
摘要:在嵌入式系统上的深度学习随着人工智能几乎延伸至我们生活的方方面面,主要挑战之一是将这种智能应用到小型低功耗设备上。领先的深度学习框架我们来详细了解下和这两个领先的框架。适用性用于图像分类,但并非针对其他深度学习的应用,例如文本或声音。
在嵌入式系统上的深度学习
随着人工智能 (AI) 几乎延伸至我们生活的方方面面,主要挑战之一是将这种智能应用到小型、低功耗设备上。这需要嵌入式平台,能够处理高性能和极低功率的极深度神经式网络 (NN)。然而,这仍不足够。机器学习开发商需要一个快速和自动化方式,在这些嵌入式平台上转换、优化和执行预先训练好的网络。
在这一系列发布的内容中,我们将回顾当前框架以及它们对嵌入式系统构成的挑战,并演示处理这些挑战的解决方案。这些发布的内容会指导你在几分钟之内完成这个任务,而不是耗时数月进行手动发布和优化。
在发布微信时我们也会更新不同部分的链接。
第一部分:深度学习框架、特征和挑战
第二部分:如何克服嵌入式平台中的深度学习挑战
第三部分:CDNN – 一键生成网络
深度学习框架、特征和挑战
至今,深度学习的主要限制及其在实际生活中的应用一直局限于计算马力、功率限制和算法质量。这些前端所取得的巨大进步使其在许多不同领域取得杰出成就,例如图像分类、演说以及自然语言处理等。
列举图像分类的具体示例,过去五年,我们可看到 ImageNet 数据库显著提升四倍。深度学习技术于 2012 年达到 16% 的五大错误率,现在低于 5%,超出人为表现!如需了解更多有关神经网络和深度学习框架的介绍性信息,您可阅读近期关于这个话题的博客。
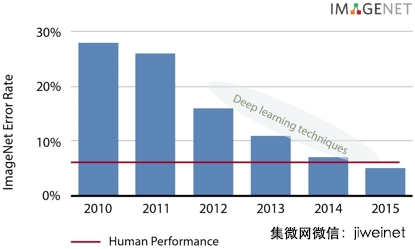
深度学习技术近年来取得显著成效(资料来源:Nervana)
神经网络的挑战
将这些成就转至移动、手持设备显然是这个技术的下一个进化步骤。然而,这样做会面临相当多的挑战。首先,有许多相互竞争的框架。其中有两个领先和最知名的框架分别为 UC Berkeley 开发的 Caffe 以及谷歌近期发布的 TensorFlow。除此之外,还有许多其他框架,例如微软公司的计算网络工具包 (CNTK)、Torch、Chainer 等。
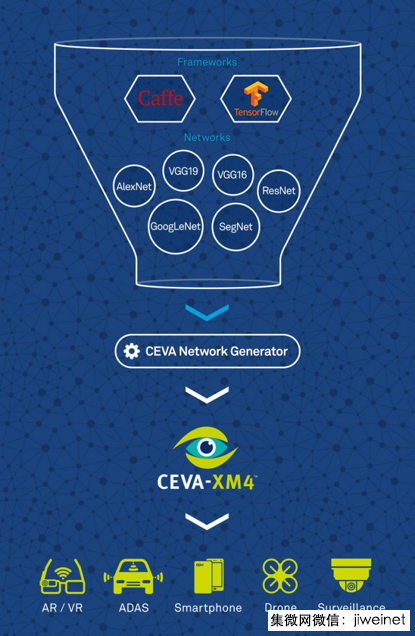
除了众多框架外,神经网络包括各种类型的层面,例如卷积、归一化、池化及其他。进一步障碍是大批网络拓扑。至今,神经网络都遵循一个单拓扑。由于网络内部网络拓扑的出现,目前的情况更为复杂。例如,GoogLeNet 包括9个接收层,创造极为丰富和复杂的拓扑。
额外并发影响包括支持可变大小的感兴趣区域 (ROI)。虽然以研究为导向的网络(例如 AlexNet)在固定大小的 ROI 上运行,但优化合适的解决方案需要更灵活的商业网络。
领先的深度学习框架
我们来详细了解下Caffe 和 TensorFlow这两个领先的框架。通过比较这两个框架来阐明各自的优势和劣势。
成熟度
Caffe 推出时间较长。自 2014 年夏天推出,它可从一个支持各种图像分类任务的预训练神经网络模型大数据库(即 Model Zoo)中受益匪浅。与之相比,TensorFlow 则在近期于 2015 年 11 月首次推出。
适用性
Caffe 用于图像分类,但并非针对其他深度学习的应用,例如文本或声音。相反的,TensorFlow 除了图像分类外,能够解决一般的应用。
建模能力
循环神经网络 (RNN) 是保留先前状态实现持久性的网络,与人类思维过程类似。从这个层面来看,Caffe 不是非常灵活,因为其原有架构需要定义每个新层面类型的前向、后向和梯度更新。TensorFlow 利用向量运算方法的符号图,指明新网络相当简易。
架构
TensorFlow 拥有一个包含多个前端和执行平台的清理器、模块化结构。
领先的神经网络层
卷积神经网络 (CNN) 是神经网络的特殊例子。CNN 包括一个或多个卷积层,通常带有子采样层,在标准神经网络中后面跟着一个或多个完全连接层。在 CNN 中,用于特征提取的卷积层重量以及用于分类的完全连接层可在训练过程中确定。CNN 中的总层数可能从许多层到大约 24 层不等,例如 AlexNet,而如为 SegNet,则最多为 90 层。
我们根据与客户和合伙人合作期间遇到的多个网络,编辑了许多领先层列表。
卷积
标准化
池化(平均和较大)
完全连接
激活(ReLU、参数 ReLU、TanH、Sigmoid)
去卷积
串联
上采样
Argmax
Softmax
由于 NN 不断发展,这个列表可能也会更改和转换。一个可行的嵌入式解决方案无法承担每次在深度学习算法进步时而变得过时的代价。避免这个情况的关键是具备随之发展进化的灵活性并处理新层。这种类型的灵活性通过 CEVA 在上个 CES大会上 运用所有 24 层运行实时 Alexnet 期间提出的 CEVA-XM4 视觉 DSP 处理器展现。
深度学习拓扑结构
如果我们查看网络,例如 AlexNet 或不同的 VGG 网络,它们具备相同的单拓扑,即线性网络。在这个拓扑中,每个神经元点都有一个单端输入和单端输出。
更复杂的拓扑包括每级多层。在此情况下,可在处于相同级的多个神经元之间分配工作,然后与其他神经元结合。这种网络可以 GoogLeNet 为例。拥有多个输入多个输出拓扑的网络产生更多复杂性。

深度学习拓扑(资料来源:CEVA)
正如我们在上图第 (c) 种情况看到,相同的神经元可同时接收和发送多个输入和输出。这些类型的网络可通过 GoogLeNet、SegNet 和 ResNet 例证。
除了这些拓扑,还有完全卷积网络,这是关于单像素问题的快速、端对端模型。完全卷积网络可接收任意大小的输入,并通过有效推理和学习产生相应大小的输出。这更适合于 ROI 根据对象大小动态变化的商业应用程序。
嵌入式神经网络的挑战
预训练网络之后的下一个巨大挑战是在嵌入式系统中实施,这可是一个极具挑战性的任务!障碍可分为两个部分:
1、宽频限制以及嵌入式系统的计算能力。
NN 需要大量数据,利用 DDR 在各层之间进行传输。如为卷积和完全连接数据重量来自 DDR,数据传输极其庞大。在这些情况下,也要使用浮点精度。在许多情况下,相同网络用于处理多个 ROI。虽然大型、高功耗电机器可执行这些任务,但嵌入式平台制定了严格的限制条件。为实现成本效益、低功率及最小规模,嵌入式解决方案使用少量数据,限制内存大小,通常以整数精度运行,这与浮点截然相反。
2、竭力为嵌入式平台移植和优化 NN。
向嵌入式平台移植预训练 NN 的任务相当耗时,需要有关目标平台的编程知识和经验。在完成初步发布后,还必须为特定平台进行优化,以实现快速和有效性能。
这些挑战如果处理不当,将构成重大威胁。一方面,必须要克服硬件限制条件,以在嵌入式平台上执行 NN。另一方面,必须要克服挑战的第二部分,以便快速达成解决方案,因为上市时间是关键。还原至硬件解决方案以加速上市时间也不是一个明智选择,因为它无法提供灵活性,并将快速成为发展进化神经网络领域中的障碍。
为找出如何快速且毫不费劲地跨越这些障碍,请下次关注第二部分。届时我们将以 GoogLeNet 为例,讨论和演示我们的解决方案。
同时,可点击了解更多有关 CDNN – CEVA 深度神经网络 的信息。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4415.html
摘要:基于深度学习的语义匹配语义匹配技术,在信息检索搜索引擎中有着重要的地位,在结果召回精准排序等环节发挥着重要作用。在美团点评业务中主要起着两方面作用。 写在前面美团点评这两年在深度学习方面进行了一些探索,其中在自然语言处理领域,我们将深度学习技术应用于文本分析、语义匹配、搜索引擎的排序模型等;在计算机视觉领域,我们将其应用于文字识别、目标检测、图像分类、图像质量排序等。下面我们就以语义匹配、图...

阅读 647·2023-04-26 02:58
阅读 2377·2021-09-27 14:01
阅读 3679·2021-09-22 15:57
阅读 1257·2019-08-30 15:56
阅读 1097·2019-08-30 15:53
阅读 854·2019-08-30 15:52
阅读 784·2019-08-26 14:01
阅读 2217·2019-08-26 13:41



