
摘要:在最近的会议上,吴恩达分享了关于深度学习的一些看法。深度学习较大的优势在于它的规模,从吴恩达总结的下图可以看出当数据量增加时,深度学习模型性能更好。深度学习模型如此强大的另一个原因,是端到端的学习方式。然而,深度学习却使它有了一点变化。
在最近的 NIPS 2016 会议上,吴恩达分享了关于深度学习的一些看法。我们在此做一个整理。
深度学习较大的优势在于它的规模,从吴恩达总结的下图可以看出:
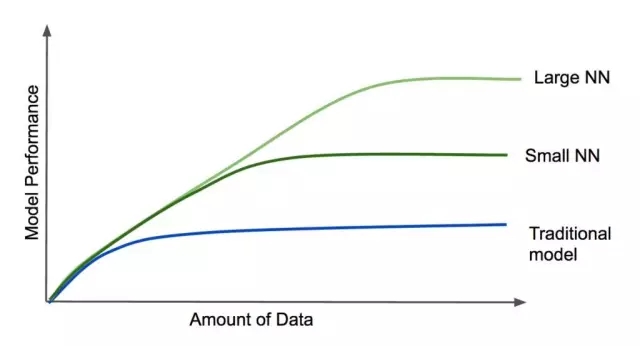
当数据量增加时,深度学习模型性能更好。除此之外,神经网络越大(即层数更多,更复杂),它在大数据集下表现的性能就越好,这不同于传统模型,传统模型的性能一旦达到一定水平,即使向模型添加数据或增加模型复杂度,也不一定能提升其性能。
深度学习模型如此强大的另一个原因,是端到端的学习方式。传统模型中特征工程(它包括两个方面:特征选择和特征提取)非常重要。例如,能够对人的声音进行转录的模型,常常需要对输入进行多个中间步骤的处理,如找到音素,正确分段,以及对片段进行单词匹配。
深度学习模型通常不需要特征工程。你可以端到端地训练他们,只需要给模型输入大量例子即可。然而,工程师们在构建模型时也还是要努力的,只不过传统模型侧重于特征提取,而深度学习模型则侧重于模型的架构。数据科学家需要不断的尝试神经元类型、神经网络的层数以及连接的方式等。
构建模型的难点
深度学习模型的构建是一个很大的挑战任务。为了使模型能有较好的性能,在构建的过程中需要做很多决策。一旦走上了错误的路线,就将浪费很多时间和金钱。那么在改善模型性能时,数据科学家如何才能做出明智的决策,给出下一步操作呢?吴恩达向我们展示了他用于开发模型的经典决策框架,不过这次他将其扩展到了其他案例上。
让我们从头开始:在分类任务中(例如,根据扫描图像做出诊断),我们可以从以下三方面得到一些关于模型错误来源的想法:
人类专家
训练集
交叉验证(CV)集(也称为开发集)
一旦我们了解这些错误的来源,数据科学家就可以遵循基本的工作流程,在模型构建中做出有效决策。那么,第一个问题是你的训练集错误率高吗?如果是,那么模型还不够好,你可能需要换一个架构,让模型更复杂一些(例如,更大的神经网络),或者需要更长时间的训练。重复这个过程,直到 bias 降低。
一旦训练集错误率降低,就可以着眼于降低 CV 集错误率。如果 CV 集错误率很大的话,variance 也会很高,这就意味着需要更多的数据,更多的正则化或新的模型架构。剩下的事情就是重复,直到模型在训练集和 CV 集中均有较好性能。
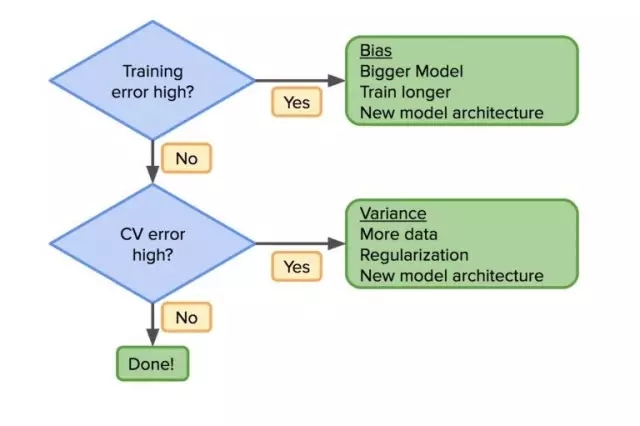
所有这些都不是新东西。然而,深度学习却使它有了一点变化。如果你的模型不是足够好,那么一个办法就是:增加你的数据或使你的模型更复杂。在传统模型中,使用正则化来寻找折中的方法,或者是生成新的特征,然而这并不总是容易的。但是通过深度学习,我们有了更好的工具来减少这两个错误。
人工数据集下的 bias/variance 调优过程
如果大规模数据集的获取不怎么容易的话,替代方法是构建你自己的训练数据集。就拿语音识别系统的训练来说,你可以通过向同一语音样本添加噪声的方式来创建人工数据集。然而,这样构建的训练集与真实数据集的分布会不相同。这种情况下,就需要考虑 bias/variance 折中策略。
想象一下,对语音识别模型,我们有50,000小时的生成数据,但只有100小时的真实数据。在这种情况下,较好的方法是从同一分布中获取 CV 集和测试集。因此,将生成数据集作为训练集,将真实数据集分成 CV 集和测试集两部分。否则,CV 集和测试集将有不同的分布,当模型“完成”时,这个问题就会出现。由于问题是由 CV 集引起的,因此它应该尽可能地接近真实数据集。
在实践中,吴恩达建议将人工数据集分为两部分:训练集和 CV 集(只占很小一部分)。这样,我们将测量以下错误:
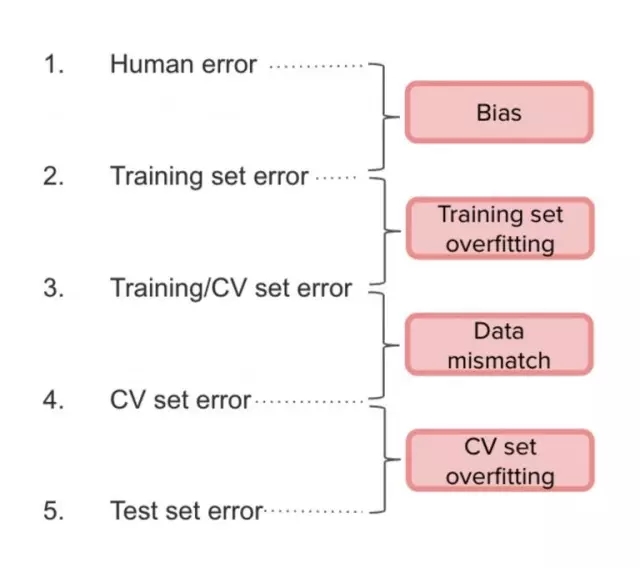
(1)和(2)之间的间隔是 bias,(2)和(3)之间是 variance,(3)和(4)之间是由于数据分布不匹配,(4)和(5)之间是因为过拟合。
考虑到这一点,先前的工作流程应该这样修改:
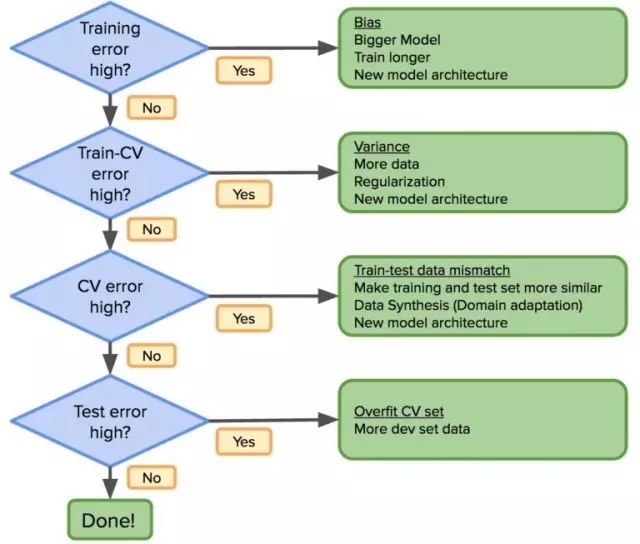
如果分布误差很大,那么修改训练数据分布使其尽可能与测试数据相似。正确理解 bias-variance 问题,可以在机器学习的应用中取得更快进展。
人类较高水平
了解人类的较高水平是非常重要的,因为这将指导如何做决策。事实证明,一旦模型超过了人类的性能,改进将会变得困难,因为我们越来越接近“完美模型”——即没有模型可以做得更好(“贝叶斯模型”)。但传统模式不会有这样的问题,因为它很难在实现超人类水平的性能,但在深度学习中却很常见。
因此,当构建模型时,应以人类较高水平的错误率(这将是“贝叶斯模型”的代表)作参考。例如,如果一个医生团队胜过一个专家团队,那么就使用医生团队的错误率。
我如何成为一个优秀的数据科学家?
多多地阅读论文和重复实验结果是成为一个优秀数据科学家的较佳也是最可靠的路径。这是吴恩达在他的学生身上看到的一种模式,也是我个人觉得不错的模式。
即使你做的全是“dirty work”——清洁数据,调整参数,调试,优化数据库等,也不要停止阅读论文和复现模型,因为复现别人的工作最终会带来原创的思想。
本文作者 Manuel Sánchez Hernández 目前是 Schibsted 的一名数据科学家,就职于 Schibsted 媒体集团。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4460.html
摘要:针对这个问题,第四范式创始人首席执行官戴文渊近日就在公司内部分享上,向大家介绍了机器学习教材中的七个经典问题。所以今天我就想和大家分享一下机器学习教材中的一些经典问题,希望对大家今后的工作和学习有所帮助。 *如果希望了解机器学习,或者已经决定投身机器学习,你会第一时间找到各种教材进行充电,同时在心中默认:书里讲的是牛人大神的毕生智慧,是正确无误的行动指南,认真学习就能获得快速提升。但实...
摘要:第一条是关于深度学习的晚宴,讨论的是背后的数学支撑,以及未来的方向。大数据与深度学习是一种蛮力尽管当场说了很多观点,但是最核心的还是援引了爱因斯坦关于上帝的隐喻。不过,我自己并不同意深度学习必须等同于机器蛮力。 Vladimir Vapnik 介绍:Vladimir Vapnik 被称为统计学习理论之父,他出生于俄罗斯,1990 年底移居美国,在美国贝尔实验室一直工作到 2002 年,之后加...
摘要:福布斯昨日刊登专访。生于英国,被认为是机器学习的先锋,现在是多伦多大学教授,谷歌高级研究员。但是,正如我所说,已经跨越过了这一分水岭。 《福布斯》昨日刊登Geoff Hinton专访。游走在学术和产业的AI大神Hinton谈到了自己研究兴趣的起源、在多伦多大学和谷歌所做的研究工作以及发起的私人俱乐部 NCAP。 在采访中,Hinton谈到,现在计算能力和数据的发展让AI获得巨大进步,并且在很...

阅读 1382·2021-11-22 09:34
阅读 2238·2021-10-08 10:18
阅读 1787·2021-09-29 09:35
阅读 2527·2019-08-29 17:20
阅读 2189·2019-08-29 15:36
阅读 3454·2019-08-29 13:52
阅读 843·2019-08-29 12:29
阅读 1237·2019-08-28 18:10




