
摘要:而自然语言处理被视为深度学习即将攻陷的下一个技术领域,在今年全球较高级的学术会议上,我们也看到大量的在深度学习引入方面的探索研究。
深度学习的出现让很多人工智能相关技术取得了大幅度的进展,比如语音识别已经逼近临界点,即将达到Game Changer水平;机器视觉也已经在安防、机器人、自动驾驶等多个领域得到应用。 而自然语言处理(NLP)被视为深度学习即将攻陷的下一个技术领域,在今年全球较高级的NLP学术会议ACL上,我们也看到大量的在深度学习引入NLP方面的探索研究。让我们跟随阿里的科学家们一起去探求深度学习给NLP带来些改变。
上篇介绍了机器翻译、机器阅读与理解、语言与视觉等方面的科学探索,下篇将介绍对话系统、信息抽取与情感分析、句法分析、词向量和句向量等相关方向的优秀研究成果。
《下篇》
4、对话系统
《On-line Active Reward Learning for Policy Optimization in SpokenDialogue Systems》,用于口语对话系统策略优化的在线自动奖励学习,来自于剑桥大学工作的Paper,也荣获了本次ACL2016学生Best Paper。此Paper提出了一种在面向任务的对话系统中,通过增强学习来优化对话管理策略,构建了一个在线学习框架:对话策略,对话镶嵌函数和基于用户反馈的主动奖励机制三部分组成,如图所示。
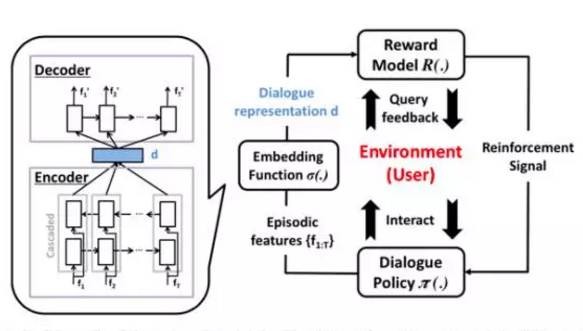
图8、在线学习框架
通过Gaussian过程分类法与一种基于神经网络的无监管式对话嵌入方法,提出了一种主动的奖赏函数学习模型。通过Reinforcement Learning的方式,主动询问客户收集更多的信息来得到较精确的奖赏函数,实现在线学习策略。相比人工语聊标注以及离线模型的方式上有很大的创新。
Paper下载地址:http://aclweb.org/anthology/P16-1230
《DocChat: An Information Retrieval Approach for Chatbot Engines UsingUnstructured Documents》,此篇长文是由微软亚洲研究院(MSRA)周明老师团队的工作。本文适合场景是聊天场景,不适用于强逻辑和知识业务匹配场景。
通常我们在做聊天对话的时候,我们有两种方式:一种是基于检索的方式(Retrieval-Based),还有一种就是基于sequence tosequence的Deep Learning生成方式,比如基于LSTM的方式。但是两种方式基于都是大量的基于QA Pair对的数据展开的工作。本文的第一个创新的点是直接依赖于非结构化RawData作为数据源输入,而不依赖标准的QA Pair对数据,通过非结构化数据中直接计算获得合适的Response。
框架技术思路设计路径还是传统的检索方式:非结构化文本按照句子进行分割,先从已有的非结构化数据集中进行召回,然后进行Ranking排序,最后进行置信度计算。其中较为核心的部分就是回复Ranking的特征选择及模型选择了,本文提出了多level特征的选择,包括:word-level, phrase-level,sentence- level, document-level, relation-level, type-level 和 topic-level。整体评测方案上其实是有提升空间的,语聊类的通过“0”和“1”的方式判断其实不是特别合适,可以修改成为对、错和相关等更为复杂的评测方案。
Paper下载地址:http://aclweb.org/anthology/P16-1049
5、信息抽取与情感分析
IE的论文今年集中在slot filling, NER,entityResolution 和coreference.Slot filling在2009 KBP 提出以来,一直以来效果不好很好,F-score大约只有30%。跟relation extraction比较而言,有跨篇章,同义词,多种关系等问题。季?团队一直保持着比较好的实验效果。此次,他们提出了一种基于图挖掘的方案,取得了明显的提升。NER也是IE比较传统的任务,今年论文的创新仍旧多基于深度学习。Coreference和 entity resolution保持了近几年colletive和知识表示两个方向上发力。
Sentiment由于学术界数据的缺乏,domain adaptation仍旧十分热,近几年domain adaptation也在使用deep learning模型。
综合来看,今年这两个课题中规中矩,有不错的创新点,但没有大的突破。
6、句法分析
句法分析可以称作是自然语言处理领域的核心任务之一,每年ACL会议上都有较大数量的相关论文和sessions。然而与过去二十年所取得的进展相比,现在的句法分析研究越来越给人一种“做无可做”的感觉(甚至一部分熟悉的研究人员已经离开这个领域)。也许宾州大学构建的标准树库所带来的红利已经消失了?
现在人们相当程度上把希望寄托在深度学习上。从某种意义上讲,这也是大势所趋:搞深度学习的希望在搞定语音和图像之后能够进一步挑战自然语言处理/理解,而做语言处理的研究者则需要深度学习来扩展自己的研究手段。句法分析同样不能例外,过去两三年,句法分析领域出现大量基于深度学习的研究工作,通过构建不同的(通常比较复杂的)网络结构。在2016年ACL工作中,我们看到研究重点回归到如何将深度学习用作更有效的工具,譬如说研究如何利用深度学习模型的非线性特点减小分析算法的计算代价,或者研究如何利用深度学习与经典方法(例如reranking)进行结合。下面会有相关论文的介绍。
句法分析领域另一个值得关注的点是实验数据的多样化。前面提到了宾州树库(英文的PTB、中文的CTB、朝鲜语的KTB)。做句法分析研究的同学都知道,这几个数据集是句法分析研究的标准数据集,从1992年开始,我们大部分句法分析实验都是在这些数据集上进行。但是近几年这几个标准数据集逐渐暴露出不足之处。因此开始出现了一些帮助研究继续往前发展的新数据集。Google在2012年推出WebTreebank,除了覆盖宾州树库原有数据以外,Web Treebank中还包含一个问句测试集和一个超大规模的无标注数据。[1]这个数据集通常用于领域适应性研究。在依存分析领域,近几年出现了Universal Dependencies,其目标是通过一套规范对多种语言进行统一的标注。[2]在成分句法分析领域,出现了覆盖八种语言的SPMRL (Morphologically rich language) 数据。[3]在新数据集上的工作开始增多。这些数据的基础性工作在某种程度上讲要比深度学习更值得研究。
依存句法分析的效率优化
依存句法分析的方法基本上可以分为两大流派:基于图的方法和基于状态转移的方法。与状态转移方法相比,基于图的方法建模能力更强,但是解码的时候需要依赖动态规划算法,难以避免具有较高的时间复杂度(状态转移方法具有线性时间复杂度);而且它的时间复杂度与采用的子图大小正相关:子图越大,复杂度越高。下图展示了从一阶到三阶的不同依存子图。为了使基于图的句法分析方法在实际应用中更加可用,有必要去研究如何使基于图的依存句法分析器跑得更快。
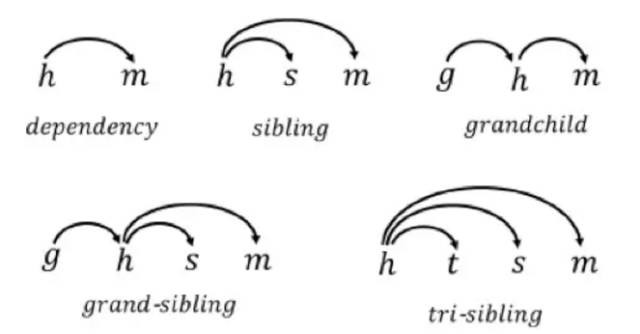
图9、一阶到三阶的不同依存子图
今年有两篇工作与这个主题相关。来自北京大学的Wang and Chang 始终采用较低阶(一阶)的依存子图进行建模,但是考虑到一阶子图的上下文信息不足,他们采用双向的LSTM对子图进行打分,以此弥补上下文信息缺失的问题。经典的基于图的模型(例如MST parser)采用MIRA模型对子图进行打分。因此这篇工作其本质是始终采用一阶子图对句法树进行拆分,但是底层的打分函数换成了双向LSTM,因此其时间复杂度仍然为O(n^3)(通过有效
剪枝可以使复杂度减小到O(n^2))。双向LSTM的网络结构如图10所示。
Wang and Chang利用了图方法的一个特性,即解码的时间复杂度与子图大小正相关。基于图的句法分析方法另一个重要特性是:解码过程实际上是在有向无环图中寻找较大生成树。如果能把有向图换成无向图,那么寻找较大生成树的算法就会简单很多。来自以色列和印度的一篇联合工作就解了这个问题。给定一个句子,首先生成无向图,基于该无向图生成(无向的)较大生成树,最终的依存树将由无向的较大生成树推导得到。
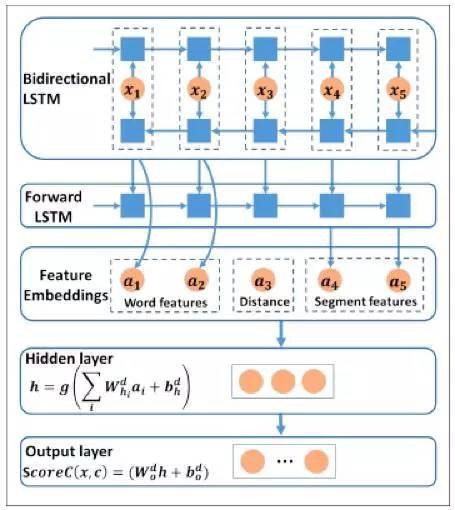
图10、双向LSTM的网络结构
基于神经网络的成分句法分析
在EMNLP2014上有一篇来自StanfordNLP组的开创性的工作(Chen and Manning, 2014),提出基于Feed-forwardNeural Network的状态转移依存分析器,它通过减少特征抽取的时间成本,造就了目前为止单机速度最快的依存句法分析器。在这项工作的基础上有一系列的后续工作(包括Google开源的SyntaxNet)都是基于该模型改进完成。很自然的产生一个想法:能否利用该网络结构进行成分句法分析的工作。来自法国的Coavoux and Crabbe今年就做了这样一篇工作。他们除了采用Chen and Manning 2014的网络结构以外,还采用了dynamic oracle技术。Dynamic oracle技术最开始也是在依存分析上首先提出的,其基本思路是:基于训练数据的标准答案(gold oracle)进行模型训练不一定是较佳的,因为在解码的时候很容易产生错误,导致无论如何也得不到gold oracle,dynamic oracle的思想就是根据当前的状态(可能是错误状态)学习一个最有利于模型优化的oracle.这项dynamic oracle技术在成分句法分析中同样有效。
7、词向量和句向量
Word Vectors和Sentence Vectors总共被安排了三场,并且被组委会安排在了较大的两个会议室(Audimax和Kinosaal),多少可以代表当前自然语言处理领域的热点话题和方向,包括在其它的一些专场(比如Semantics等)也或多或少使用到了类似的深度学习和词嵌入的技术。因为涉及到的内容比较多,以两篇文章为例:
《Compressing Neural Language Models by Sparse Word Representations》一文主要针对现在神经网络模型过大带来的时间开销以及内存占用的问题,提出了一种压缩算法使得模型的参数伴随着词典的膨胀缓慢增加,并且在Perplexity上的评估性能也有所改善。该文方法的主要优点在于:一、放松了对硬件特别是内存消耗的限制,使得模型在移动端部署大为方便;二、特别提升了对罕见词的表示效果,因为常见的神经网络语言模型无法很好地调优梯度。解决上述问题的思路在于将罕见词表示为常见词的稀疏线性组合,这一思路来源于日常生活中我们往往用几个常见词来解释一个不熟悉的词。因此将我们的目标转化为求解罕见词的最优稀疏编码(每个词4-8个)。因此最终用来压缩模型的方法定义为,对于常见词采用传统的稠密词向量的求解方式,对于罕见词采用常见词的稀疏组合来作为其向量,使用LSTM与RNN作为模型的隐藏层,而其它权重值的求解方式与传统的类似,从而达到了网络的参数数目基本与词典大小无关(或者说关系很小)。最终的实验结果从性能(Perplexity)与内存开销减少两方面来说明价值,如图11、12所示。
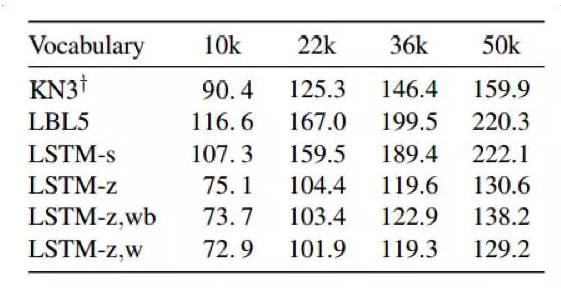
图11、压缩模型与基线在Perplexity上的性能比较

图12、模型在内存消耗上的减少(%)
另一篇很有意思的文章是来自于墨尔本大学和剑桥大学合作的《Take and Took, Gaggle and Goose, Book and Read: Evaluating theUtility of Vector Differences for Lexical Relation Learning》。从标题可以看出这是一篇探索词汇间关系的论文,这是一项非常基础并且非常重要的工作,我们日常都会用到word2vec这种非常实用的工具,但对词之间的关系并未做过多的探索,比如经典的king ? man + woman = queen或者paris ? france + poland = warsaw,作者认为两个词向量之间的差值代表了某种含义(更确切的说法是代表了两个词汇的某种关系),比如前者可能是性别关系,而后者可能是代表了首都的关系。为了证明此种关系是否可靠并且不依赖于特定的语料,作者选择了十多种典型的关系,比如整体与部分(airplane and cockpit)、行动与目标(hunt and deer)、名词与群体名词(antand army)以及单复数( dog and dogs)、过去时态(knowand knew)和第三人称形态(accept and accepts)等等大量数据,并且通过聚类得到结果,如图13;作者发现这种“通过词向量的差值来刻画词汇间关系”的方式是可靠并且具备普遍通用性的。除此之外,作者还探索了使用有监督数据集做分类的方法和应用。

图13、典型关系的聚类结果,部分离群点可能是由于多义词的影响
这方面的研究对于机器翻译和人机交互具有很强的应用价值,对这一领域的探索毫无疑问Google走在了前面,包括之前开源的word2vec,以及他们的机器翻译团队发现在英语中的这种词汇关系同样适用于西班牙语和德语等等。
除此之外,还有一个专场专门介绍Sentence Vectors,主要介绍了其在Attention Mode、Negation Scope Detection以及Summarization方面的应用。
四、总结
1、今年的ACL上,深度学习不出意外地依然成为会议的主角,并在自然语言处理的几乎所有领域的重要问题上得到大规模应用,包括:语义表示、机器翻译、信息提取、情感分析、自动问答、对话等。继深度神经网络在图像、语音等研究领域取得突破性进展后,机器翻译领域的研究者们从2013年后也开始尝试在翻译模型中引入多层神经网络模型。从最初的把神经网络语言模型作为传统SMT解码器的特征之一,到后来完全取代SMT解码器的Encoder-Decoder框架,应该说NMT在短短两年多时间里快速推进,无论是研究上还是应用上都已经隐然要取代传统SMT框架。
2、虽然端到端的神经机器翻译系统取得了很大进步,在一些公共测试集上已经追赶或超越传统的统计机器翻译系统,但它之前也存在一些难以解决的问题,比如:由于词表大小限制导致的OOV翻译问题、已翻译的词过翻或欠翻问题等,这些问题在今年的ACL论文中已经出现了部分解决方案,虽然还不能说非常完美,但至少已经看到了改进的希望。这些也是我们后续值得重点关注的工作。
3、整体的“自动化”及挖掘和利用知识还是主要的旋律,技术上Deep Learning持续火热。对比工业界目前如火如荼的大量chatbot产品,在平台化技术上要解决的其实也是这两个问题,使得chatbot更加智能。当然对比工业界目前开始逐步开始在大规模场景结合深度学习的技术,这个需要一个发展和落地的过程。本次会议中一些知识利用及对话构建机制上的思路在工业界是可以借鉴的,还有一个较为需要关注的亮点或者说工业界可以参考和需要关注的是,ReinforcementLearning的应用和发展是一个新的发声点和亮点。
4、句法分析的研究仍然不少,但是可能确实是到了一个瓶颈。目前一个思路是去研究引入深度学习,建立新的模型之后,一些“老”技术如何迁移过来。譬如说reranking技术,原来在n-best list和forest基础上取得的效果非常好,现在在neural network-based的系统上如何引入reranking,是一个值得研究的问题。今年南京大学的Hao Zhou等人就做了这样的一篇有趣的工作。另外一个就是数据,现在universal dependencies和SPMRL还不够,新数据的构建和研究还有较多的工作要做。
5、学术界是比较少研究应用的,不过也会看到一些比较有趣的可以直接应用起来的技术。譬如今年Anders Bjokelund等人做了一个句子切分和句法分析的联合模型。这个工作与之前MSRADongdong Zhang等人做的一个标点预测与句法分析联合模型相类似。假设需要对语音识别的结果进行分析理解,那么这样的一个模型应该会有比较大的作用。类似的思路,由于句法分析处于很多应用的核心位置,我们其实可以考虑把应用中的其它任务与它进行联合建模。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4423.html
摘要:而自然语言处理被视为深度学习即将攻陷的下一个技术领域,在今年全球较高级的学术会议上,我们也看到大量的在深度学习引入方面的探索研究。和也是近几年暂露头角的青年学者,尤其是在将深度学习应用于领域做了不少创新的研究。 深度学习的出现让很多人工智能相关技术取得了大幅度的进展,比如语音识别已经逼近临界点,即将达到Game Changer水平;机器视觉也已经在安防、机器人、自动驾驶等多个领域得到应用。 ...
摘要:于月日至日在意大利比萨举行,主会于日开始。自然语言理解领域的较高级科学家受邀在发表主旨演讲。深度学习的方法在这两方面都能起到作用。下一个突破,将是信息检索。深度学习在崛起,在衰退的主席在卸任的告别信中这样写到我们的大会正在衰退。 SIGIR全称ACM SIGIR ,是国际计算机协会信息检索大会的缩写,这是一个展示信息检索领域中各种新技术和新成果的重要国际论坛。SIGIR 2016于 7月17...
摘要:深度学习浪潮这些年来,深度学习浪潮一直冲击着计算语言学,而看起来年是这波浪潮全力冲击自然语言处理会议的一年。深度学习的成功过去几年,深度学习无疑开辟了惊人的技术进展。 机器翻译、聊天机器人等自然语言处理应用正随着深度学习技术的进展而得到更广泛和更实际的应用,甚至会让人认为深度学习可能就是自然语言处理的终极解决方案,但斯坦福大学计算机科学和语言学教授 Christopher D. Mannin...

阅读 3397·2021-09-09 11:39
阅读 1255·2021-09-09 09:33
阅读 1159·2019-08-30 15:43
阅读 576·2019-08-29 14:08
阅读 1754·2019-08-26 13:49
阅读 2408·2019-08-26 10:09
阅读 1572·2019-08-23 17:13
阅读 2318·2019-08-23 12:57




