
摘要:两者取长补短,所以深度学习框架在年,迎来了前后端开发的黄金时代。陈天奇在今年的中,总结了计算图优化的三个点依赖性剪枝分为前向传播剪枝,例已知,,求反向传播剪枝例,,求,根据用户的求解需求,可以剪掉没有求解的图分支。
虚拟框架杀入
从发现问题到解决问题
半年前的这时候,暑假,我在SIAT MMLAB实习。
看着同事一会儿跑Torch,一会儿跑MXNet,一会儿跑Theano。
SIAT的服务器一般是不给sudo权限的,我看着同事挣扎在编译这一坨框架的海洋中,开始思考:
是否可以写一个框架:

这样,利用工厂模式只编译执行部件的做法,只需编译的后端即可,框架的不同仅仅在于前端脚本的不同。
Caffe2Keras的做法似乎是这样,但Keras本身是基于Theano的编译后端,而我们的更希望Theano都不用编译。
当我9月份拍出一个能跑cifar10的大概原型的时候:
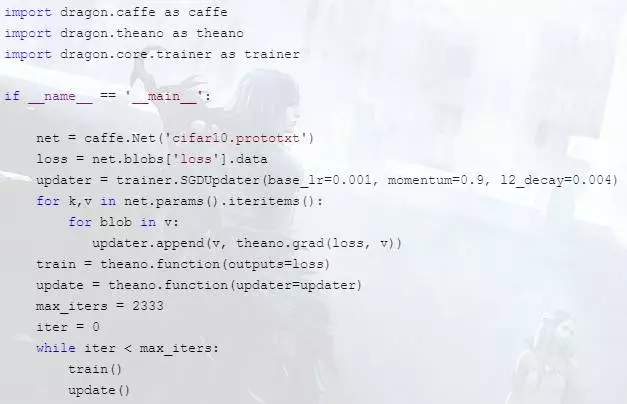
我为这种怪异的写法取名叫CGVM(Computational Graph Virtual Machine)然后过了几天,在微博上看到了陈天奇在MXNet的进一步工作NNVM的发布 .....
NNVM使用2000行模拟出了TensorFlow,我大概用了500行模拟出了Caffe1。
VM(Virtual Machine)的想法其实是一个很正常的想法,这几年我们搞了很多新框架,名字一个比一个炫,但是本质都差不多,框架的使用者实际上是苦不堪言的:
○ 这篇paper使用了A框架,我要花1天配置A框架。
○ 这篇paper使用了B框架,我要花1天配置B框架。
.......
正如LLVM不是一种编译器,NNVM也不是一种框架,看起来更像是框架的屠杀者。
NNVM的可行性恰恰证明了现行的各大框架底层的重复性,而上层的多样性只是一个幌子。
我们真的需要为仅仅是函数封装不同的框架买单吗?这是值得思考的。
计算图走向成熟

计算图的两种形式
计算图最早的出处应该是追溯到Bengio在09年的《Learning Deep Architectures for AI》,Bengio使用了有向图结构来描述神经网络的计算:
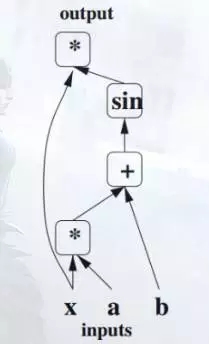
如图,符号集合{*,+,sin} 构成图的结点,整张图可看成三部分:输入结点、输出结点、从输入到输出的计算函数。
随后在Bengio组的Theano框架执行中,Graph就被隐式应用于Op的连接。
不过这时候,Op还是执行时-动态编译的。
Caffe1中计算图其实就是Net,因为Net可以被Graph模拟出来(CGVM和Caffe2Keras都实现了)。
贾扬清在Caffe1中显式化了计算图的表示,用户可以通过编辑net.prototxt来设计计算图。
Caffe1在Jonathan Long和Evan Shelhamer接手后,他们开发了PyCaffe。
PyCaffe通过Python天然的工厂(__getattr__),实现了net.prototxt的隐式生成。
之后的Caffe2,也就直接取消了net.prototxt的编辑,同样利用Python的(__getattr__)获取符号类型定义。
Caffe1带来一种新的计算图组织Op的描述方式,不同于Theano直接翻译Op为C执行代码,然后动态编译,软件工程中的高级设计模式——工厂模式被广泛使用。
计算图被划分为三个阶段,定义阶段、构造阶段、执行阶段:
1、定义阶段:定义Layer/Op的name、type、bottom(input),top(output)及预设参数。
2、构造阶段:通过工厂模式,由字符串化的定义脚本构造类对象。
3、执行阶段:根据传入的bottom(input),得到额外参数(如shape),此时计算图才能开始执行。阶段划分带来的主要问题是限制了编译代码的完整性和优化程度。
在Theano中,C代码生成是最后一步,编译前你可以组合数个细粒度符号,依靠编译器做一次硬件执行上的优化。
而工厂模式编译符号时只考虑了单元,编译器没有上下文可供参考优化,故最终只能顺序执行多个预先编译的符号单元。
当符号粒度过细时,一个Layer的实现就会变成连续执行多个子过程,导致“TensorFlowSlow”。
计算图作为中间表示(IR)
PyCaffe和Caffe2将定义阶段移到Python中,而将构造和执行阶段保留在C++中做法,是计算图作为IR的思想启蒙。
Python与C++较大的不同在于:一个是脚本代码,用于前端。一个是本地代码,用于后端。
脚本代码创建/修改模型方便(无需因模型变动而重新编译)、执行慢,本地代码则正好相反。
两者取长补短,所以深度学习框架在2016年,迎来了前后端开发的黄金时代。
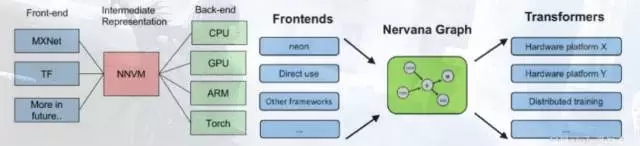
如上图,无论是9月份先提出的NNVM,还是最近Intel曝光的Nervana,都分离了前后端。
后端的独立,不仅减少了编译工作,较大的优势在于降低了传统框架做跨设备计算的代码耦合度。
在paper每周都有一大堆的现在,如果后端的每一次变动都要大量修改前端,那么框架的维护开销是非常大的。
在前端定义用于描述输入-输出关系的计算图有着良好的交互性,我们可以通过函数和重载脚本语言的操作符,定义出媲美MATLAB的运算语言,这些语言以显式的Tensor作为数据结构,Operator作为计算符和函数,Theano和MXNet都是这样隐蔽处理由表达式向计算图过渡的。
而Caffe2则比较直接,你需要先创建一个Graph,然后显示地调用Graph.AddOperator(xxx) TensorFlow同样可以显式化处理Graph。
与用户交互得到的计算图描述字串是的,但是与用户交互的方式却是不的。
所以IR之上,分为两派:
第一派要搞自己的API,函数封装非常有个性,宣示这是自己的专利、独门语言。
第二派不搞自己的API,反而去模拟现有的API,表示我很低调。
显然,用户更喜欢用自己熟悉框架的写法去描述模型,不喜欢天天背着个函数速查手册。
计算图优化
用于中间表示得到的计算图描述较好不要直接构造,因为存在冗余的求解目标,且可共享变量尚未提取。
当限制计算图描述为有向无环图(DAG)时,一些基本的图论算法便可应用于计算图描述的化简与变换。
陈天奇在今年的MSR Talk:Programming Models and Systems Design for Deep Learning中,总结了计算图优化的三个点:
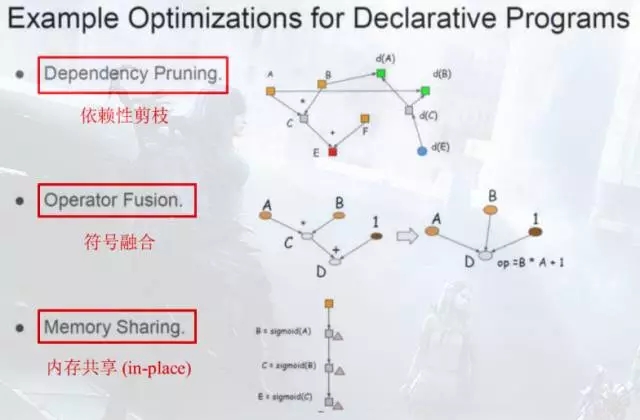
①依赖性剪枝
分为前向传播剪枝,例:已知A+B=X,A+B=Y,求X?
反向传播剪枝, 例:A+B=X,A+B=Y,求X、Y,dX/dA?
根据用户的求解需求,可以剪掉没有求解的图分支。
②符号融合
符号融合的自动实现是困难的,因为Kernel基本不再实时编译了,所以更多体现在符号粗细粒度的设计上。
粗粒度的符号融合了数个细粒度的符号,一次编译出连续多个执行步骤的高效率代码。
粗粒度和细粒度并无好坏区分,一个速度快,一个更灵活。
从贪心角度,VM框架通常会提供粗细粒度两种实现給用户,因而需要更多人力维护编译后端。
③内存共享
Caffe1对于激活函数大多使用的inplace处理——即bottom和top是同一个Blob。
inplace使用新的输出y立即覆盖的输入x,需要以下两个条件:
1、bottom和top数量都为1,即:计算图中构成一条直线路径,
2、d(y)/d(x)与x是无关的,所以x被y覆盖不影响求导结果。
常见的激活函数都符号以上两个条件,因而可以减少内存的开销。
但是Caffe1在多网络内存共享优化上极其糟糕的,以至于Caffe1并不适合用来跑GAN,以及更复杂的网络。
一个简单例子是交叉验证上的优化:训练网络和验证网络的大部分Layer都是可以共享的,但是由于Caffe1错误地将Blob独立的放在每个Net里,使得跨Net间很难共享数据。
除此之外,Caffe1还错误地将临时变量Blob独立放在每个Layer里,导致列卷积重复占用几个G内存。
让Net和Layer都能共享内存,只需要将Tensor/Blob置于最顶层,采用MVC来写框架即可。
Caffe2引入了Workspace来管理Tensor,并将工作空间的指针传给每一个Op、每一个Graph的构造函数。
新的风暴已经出现

VM的侧重点
CGVM和NNVM的侧重点是不太一样的,CGVM更强调前端上的扩展化,后端上的化。
所以CGVM不会去支持Torch编译后端,也不会去支持Caffe编译后端。
在NNVM的知乎讨论帖中,有一种观点认为VM是轻视Operator的实现。
但实际上,我们手里的一堆框架,在Operator、Kernel、Math级别的不少实现是没有多少区别的。
但恰恰折磨用户的正是这些没有多少区别的编译后端:各种依赖库、装Linux、编译各种错。
所以我个人更倾向整个DL社区能够提供一份完善的跨平台、跨设备解决方案,而不是多而杂的备选方案。
从这点来看,CGVM似乎是一个更彻底的框架杀手,但在ICML"15上, Jürgen Schmidhuber指出:
真正运行AI 的代码是非常简短的,甚至高中生都能玩转它。不用有任何担心会有行业垄断AI及其研究。
简短的AI代码,未必就是简单的框架提供的,有可能是自己熟悉的框架,这种需求体现在前端而不是后端。
VM指出了一条多框架混合思路:功能A,框架X写简单。功能B,框架Y写简单。
功能A和功能B又要end-to-end,那么显然混起来用不就行了。
只有使用频率不高的框架才会消亡,VM将框架混合使用后,熟悉的味道更浓了,那么便构不成”框架屠杀者“。
强大的AI代码,未必就是VM提供的,有可能是庞大的后端提供的。
随着paper的快速迭代,后端的扩展仍然是最繁重的编程任务。
VM和后端侧重点各有不同,难分好坏。但分离两者的做法确实是成功的一步。
VM的形式
VM及计算图描述方式是连接前后端的桥梁。
即便后端是的,根据支持前端的不同,各家写的VM也很难统一。
实际上这就把框架之间的斗争引向了VM之间的斗争。
两人见面谈笑风生,与其问对方用什么框架,不如问对方用什么VM。
VM的主要工作
合成计算图描述的过程是乏味的,在Caffe1中,我们恐怕已经受够了人工编辑prototxt。
API交互方面,即便是MXNet提供给用户的API也是复杂臃肿的,或许仍然需要一个handbook。
TensorFlow中的TensorBoard借鉴了WebOS,VM上搞一个交互性更强的操作系统也是可行的。
除此之外,我可能比较熟悉一些经典框架,那么不妨让VM去实现那些耳熟能详的函数吧!
1、模拟Theano.function
Theano的function是一个非常贴近数学表达计算图掩饰工具。function内部转化表达式为计算图定义,同时返回一个lambda函数引向计算图的执行。总之这是一个百看不腻的API。
2、模拟Theano.grad
结合计算图优化,我们现在可以指定任意一对求导二元组(cost, wrt)。因而,放开手,让自动求导在你的模型中飞舞吧。
3、模拟Theano.scan
Theano.scan是一个用来搭建RNN的神器。尽管最近Caffe1更新了RNN,但是只支持固定循环步数的RNN。而Theano.scan则可以根据Tensor的shape,为RNN建动态的计算图,这适合在NLP任务中处理不定长句子。
4、模拟PyCaffe
PyCaffe近来在RCNN、FCN、DeepDream中得到广泛应用,成为搞CV小伙伴们的最爱。PyCaffe大部分是由C++数据结构通过Boost.Python导出的,不幸的是,Boost.Thread导出之后与Python的GIL冲突,导致PyCaffe里无法执行C++线程。尝试模拟移除Boost.Python后的PyCaffe,在Python里把Solver、Net、Layer給写出来吧。
5、模拟你熟悉的任意框架
.......等等,怎么感觉在写模拟器.....当然写模拟器基本就是在重复造轮子,这个在NNVM的知乎讨论帖中已经指明了。
VM的重要性
VM是深度学习框架去中心化、解耦化发展迈出的重要一步。
同时暴露了目前框架圈混乱的本质:计算图之下,众生平等。计算图之上,群魔乱舞。
在今年我们可以看多许多框架PK对比的文章,然而大多只是从用户观点出发的简单评测。
对比之下,NNVM关注度不高、反对者还不少这种情况,确实让人感到意外。
回顾与展望
回顾2016:框架圈减肥大作战的开始
高调宣布开源XXX框架,再封装一些API,实际上已经多余了。
VM的出现,将上层接口的编写引向模拟经典的框架,从而达到减肥的目的。
框架维护者应当将大部分精力主要放在Kernel的编写上,而不是考虑搞一些大新闻。
展望2017:DL社区能否联合开源出跨平台、跨设备的后端解决方案
后端上,随着ARM、神经芯片的引入,我们迫切需要紧跟着硬件来完成繁重的编程。
后端是一个敏感词,因为硬件可以拿来卖钱,所以更倾向于闭源。
除此之外,即便出现了开源的后端,在山寨和混战之前是否能普及也是一个问题。
展望2017:来写框架吧
VM的出现,带来另一个值得思考的问题:现在是不是人人应该学写框架了?
传统框架编写的困难在代码耦合度高,学习成本昂贵。
VM流框架分离了前后端之后,前端编写难度很低,后端的则相对固定。
这样一来,框架的编程层次更加分明,Keras地位似乎要危险了。
展望2017:更快迭代的框架,更多变的风格,更难的垄断地位
相比于paper的迭代,框架的迭代似乎更快了一点。
余凯老师前段时间发出了TensorFlow垄断的担忧,但我们可以很乐观地看到:越来越多的用户,在深入框架的底层。
TensorFlow并不是较好的框架,MXNet也不是,较好的框架是自己用的舒服的框架,较好是一行行自己敲出来的。
如果你已经积累的数个框架的使用经验,是时候把它们无缝衔接在一起了。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4450.html
摘要:亚马逊和华盛顿大学今天合作发布了开源的端到端深度学习编译器。项目作者之一陈天奇在微博上这样介绍这个编译器我们今天发布了基于工具链的深度学习编译器。陈天奇团队对的性能进行了基准测试,并与进行了比较。 亚马逊和华盛顿大学今天合作发布了开源的端到端深度学习编译器NNVM compiler。先提醒一句,NNVM compiler ≠ NNVM。NNVM是华盛顿大学博士陈天奇等人2016年发布的模块化...
摘要:在此,我们将借用和的算子,分析硬件加速的需求。池化层池化层主要用于尺度变换,提取高维特征。此种类型主要用于深度卷积神经网络中卷积部分与部分的连接。和可以认为是的特例。 NNVM是由陈天奇团队提出的一套可复用的计算流图中间表达层,它提供了一套精简的API函数,用以构建、表达和传输计算流图,从而便于高层级优化。另外NNVM也可以作为多个深度学习框架的共享编译器,可以优化、编译和部署在多种不同的硬...
摘要:本届会议共收到论文篇,创下历史记录有效篇。会议接收论文篇接收率。大会共有位主旨演讲人。同样,本届较佳学生论文斯坦福大学的,也是使用深度学习做图像识别。深度学习选择深度学习选择不过,也有人对此表示了担心。指出,这并不是做学术研究的方法。 2016年的计算机视觉领域国际顶尖会议 Computer Vision and Pattern Recognition conference(CVPR2016...
摘要:毫无疑问,深度学习将驱动在公司中的应用。在其价值评估和策略评估上使用的就是深度学习。端到端的深度学习是一个令人着迷的研究领域,但是迄今为止混合系统在应用领域会更有效率。目前专注于深度学习模式,方法和战略的研究。 在之前的博客中,我曾预言过未来几年的发展趋势。我记得上一篇博客的内容是《2011年软件开发趋势和相关预言》(Software DevelopmentTrends and Predic...
摘要:深度学习框架作为热身,我们先看一下深度学习框架。在年有急剧的增长,但在过去几个月被超越。 你是否使用过 Google Trends?相当的酷,你在里面输入关键词,看一下谷歌搜索中这一词条如何随时间变化的。我想,过去 5 年中 arxiv-sanity 数据库中刚好有 28303 篇机器学习论文,为什么不做一些类似的工作,看一下过去 5 年机器学习研究有何进化?结果相当的有趣,所以我把它贴了出...

阅读 1160·2021-09-13 10:29
阅读 3473·2019-08-29 18:31
阅读 2734·2019-08-29 11:15
阅读 3088·2019-08-26 13:25
阅读 1474·2019-08-26 12:00
阅读 2523·2019-08-26 11:41
阅读 3687·2019-08-26 10:31
阅读 1581·2019-08-26 10:25






