甚至是策略网络加权的随机初始态,都会影响到训练中的状态和动作。不难想象,根据初始化和训练方式的不同,被训练做相同任务的策略,可能大相径庭(比如从原始数据中提取高级特征)。因此,某些特定的学习算法可能导致出现较为不受对抗样本影响的策略。可以想象,监督式学习和增强式学习的不同可能会防止对抗性攻击在黑盒测试环境下发生作用,因为攻击无法进入目标策略网络。
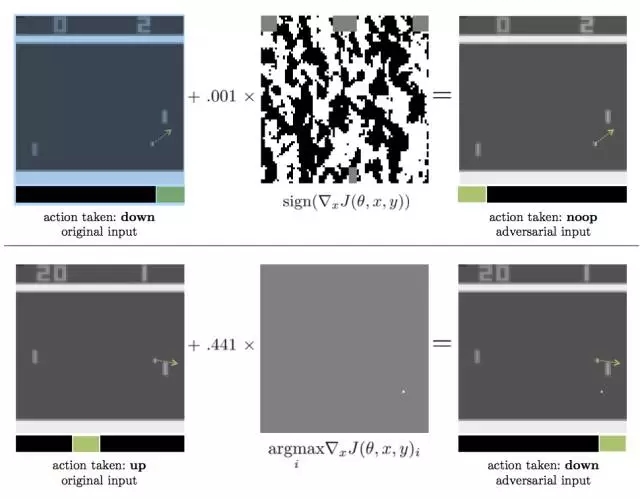
图表1:产生对抗样本的两种方法,适用于借助DQN算法玩PONG游戏来进行策略训练。点形箭头从小球开始,表明了其运动方向,绿色的箭头则强调了对于特定输入来说较大化Q值的action。两种情况下,对于原始输入,策略都采取了好的action,但对抗性干扰都造成了小球和点的遗失。
上图:对抗性样本使用FGSM构造,对抗干扰带有l∞-norm constraint;转化为8-bit的图像编码率后,对抗性输入和原始输入相等,但仍然影响了性能。
下图:对抗性样本使用FGSM构造,对抗干扰带有l∞-norm constraint;最优干扰是在真实的小球下方创造一个“假的”小球。
我们的主要贡献是描写了两个因素对于对抗样本的作用效果:用于学习策略的深度强化学习算法,以及对抗性攻击自己是否能进入策略网络(白盒测试vs.黑盒测试)。我们首先分析了对4种Atari games的3类白盒攻击,其中游戏是经过3种深度强化学习算法训练过的(DQN、TRPO和A3C)。我们论证了,整体上来说,这些经训练的策略对于对抗样本是脆弱的。然而,经过TRPO和A3C训练的策略似乎对于对抗样本的抵抗性更好。图表1显示了在测试时的特定一刻,两个对经过DQN训练的Pong策略的对抗性攻击样本。
接着,我们考察了对于相同策略的黑盒攻击,前提是我们假设对抗性攻击进入到了训练环境(例如模拟器),但不是目标策略的随机初始态,而且不知道学习策略是什么。在计算机视觉方面,Szegedy等人观测到了可传递特性:一个设计用于被一种模型误分的对抗样本经常会被其他经过训练来解决相同问题的模型误分。我们观测到在强化学习应用中,整个数据集里也存在这样的可传递特性,即一个设计用于干扰某种策略运行的对抗样本也会干扰另一种策略的运行,只要这些策略是训练用于解决同样的问题。特别的,我们观测到对抗样本会在使用不同trajectory rollouts算法进行训练的模型之间传递,会在使用不同训练算法进行训练的模型之间传递。
下面介绍一下关于实验的基本情况。
我们在 Arcade Learning Environment 模拟器中评估了针对4种Atari 2600游戏的对抗性攻击,四种游戏是:Chopper Command, Pong, Seaquest, and Space Invaders.
我们用3种深度强化学习算法对每个游戏进行了训练:A3C、TRPO和DQN。
对于DQN,我们使用了与附录1相同的前处理和神经网络结构。我们也把这一结构用于经A3C和TRPO训练的随机策略。需要指出,对神经网络策略的输入是最后4副图像的连续体,从RGB转换为Luminance(Y),大小修改为to 84 × 84。Luminance value被定义为从0到1。策略的输出所有可能的action的分布。
对于每个游戏和训练算法,我们从不同的随机初始态开始训练了5个策略。我们主要关注了表现较好的训练策略(我们的定义是那些在最后10次训练迭代中拿到较大分数的80%的策略)。我们最终为每个游戏和训练算法选取了3个策略。有一些特定组合(比如Seaquest和A3C)仅有一条策略达到要求。
我们在rllab框架内部进行了实验,使用了TRPO的rllab 平行版本,并整合了DQN和A3C。我们使用OpenAI Gym enviroments作为Arcade Learning Environment的交互界面。
我们在 Amazon EC2 c4.8x large machines上用TRPO和A3C进行了策略训练。运行TRPO时每100,000步有2000次迭代,用时1.5到2天。KL散度设在0.01;运行A3C时,我们使用了18 actor-learner threads,learning rate是0.0004。对于每个策略,每1,000,000步进行200次迭代,耗时1.5到2天;运行DQN时,我们在Amazon EC2 p2.xlarge machines上进行策略训练。每代 100000步,训练2天。
这一研究方向对于神经网络策略在线上和现实世界的布局都有显著意义。我们的实验证明,即使在黑盒测试中,使用特定对抗样本仍然可以较轻易地“愚弄”神经网络策略。这些对抗性干扰在现实世界中也可能发生作用,比如在路面上特意添加的色块可能会搞晕遵循车道策略的无人驾驶汽车。因此,未来工作的一个重要方向就是发展和对抗性攻击相抵抗的防范措施,这可能包括在训练时增加对抗性干扰的样本,或者在测试时侦测对抗性输入。
论文地址:https://arxiv.org/pdf/1702.02284.pdf
参考文献
[1] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller. Playing atari with deep reinforcement learning. In NIPS Workshop on Deep Learning, 2013.
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4465.html
摘要:论文可迁移性对抗样本空间摘要对抗样本是在正常的输入样本中故意添加细微的干扰,旨在测试时误导机器学习模型。这种现象使得研究人员能够利用对抗样本攻击部署的机器学习系统。 现在,卷积神经网络(CNN)识别图像的能力已经到了出神入化的地步,你可能知道在 ImageNet 竞赛中,神经网络对图像识别的准确率已经超过了人。但同时,另一种奇怪的情况也在发生。拿一张计算机已经识别得比较准确的图像,稍作调整,...
摘要:据报道,生成对抗网络的创造者,前谷歌大脑著名科学家刚刚正式宣布加盟苹果。他将在苹果公司领导一个机器学习特殊项目组。在加盟苹果后会带来哪些新的技术突破或许我们很快就会看到了。 据 CNBC 报道,生成对抗网络(GAN)的创造者,前谷歌大脑著名科学家 Ian Goodfellow 刚刚正式宣布加盟苹果。他将在苹果公司领导一个「机器学习特殊项目组」。虽然苹果此前已经缩小了自动驾驶汽车研究的规模,但...
摘要:作者在论文中将这种新的谱归一化方法与其他归一化技术,比如权重归一化,权重削减等,和梯度惩罚等,做了比较,并通过实验表明,在没有批量归一化权重衰减和判别器特征匹配的情况下,谱归一化改善生成的图像质量,效果比权重归一化和梯度惩罚更好。 就在几小时前,生成对抗网络(GAN)的发明人Ian Goodfellow在Twitter上发文,激动地推荐了一篇论文:Goodfellow表示,虽然GAN十分擅长...
摘要:是世界上最重要的研究者之一,他在谷歌大脑的竞争对手,由和创立工作过不长的一段时间,今年月重返,建立了一个探索生成模型的新研究团队。机器学习系统可以在这些假的而非真实的医疗记录进行训练。今年月在推特上表示是的,我在月底离开,并回到谷歌大脑。 理查德·费曼去世后,他教室的黑板上留下这样一句话:我不能创造的东西,我就不理解。(What I cannot create, I do not under...
摘要:我仍然用了一些时间才从神经科学转向机器学习。当我到了该读博的时候,我很难在的神经科学和的机器学习之间做出选择。 1.你学习机器学习的历程是什么?在学习机器学习时你最喜欢的书是什么?你遇到过什么死胡同吗?我学习机器学习的道路是漫长而曲折的。读高中时,我兴趣广泛,大部分和数学或科学没有太多关系。我用语音字母表编造了我自己的语言,我参加了很多创意写作和文学课程。高中毕业后,我进了大学,尽管我不想去...

阅读 2808·2021-11-17 09:33
阅读 3146·2021-10-25 09:44
阅读 1255·2021-10-11 10:59
阅读 2465·2021-09-27 13:34
阅读 2953·2021-09-07 10:19
阅读 2195·2019-08-29 18:46
阅读 1587·2019-08-29 12:55
阅读 969·2019-08-23 17:11






