
摘要:因为在每一时刻对过去的记忆信息和当前的输入处理策略都是一致的,这在其他领域如自然语言处理,语音识别等问题不大,但并不适用于个性化推荐,一个用户的听歌点击序列,有正负向之分。
在内容爆炸性增长的今天,个性化推荐发挥着越来越重要的作用,如何在海量的数据中帮助用户找到感兴趣的物品,成为大数据领域极具挑战性的一项工作;另一方面,深度学习已经被证明在图像处理,计算机视觉,自然语言处理等领域都取得了不俗的效果,但在个性化推荐领域,工程应用仍然相对空白。
本文是深度学习在个性化推荐实践应用的第二篇,在第一篇中,我详述了如何利用历史沉淀数据挖掘用户的隐藏特征,本文在上一篇的基础上进行延伸,详细分析如何利用LSTM,即长短时记忆网络来进行序列式的推荐。
1、从RBM,RNN到LSTM:
根据用户的长期历史数据来挖掘隐特征是协同过滤常用的方法,典型的算法有基于神经网络的受限玻尔兹曼机 (RBM),基于矩阵分解的隐语义模型等。历史的数据反映了用户的长期兴趣,但在很多推荐场景下,我们发现推荐更多的是短时间内的一连串点击行为,例如在音乐的听歌场景中,用户的听歌时间往往比较分散,有可能一个月,甚至更长的时间间隔才会使用一次,但每一次使用都会产生一连串的点击序列,并且在诸如音乐等推荐领域中,受环境心情的影响因素很大,因此,在这种推荐场景下,基于用户的短期会话行为(session-based) 能够更好的捕获用户当前的情感变化。
另一方面,通过用户的反馈,我们也不难发现,用户的序列点击行为并不是孤立的,当前的点击行为往往是受到之前的结果影响,同理,当前的反馈也能够影响到今后的决策,长期历史数据的隐特征挖掘无法满足这些需求。
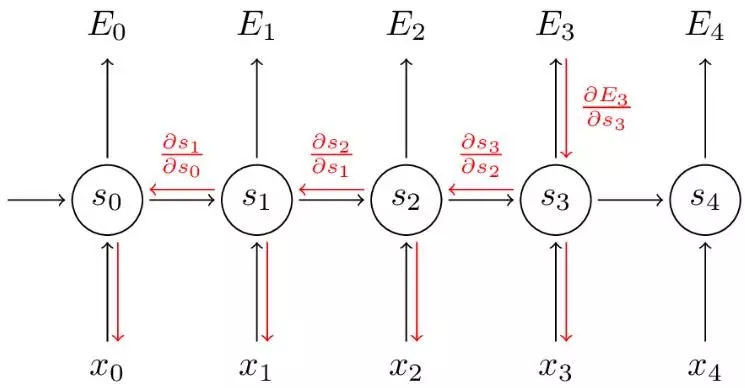
RNN是解决序列性相关问题的常用网络模型,通过展开操作,可以从理论上把网络模型扩展为无限维,也就是无限的序列空间,如下图所示:

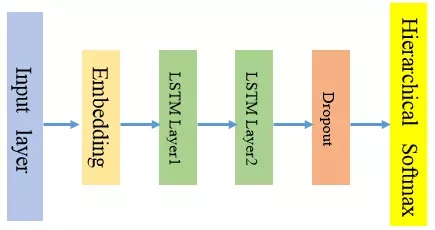
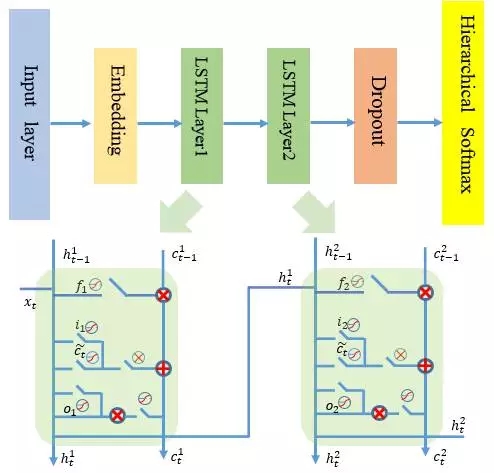
与CNN的参数共享原理一样,RNN网络在每一时刻也会共享相同的网络权重参数,这时因为网络在时间序列的不同时刻执行的是相同任务。在实际建模中,每一阶段的网络结构由输入层,embedding层,1到多个LSTM层(可以选择dropout)和层次softmax输出层构成,如下图所示,每一部分的设计思路将在后面详细讲述。
2、三“门”状态逻辑设计
从理论的角度来分析,传统的RNN采用BPTT (Backpropagation Through Time)来进行梯度求导,对V的求导较为简单直接,但对W和U的求导会导致梯度消失(Vanishing Gradients)问题,梯度消失的直接后果是无法获取过去的长时间依赖信息。
从个性化推荐的角度来看,传统的RNN还有另外一个缺点。因为RNN在每一时刻对过去的记忆信息和当前的输入处理策略都是一致的,这在其他领域(如自然语言处理,语音识别等)问题不大,但并不适用于个性化推荐,一个用户的听歌点击序列,有正负向之分。正向的数据,包括诸如听歌时长较长的歌曲,收藏,下载等;负向的听歌,包括了跳过,删除等,因此,在每一时刻的训练,需要对当前的输入数据有所区分,如果当前时刻是正向的歌曲,应该能够对后面的推荐策略影响较大,相反,如果当前时刻是负向的歌曲,应该对后面的策略影响小,或者后面的推荐策略应该避免类似的歌曲出现。
LSTM (长短时记忆网络)是对传统RNN的改进,通过引入cell state来保留过去的记忆信息,避免BPTT导致的梯度消失问题,同时,针对前面提到的个性化推荐的独有特点,我们对长短时记忆网络也进行了修改,下面来详细分析如何在个性化推荐中设计合理的门逻辑:
Forget gate (忘记门):这一步是首先决定要从前面的“记忆”中丢弃哪些信息或丢弃多少信息,比如,之前可能对某一位歌手或者某一个流派的歌曲特别感兴趣,这种正向操作的记忆需要得到保留,并且能够影响今后的决策。“门”开关通过sigmoid函数来实现,当函数值越接近于1时,表示当前时刻保留的记忆信息就越多,并把这些记忆带到下一阶段;当函数值接近于0时,表示当前时刻丢弃的记忆就越多。

Input gate(输入门): 这一步由两部分构成,第一部分是决定当前时刻的歌曲有多少信息会被加入到新的记忆中,如果是正向的歌曲,传递的信息就会越多,相反,对于负向歌曲,传递的信息就会越少。
第二部分是当前阶段产生的真实数据信息,它是通过tanh函数把前面的记忆与当前的输入相结合而得到。
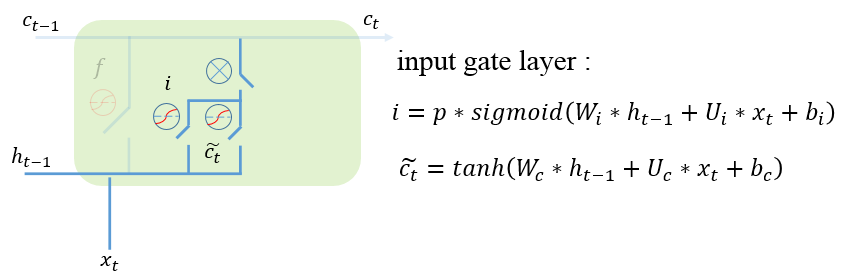
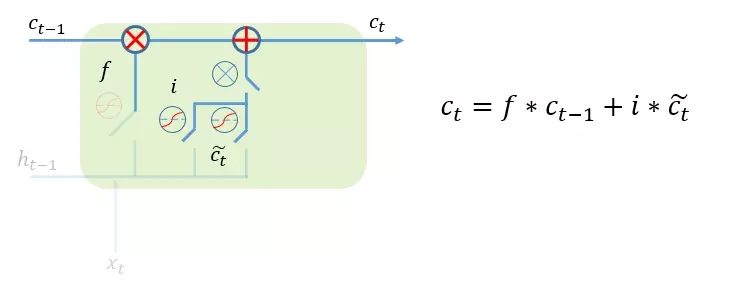
经过前面两个门的设计,我们可以对cell state进行更新,把旧的记忆状态通过与forget gate相结合,丢弃不需要的信息,把当前的输入信息与input gate相结合,加入新的输入数据信息,如下图所示:
output gate (输出门):这一步是把前面的记忆更新输出,通过输出门开关来控制记忆流向下一步的大小,确定哪些信息适合向后传播。
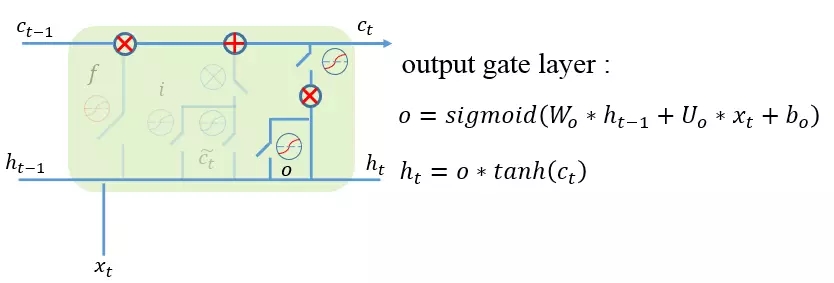
到此为止,序列中每一阶段的门逻辑设计也完成了,最终的LSTM层设计如下图所示:
小技巧:在代码实现的时候,我们应该能够发现上面提到的三个门运算和cell state的计算除了激活函数稍有不同外,它们具有下面的相同线性操作公式:

经过这样的改造后,原来需要多带带执行四步的操作,现在只需要一次矩阵运算就能完成,这一技巧使得训练速度提升非常明显。
3、时序规整与并行化设计
普通的递归网络(或者是其变种,LSTM,GRU等)每一次训练会因为训练数据间的序列长度不相等,需要多带带训练,对于上亿条的流水训练数据来说,这种做法显然是不可行的,为此我们需要对输入数据做时序的补齐,具体来说就是把batch_size的训练样本集中起来,取点击最长的序列长度作为矩阵的行数,其余样本数据用0来补齐。
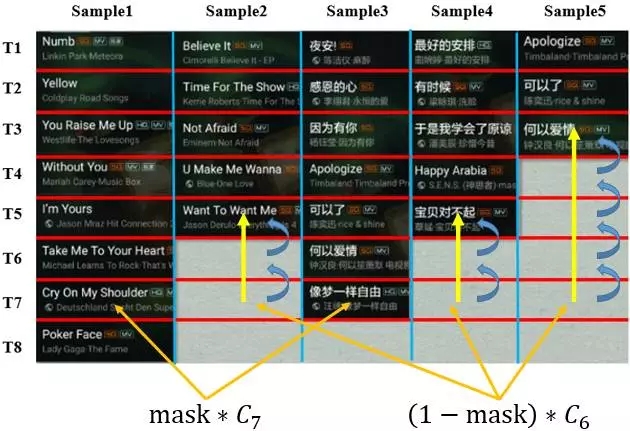
下面通过一个具体例子来形象的描述这个过程,下图是从腾讯QQ音乐抽取的部分听歌训练样本,为了便于理解,这里只选择batch_size的大小为5,最长的点击序列是8。

由训练数据,我们得到对应的掩码(mask)为:

掩码的设计为我们解决了不同用户听歌序列不相同的问题,让多个用户的听歌数据同时进行矩阵运算,但却产生了另外一个问题,在每一次LSTM层训练的时候,状态迁移输出和隐藏层结点输出计算是全局考虑的,对于当前用0来padding的训练样本,理论上是不应该进行更新,如何解决这一个问题呢?
利用动态规划的思想可以优雅的解决这个问题,当我们计算出当前阶段的cell state和隐藏层结点输出后,把当前的状态输出与前一个状态输出作线性的组合,具体来说,假如当前正在更新第T次点击状态。
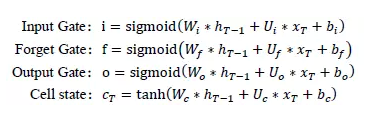
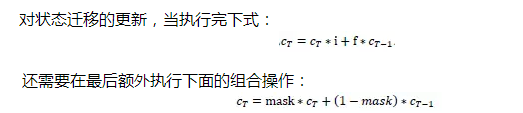
右式由两部分构成,加号左边,如果mask的值为1,更新当前状态,加号右边,如果mask为0,那么状态退回到最后一个非0态。如下图所示:当运行到T7时,对于sample1和sample3都是直接更新新数据,对于sample2,sample4和sample5则执行回溯。
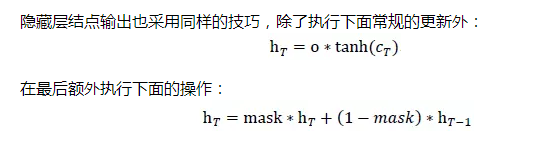
4、Dropout-深度学习正则化的利器
正则化是机器学习中常用来解决过拟合的技巧,在深度学习领域,神经网络的参数更多,更深,结构也更复杂,而往往训练样本相对较少,过拟合的问题会更加严重。较为常见的正则化方法包括:对单模型,比如当验证集的效果变化不明显的时候我们可以提前终止迭代,或者采用L1正则化和L2正则化等;对多模型,我们可以利用boosting来集成提升,但在深度学习中,这种方法是不现实的,因为单个模型的训练已经非常复杂耗时,并且即使训练出多个网路模型,也难以在实际环境中做到快速集成。
Dropout结合了单模型和多模型的优点,是深度学习领域解决过拟合的强有力武器,前面提到,如果不考虑时间复杂度的前提下,可以通过训练多个不同的网络模型来集成提升效果,网路结构之间差别越大,提升效果也会越明显,可以假设一个神经网络中有n个不同神经元,那么相当于有2n个不同的网络结构,如下图所示:

Dropout的思想是每一迭代的过程中,我们会随机让网络某些节点 (神经元) 不参与训练,同时把与这些暂时丢弃的神经元(如下图的黑色结点)相关的所有边全部去掉,相应的权重不会在这一次的迭代中更新,每一次迭代训练我们都重复这个操作。需要注意的是这些被丢弃的的神经元只是暂时不做更新,下一次还是会重新参与随机化的dropout。

Hinton给出了dropout随机化选择的概率,对于隐藏层,一般取P=0.5,在大部分网络模型中,能达到或接近最优的效果,而对于输入层,被选中的概率要比被丢弃的概率要大,一般被选中的概率大约在P=0.8左右。在具体实现的时候,我并没有对输入层做dropout,在隐藏层取概率为0.5来进行正则化。
从理论角度来说,这个做法的巧妙之处在于,每一次的训练,网络都会丢弃部分的神经元,也就是相当于我们每一次迭代都在训练不同的网络结构,这样同一个模型多次dropout迭代训练便达到了多模型融合的效果。
Hinton在其论文中还对dropout给出了一种很有意思的生物学的解析,也就是为什么有性繁殖会比无性繁殖更能适应环境的变化,无性繁殖从母体中直接产生下一代,能保持母体的优良特性,不容易发生变异,但也因此造成了适应新环境能力差的缺点,而为了避免环境改变时物种可能面临的灭亡(相当于过拟合),有性繁殖除了会分别吸收父体和母体的基因之外,还会为了适应新环境而进行一定的基因变异。
5、Hierarchical softmax输出
最后的一个难点问题是推荐结果的输出。对于常规的输出层,一般是采用softmax函数建模,当输出数据很少,比如只有几千个候选数据,那么softmax的计算是很方便简单的,但对于上百万甚至上千万的推荐数据,这种方法就会成为训练效率的一个瓶颈。有什么好的方法可以解决这个问题呢?Hierarchical softmax是深度学习中解决高维度输出的一个技巧,在NLP领域,经典的word2vec就采用Hierarchical softmax来对输出层进行建模,我们也借助同样的思想,把Hierarchical softmax应用于推荐数据的输出选择。
首先来简要的回顾Hierarchical softmax的原理,如果输出层是常规的softmax输出,假设有V个候选输出数据,那么,每一时刻的输出都需要计算P(vi|ht),时间复杂度为O(V), Hierarchical softmax的思想是构建一颗哈夫曼树,我在应用中使用歌曲的热度作为初始权值来构建哈夫曼树,哈夫曼树构建完成后,可以得到每一首歌曲对应的哈夫曼编码。从而把softmax输出层转化为Hierarchical softmax,即多层次输出,如下图所示:
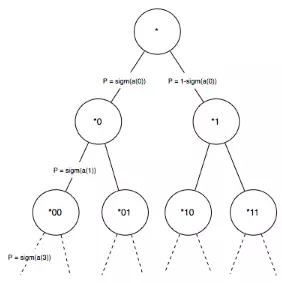
对于任意的输出数据,哈夫曼树都必然存在一条从根节点到叶子结点(歌曲)的路径,并且该路径是的,从根结点到叶子结点会产生L-1个分支,每一个分支都可以看成是一个二元分类,每一个分类会产生一个概率,将这些概率相乘就是我们最后的预测值。
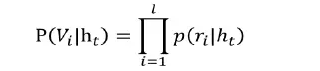
通过层次softmax求取概率,时间复杂度从原来的O(V)下降为O(log(V))。
关于推荐输出,除了显式求解每一首歌的输出概率之外,我还尝试了采用流派来进行层次softmax建模,事实上,在线上环境中,很多时候不需要较精确到具体的歌曲,在输出层,我们可以按流派层次来建模,第一层是一级流派标签,选择了一级标签之后,进入二级标签的选择,三级标签的选择等等,一般来说标签的数量相对歌曲总量来说要少很多,但这种方法也要求标签和曲库的体系建设做到比较完善。
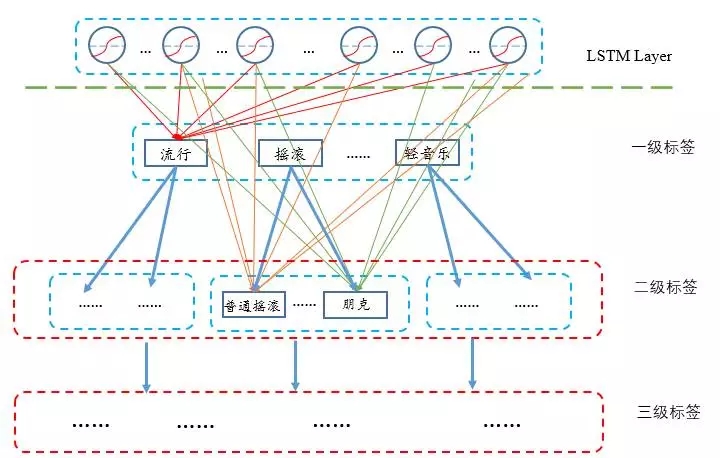
6、测试效果
模型训练目标是最小化下式的损失函数,目标函数由两部分构成,分别对应于正向数据集和负向数据集。
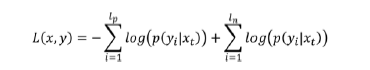
在测试中,我们收集了QQ音乐最近的电台听歌记录,共约8千万条听歌序列,并对数据做了必要的预处理操作,主要包括下面两点:
去掉了点击序列小于5首,大于50首的听歌数据,去掉序列过少是为了防止误点击,去掉过长的听歌序列是为了防止用户忘记关掉播放器。
对于全部是5秒内跳过的听歌序列也同样去掉,这样可以有效防止不正当的负操作过多对模型训练产生的影响。
代码采用Theano深度学习框架来实现,Theano也是当前对RNN支持较好的深度学习框架之一,它的scan机制使得RNN (包括LSTM, GRU) 的实现代码非常优雅。下图是核心递归代码生成的图结构:
我们分别采用单层LSTM和两层LSTM来训练,通过测试对比,两层的LSTM效果要比单层的提高5%,同时我们也采用dropout来防止过拟合,dropout的效果还是比较明显,在lr和momentum相同的情况下,取p=0.5, 效果进一步提升了3%。
除了前面提到的一些技巧外,还有很多细节能帮助我们提高网络的训练速度,下面是我用到的其中一些技巧:
【1】Theano的cuda backend当前只支持float32,需要将floatX设置为float32,并且将全部的shared变量设置为float32。
【2】权重参数尽量放在non_sequences中,作为参数传递给递归函数,这样防止每一次迭代的时候都需要把参数反复重新导入计算图中。
【3】为了避免数据在显存和内存之间频繁的交互,我大量采用了sandbox.gpu_from_host来存储结果数据,但也对可移植性造成一定的影响。
【4】最后,theano的调试是不方便的,灵活使用eval和compute_test_value来调试theano。
对于新数据的预测,如下图所示,给出初始的歌曲X0, 模型就能连续生成输出序列,但有一点需要注意的是,与数据训练不同,新数据的生成过程中,当前阶段的输出数据也是下一阶段的输入数据。

7、小结
本文是深度学习在智能推荐的第二篇实践文章,详细解析了如何使用LSTM对用户的点击进行序列建模,具体包括了如何设计lstm的门逻辑,以更好适应个性化推荐场景,dropout正则化,序列的规整,以及层次softmax解决高维度的推荐结果输出。
随着个性化推荐的不断发展,推荐也早已不局限于浅层的用户和物品挖掘,但对用户行为的挖掘是一个相对困难的问题,我们也将会继续探索深度学习在个性化推荐领域的研究与落地应用。
参考文献:
【1】Erik Bernhardsson. Recurrent Neural Networks for Collaborative Filtering at Spotify.
【2】Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, Domonkos Tikk. Session-based Recommendations with Recurrent Neural Networks.
【3】David Zhan Liu, Gurbir Singh. A Recurrent Neural Network Based Recommendation System.
【4】WILDML. RECURRENT NEURAL NETWORKS TUTORIAL.
【5】Andrej Karpathy. The Unreasonable Effectiveness of Recurrent Neural Networks.
【6】Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov. Dropout: A Simple Way to Prevent Neural Networks from Overfitting.
【7】https://www.quora.com/Has-there-been-any-work-on-using-deep-learning-for-recommendation-engines.
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4416.html
摘要:自从年深秋,他开始在上撰写并公开分享他感兴趣的机器学习论文。本文选取了上篇阅读注释的机器学习论文笔记。希望知名专家注释的深度学习论文能使一些很复杂的概念更易于理解。主要讲述的是奥德赛因为激怒了海神波赛多而招致灾祸。 Hugo Larochelle博士是一名谢布克大学机器学习的教授,社交媒体研究科学家、知名的神经网络研究人员以及深度学习狂热爱好者。自从2015年深秋,他开始在arXiv上撰写并...
摘要:机器学习系统被用来识别图像中的物体将语音转为文本,根据用户兴趣自动匹配新闻消息或产品,挑选相关搜索结果。而深度学习的出现,让这些问题的解决迈出了至关重要的步伐。这就是深度学习的重要优势。 借助深度学习,多处理层组成的计算模型可通过多层抽象来学习数据表征( representations)。这些方法显著推动了语音识别、视觉识别、目标检测以及许多其他领域(比如,药物发现以及基因组学)的技术发展。...
摘要:简称是为和编写的较早的商业级开源分布式深度学习库。这一灵活性使用户可以根据所需,在分布式生产级能够在分布式或的基础上与和协同工作的框架内,整合受限玻尔兹曼机其他自动编码器卷积网络或递归网络。 Deeplearning4j(简称DL4J)是为Java和Scala编写的较早的商业级开源分布式深度学习库。DL4J与Hadoop和Spark集成,为商业环境(而非研究工具目的)所设计。Skymind是...
摘要:本文将详细解析深度神经网络识别图形图像的基本原理。卷积神经网络与图像理解卷积神经网络通常被用来张量形式的输入,例如一张彩色图象对应三个二维矩阵,分别表示在三个颜色通道的像素强度。 本文将详细解析深度神经网络识别图形图像的基本原理。针对卷积神经网络,本文将详细探讨网络 中每一层在图像识别中的原理和作用,例如卷积层(convolutional layer),采样层(pooling layer),...

阅读 3785·2021-11-24 10:46
阅读 1744·2021-11-15 11:38
阅读 3823·2021-11-15 11:37
阅读 3632·2021-10-27 14:19
阅读 2018·2021-09-03 10:36
阅读 2045·2021-08-16 11:02
阅读 3043·2019-08-30 15:55
阅读 2309·2019-08-30 15:44





