
摘要:在图像上的应用从目前的文献来看,在图像上的应用主要是往图像修改方向发展。涉及的图像修改包括单图像超分辨率交互式图像生成图像编辑图像到图像的翻译等。单图像超分辨率单图像超分辨率任务就是给定单张低分辨率图像,生成它的高分辨率图像。
今天我们来聊一个轻松一些的话题——GAN的应用。
在此之前呢,先推荐大家去读一下一篇新的文章LS-GAN(Loss-sensitive GAN)[1]。
这个文章比WGAN出现的时间要早几天,它在真实分布满足Lipschitz条件的假设下,提出了LS-GAN,并证明了它的纳什均衡解存在。它也能解决generator梯度消失的问题,实验发现不存在mode collapse的问题。
作者齐国君老师在知乎上写了一篇文章介绍LS-GAN,建议感兴趣的童鞋也去阅读一下,地址:
条条大路通罗马LS-GAN:把GAN建立在Lipschitz密度上
回到今天的主题GAN的应用上来。GAN的应用按照大类分为在图像上的应用、在NLP上的应用,以及与增强学习结合。我们分这两个大类进行介绍。今天介绍的应用不涉及算法细节(除了能简短介绍清楚的算法),基本上都有源码,参见文末。
GAN在图像上的应用
从目前的文献来看,GAN在图像上的应用主要是往图像修改方向发展。涉及的图像修改包括:单图像超分辨率(single image super-resolution)、交互式图像生成、图像编辑、图像到图像的翻译等。
单图像超分辨率
单图像超分辨率任务(SISR)就是给定单张低分辨率图像,生成它的高分辨率图像。传统方法一般是插值,但是插值不可避免地会产生模糊。GAN怎么应用到这个任务上去呢?
首先,GAN有两个博弈的对手:G(generator)和D(discriminator),容易想到一种可能的方案是:G的输入是低分辨率图像(LR),输出应该是高分辨率图像(HR)。文献[9]正是采用这种做法。作者采用ResNet作为G,网络架构如下图所示:
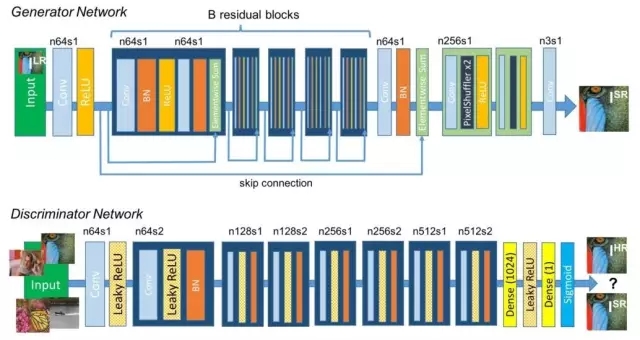

文献[9]的实验效果如下图所示,可以看出,SRGAN效果比其他方法要好,生成的图像模糊程度更低。代码参见文末的SRGAN。

此外,还有另外一个文章[3]也做了GAN在SISR上的应用,文中提出了AffGAN。这里不再展开介绍,感兴趣的同学请参看原文。
交互式图像生成
这个工作来自于Adobe公司。他们构建了一套图像编辑操作,能使得经过这些操作以后,图像依旧在“真实图像流形”上,因此编辑后的图像更接近真实图像。
具体来说,iGAN的流程包括以下几个步骤:
将原始图像投影到低维的隐向量空间
将隐向量作为输入,利用GAN重构图像
利用画笔工具对重构的图像进行修改(颜色、形状等)
将等量的结构、色彩等修改应用到原始图像上。
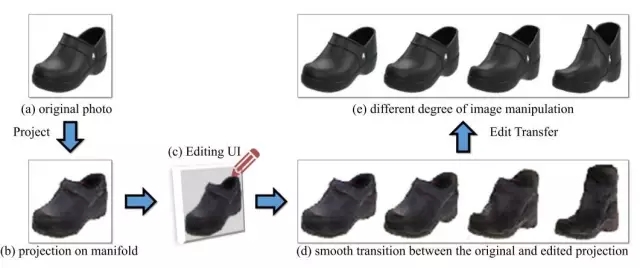
值得一提的是,作者提出G需为保距映射的限制,这使得整个过程的大部分操作可以转换为求解优化问题,整个修改过程近乎实时。细节比较多,这里不再展开,请参考文献[6],代码请参考文末的iGAN。下面的demo经过压缩图像质量比较差,查看清晰版本请移步iGAN的github页面。
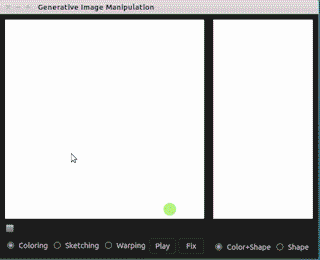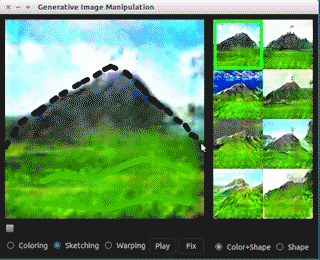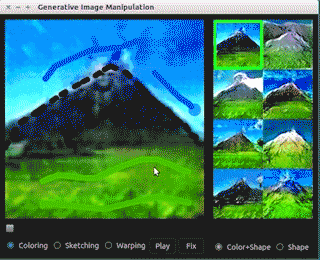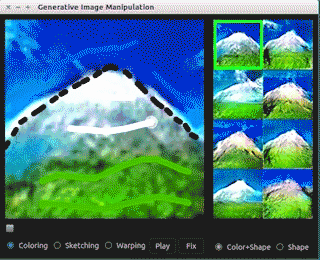
图像编辑
GAN也可以应用到图像编辑上,文献[14]提出了IAN方法(Introspective Adversarial Network),它融合了GAN和VAE(variational autoencoder,另一种生成模型)。如果你对VAE、GAN以及它们的融合都比较熟悉,理解IAN应该是很容易的。文章的主要创新在于loss的设计上。
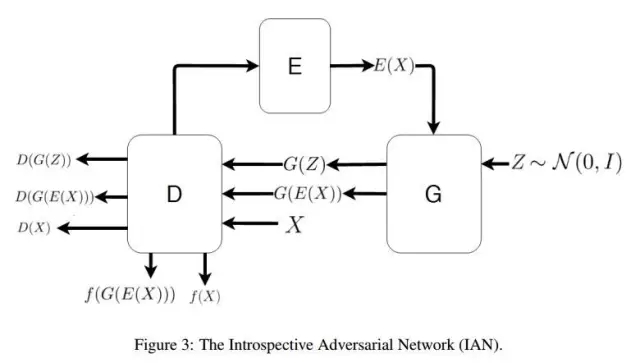
以下是IAN编辑图像的一个demo,代码可以在文末的IAN部分找到。

图像到图像的翻译
所谓“图像到图像的翻译”( image to image translation),是指将一种类型的图像转换为另一种类型的图像,比如:将草图具象化、根据卫星图生成地图等。文献[7]设计了一种算法pix2pix,将GAN应用到image to image translation上。
作者采用CGAN(conditional GAN,关于CGAN的介绍,参见两周前的推送20170203),将待转换的图像作为condition,加上高斯噪声作为generator的输入,generator将输入转换为我们需要的目标图像,而discriminator判断图像是generator产生的,还是真实的目标图像。为了能让generator产生的图像逼近真实的目标图像,generator的loss还包含目标图像匹配度的惩罚项,采用L1范数,generator的loss设计如下:
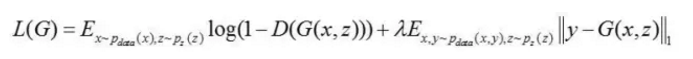
其中,y即为真实的目标图像。
然而,作者在实验中发现,generator会忽略高斯噪声z,而直接根据输入图像x产生目标图像y。为了解决这个问题,作者只在generator的某些层上以dropout的形式加入噪声(training和test时都需要dropout)。代码参见文末的pix2pix,实验效果如下图所示:

GAN在NLP上的应用
目前来说GAN在NLP上的应用可以分为两类:生成文本、根据文本生成图像。其中,生成文本包括两种:根据隐向量(噪声)生成一段文本;对话生成。
如果你对GAN在NLP中的应用感兴趣,推荐阅读下面的文章:
http://www.machinedlearnings.com/2017/01/generating-text-via-adversarial-training.html
或者可以查看AI100翻译的版本:
http://mp.weixin.qq.com/s/-lcEuxPnTrQFVJV61MWsAQ
我对NLP的了解比较少,这里只列举其中一部分应用。
对话生成
GAN应用到对话生成的例子,可以看这篇文章[2],文末也有相关的代码(参看GAN for Neural dialogue generation)。下图是GAN对话生成算法的伪代码,省略了很多细节:

实验效果如下图:

这个工作很有意思。可以看出,生成的对话具有一定的相关性,但是效果并不是很好,而且这只能做单轮对话。
文本到图像的翻译
GAN也能用于文本到图像的翻译(text to image),在ICML 2016会议上,Scott Reed等人提出了基于CGAN的一种解决方案[13]:将文本编码作为generator的condition输入;对于discriminator,文本编码在特定层作为condition信息引入,以辅助判断输入图像是否满足文本描述。文中用到的GAN架构如下:

作者提出了两种基于GAN的算法,GAN-CLS和GAN-INT。GAN-CLS算法如下:

GAN-INT对多种文本编码做一个加权,在这种设计下,generator的loss为:
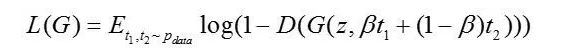
其中,β控制两种文本编码的加权系数。
实验发现生成的图像相关性很高。代码参见文末的text2image。


此外,GAN还可以跟增强学习(RL)结合。
Ian Goodfellow指出,GAN很容易嵌入到增强学习(reinforcement learning)的框架中。例如,用增强学习求解规划问题时,可以用GAN学习一个actions的条件概率分布,agent可以根据生成模型对不同的actions的响应,选择合理的action。
GAN与RL结合的典型工作有:将GAN嵌入模仿学习(imitation learning)中[5];将GAN嵌入到策略梯度算法(policy gradient)中[11],将GAN嵌入到actor-critic算法中[15],等。
GAN与增强学习结合的相关工作多数在16年才开始出现,GAN和RL属于近年来的研究热点,两者结合预计在接下来的一两年里将得到更多研究者的青睐。
常见GAN
最后,作为GAN专题的结尾,我们列举一下目前常见的GAN模型(可以根据arxiv id去寻找、下载文献),欢迎补充。
GAN - Ian Goodfellow, arXiv:1406.2661v1
DCGAN - Alec Radford & Luke Metz, arxiv:1511.06434
CGAN - Mehdi Mirza, arXiv:1411.1784v1
LAPGAN - Emily Denton & Soumith Chintala, arxiv: 1506.05751
InfoGAN - Xi Chen, arxiv: 1606.03657
PPGAN - Anh Nguyen, arXiv:1612.00005v1
WGAN - Martin Arjovsky, arXiv:1701.07875v1
LS-GAN - Guo-Jun Qi, arxiv: 1701.06264
SeqGAN - Lantao Yu, arxiv: 1609.05473
EBGAN - Junbo Zhao, arXiv:1609.03126v2
VAEGAN - Anders Boesen Lindbo Larsen, arxiv: 1512.09300
......
此外,还有一些在特定任务中提出来的模型,如本期介绍的GAN-CLS、GAN-INT、SRGAN、iGAN、IAN等等,这里就不再列举。
代码
LS-GAN
Torch版本:https://github.com/guojunq/lsgan
SRGAN
Tensorflow版本:https://github.com/buriburisuri/SRGAN
Torch版本:https://github.com/leehomyc/Photo-Realistic-Super-Resoluton
Keras版本:https://github.com/titu1994/Super-Resolution-using-Generative-Adversarial-Networks
iGAN
Theano版本:https://github.com/junyanz/iGAN
IAN
Theano版本:https://github.com/ajbrock/Neural-Photo-Editor
Pix2pix
Torch版本:https://github.com/phillipi/pix2pix
Tensorflow版本:https://github.com/yenchenlin/pix2pix-tensorflow
GAN for Neural dialogue generation
Torch版本:https://github.com/jiweil/Neural-Dialogue-Generation
Text2image
Torch版本:https://github.com/reedscot/icml2016
Tensorflow+Theano版本:https://github.com/paarthneekhara/text-to-image
GAN for Imitation Learning
Theano版本:https://github.com/openai/imitation
SeqGAN
Tensorflow版本:https://github.com/LantaoYu/SeqGAN
参考文献
Qi G J. Loss-Sensitive Generative Adversarial Networks onLipschitz Densities[J]. arXiv preprint arXiv:1701.06264, 2017.
Li J, Monroe W, Shi T, et al. Adversarial Learning for NeuralDialogue Generation[J]. arXiv preprint arXiv:1701.06547, 2017.
Sønderby C K, Caballero J, Theis L, et al. Amortised MAPInference for Image Super-resolution[J]. arXiv preprint arXiv:1610.04490, 2016.
Ravanbakhsh S, Lanusse F, Mandelbaum R, et al. Enabling DarkEnergy Science with Deep Generative Models of Galaxy Images[J]. arXiv preprintarXiv:1609.05796, 2016.
Ho J, Ermon S. Generative adversarial imitationlearning[C]//Advances in Neural Information Processing Systems. 2016:4565-4573.
Zhu J Y, Krähenbühl P, Shechtman E, et al. Generative visualmanipulation on the natural image manifold[C]//European Conference on ComputerVision. Springer International Publishing, 2016: 597-613.
Isola P, Zhu J Y, Zhou T, et al. Image-to-image translationwith conditional adversarial networks[J]. arXiv preprint arXiv:1611.07004,2016.
Shrivastava A, Pfister T, Tuzel O, et al. Learning fromSimulated and Unsupervised Images through Adversarial Training[J]. arXivpreprint arXiv:1612.07828, 2016.
Ledig C, Theis L, Huszár F, et al. Photo-realistic singleimage super-resolution using a generative adversarial network[J]. arXivpreprint arXiv:1609.04802, 2016.
Nguyen A, Yosinski J, Bengio Y, et al. Plug & playgenerative networks: Conditional iterative generation of images in latentspace[J]. arXiv preprint arXiv:1612.00005, 2016.
Yu L, Zhang W, Wang J, et al. Seqgan: sequence generativeadversarial nets with policy gradient[J]. arXiv preprint arXiv:1609.05473,2016.
Lotter W, Kreiman G, Cox D. Unsupervised learning of visualstructure using predictive generative networks[J]. arXiv preprintarXiv:1511.06380, 2015.
Reed S, Akata Z, Yan X, et al. Generative adversarial textto image synthesis[C]//Proceedings of The 33rd International Conference onMachine Learning. 2016, 3.
Brock A, Lim T, Ritchie J M, et al. Neural photo editingwith introspective adversarial networks[J]. arXiv preprint arXiv:1609.07093,2016.
Pfau D, Vinyals O. Connecting generative adversarialnetworks and actor-critic methods[J]. arXiv preprint arXiv:1610.01945, 2016.
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4463.html
摘要:作者在论文中将这种新的谱归一化方法与其他归一化技术,比如权重归一化,权重削减等,和梯度惩罚等,做了比较,并通过实验表明,在没有批量归一化权重衰减和判别器特征匹配的情况下,谱归一化改善生成的图像质量,效果比权重归一化和梯度惩罚更好。 就在几小时前,生成对抗网络(GAN)的发明人Ian Goodfellow在Twitter上发文,激动地推荐了一篇论文:Goodfellow表示,虽然GAN十分擅长...
摘要:但年在机器学习的较高级大会上,苹果团队的负责人宣布,公司已经允许自己的研发人员对外公布论文成果。苹果第一篇论文一经投放,便在年月日,斩获较佳论文。这项技术由的和开发,使用了生成对抗网络的机器学习方法。 GANs「对抗生成网络之父」Ian Goodfellow 在 ICCV 2017 上的 tutorial 演讲是聊他的代表作生成对抗网络(GAN/Generative Adversarial ...
摘要:也是相关的,因为它们已经成为实现和使用的主要基准之一。在本文发表之后不久,和中有容易获得的不同实现用于测试你所能想到的任何数据集。在这篇文章中,作者提出了对训练的不同增强方案。在这种情况下,鉴别器仅用于指出哪些是值得匹配的统计信息。 本文不涉及的内容首先,你不会在本文中发现:复杂的技术说明代码(尽管有为那些感兴趣的人留的代码链接)详尽的研究清单(点击这里进行查看 链接:http://suo....
摘要:引用格式王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃生成对抗网络的研究与展望自动化学报,论文作者王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃摘要生成式对抗网络目前已经成为人工智能学界一个热门的研究方向。本文概括了的研究进展并进行展望。 3月27日的新智元 2017 年技术峰会上,王飞跃教授作为特邀嘉宾将参加本次峰会的 Panel 环节,就如何看待中国 AI学术界论文数量多,但大师级人物少的现...
摘要:判别器胜利的条件则是很好地将真实图像自编码,以及很差地辨识生成的图像。 先看一张图:下图左右两端的两栏是真实的图像,其余的是计算机生成的。过渡自然,效果惊人。这是谷歌本周在 arXiv 发表的论文《BEGAN:边界均衡生成对抗网络》得到的结果。这项工作针对 GAN 训练难、控制生成样本多样性难、平衡鉴别器和生成器收敛难等问题,提出了改善。尤其值得注意的,是作者使用了很简单的结构,经过常规训练...

阅读 782·2021-11-24 10:19
阅读 1175·2021-09-13 10:23
阅读 3498·2021-09-06 15:15
阅读 1826·2019-08-30 14:09
阅读 1749·2019-08-30 11:15
阅读 1895·2019-08-29 18:44
阅读 991·2019-08-29 16:34
阅读 2510·2019-08-29 12:46






