
摘要:正如我们可以看到的那样,降低了人类表现与机器表现之间的差异,在英语和中文上都将差距缩小了以上。对于中文和英语,谷歌当下的系统被认为是世界上较好的,所以用一个模型对二者进行提高是一个很大的成就。
本文介绍的是WaveNet——一个原始音频波形深度模型。我们展示了,Wavenet能够生成模仿人类的语音,听起来要比现有较好的文本到语音转化系统更自然,将与人类表现的差距缩减了50%以上。
在我们的展示中,相同的网络能被用于合成其他的音频信号,比如,音乐。在这里,我们提供了一些样本——自动生成的钢琴曲。
会说话的机器
让人能与机器对话是人机交互长期以来的一个梦想。近年来,随着深度神经网络的应用(比如,谷歌的语音搜索),计算机理解自然语音的能力取得了革命性的进展。但是,用计算机生成语音仍然大量地依赖于所谓的 TTS (文本到语音)拼接技术,在这个过程中,首先要记录一个说话人的声音片段,并基于此构建超大型的数据库,随后,经过再次结合过程,形成完整的表达。这样一来,在不纪录一个完整的新数据库的情况下,要修饰声音就会变得很困难(比如,转化到不同的说话者,或者转化语音中的情感和语气)。
这导致了对参数的 TTS 的大量需求,在这里面,所有生成数据所需要的信息都被存储到模型的参数中,并且,语音中的内容和个性可以通过模型的输入进行控制。但是,目前为止,参数的TTS听起来更多的是不自然的,而是合成的,至少对于音节语音,比如英语来说是这样。现有的参数模型一般是信号处理算法Vocoders得到输出,生成语音信号。
通过直接对原始声音信号的声浪建模,WaveNet改变了这种旧范式,每次对一个样本进行建模。和生成更加自然的语音一样,使用原始的声波意味着WaveNet能对任何音频建模,其中包括音乐。


研究者一般都会避免对原始音频进行建模,因为音频跳转得太快了:一般情况下,每秒转变的样本达到16000个或更多,在许多时间点上,都需要设置重要的结构。建立一个完全自动回归的模型显然是一个充满挑战的任务,在这个模型中,对每一个样本的预测都会受到此前样本的影响(在statistics-speak中,每一个预测的分布都受到此前观察的限制)。
但是,我们在今年早些时候发布的PixelRNN 和 PixelCNN 模型,证明使用不止一个像素一次性生成复杂的自然图像是可能的,但是一次生成 一个颜色通道,每张图像都要求成千上万个预测。这给了我们灵感,进而把二维的PixelNet 运用到 一维的WaveNet中。

上面的动画展示了WaveNet的组织结构。这是一个全卷积的神经网络,当中的卷积层有多个扩张因素,允许它的接收域在深度上呈指数级的增长,覆盖数千个时间步长。
在训练时,输入序列是从人类说话者记录的真实声音波形。训练结束后,我们可以把网络作为样本,产生合成的表达。在取样的每一个步骤中,值是由网络计算的概率分布绘制。然后该值被反馈到输入,用于下一个步骤的预测得以制成。这样按部就班地建立样品计算成本高昂,但我们发现,在生成复杂的、逼真的音频上,这是至关重要的。
对现状的提升
我们使用谷歌的TTS数据库来训练WaveNet,这样我们就能评估它的表现,下面的表格展示了从1到5的量级上,WaveNet 的质量与谷歌现在较好的TTS系统(参数的和合成的)的对比,还有一个对比是与人类使用MOS。
MOS是一个用于衡量主观声音质量测试的标准,以人类为对象的盲测中获得(对100个测试句子的500个评级)。正如我们可以看到的那样,WaveNets降低了人类表现与机器表现之间的差异,在英语和中文上都将差距缩小了50%以上。
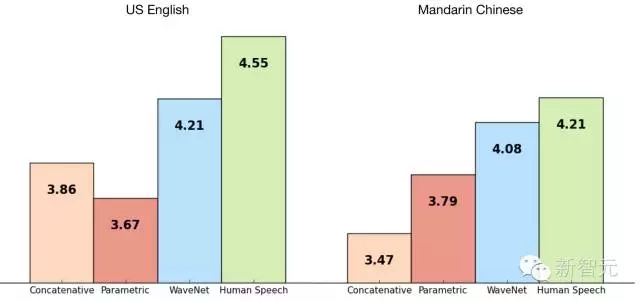
对于中文和英语,谷歌当下的TTS系统被认为是世界上较好的,所以用一个模型对二者进行提高是一个很大的成就。
以下wavenet 在中文上的表现:
知道说的是什么
为了使用WaveNet 把文本转变成语音,我们必须告诉它文本是什么。我们通过把文本转化成一个语言与声学特征序列(这个序列包含了当下的声音、字母、词汇等),以及,把这一序列喂到WaveNet中,我们可以做到让模型了解要说什么。这意味着,网络的预测不仅取决于前期的声音样本,也取决于我们希望它说的内容。
如果我们在没有文本序列的情况下训练这一网络,它仍然能生成语音,但是这样的话它需要辨别要说的是什么。正如你可以在下面的例子中听到的那样,结果有点像在说胡话,其中真实的单词被类似发音的声音打乱。
WaveNets在有些时间还可以生成例如呼吸和嘴部运动这样的非语言声音,这也反映了一个原始的音频模型所拥有的更大的自由度。
如你在这些样本中所能听到的一样,一个单一的WaveNet可以学习很多种声音的特点,不论是男性还是女性。为了确认WaveNet知道在任意的情景下它知道用什么声音,我们去控制演讲人的身份。有意思的是,我们发布用很多的演讲者是训练这个系统,使得它能够更好的去给单个演讲者建模。这比只用一个演讲者去训练要强。这是一种形式的迁移学习。
同样的,我们也可以在模型的输入端给予更多的东西,例如情感或噪音,这样使得生成的语音可以更多样化,也更有趣。
生成音乐
既然WaveNets可以用来能任意的音频信息进行建模,我们就想如果能让他来生成音乐的话,这样就更有意思了。和TTS实验不同,我们没有给网络一个输入序列,告诉它要去播放什么(例如一个谱子)。相反的,我们只是让它去生成任意它想生成的东西。当我们将它在一个古典钢琴音乐的数据集上进行训练时,它听上去的效果确定还不错。
WaveNets为TTS、音乐合成以及音频建模开启了更多的可能性。我们已经迫不及待地想要去探索更多WaveNets能做的事。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4402.html
摘要:文本谷歌神经机器翻译去年,谷歌宣布上线的新模型,并详细介绍了所使用的网络架构循环神经网络。目前唇读的准确度已经超过了人类。在该技术的发展过程中,谷歌还给出了新的,它包含了大量的复杂案例。谷歌收集该数据集的目的是教神经网络画画。 1. 文本1.1 谷歌神经机器翻译去年,谷歌宣布上线 Google Translate 的新模型,并详细介绍了所使用的网络架构——循环神经网络(RNN)。关键结果:与...
摘要:深度学习现在被视为能够超越那些更加直接的机器学习的关键一步。的加入只是谷歌那一季一系列重大聘任之一。当下谷歌醉心于深度学习,显然是认为这将引发下一代搜索的重大突破。移动计算的出现已经迫使谷歌改变搜索引擎的本质特征。 Geoffrey Hiton说:我需要了解一下你的背景,你有理科学位吗?Hiton站在位于加利福尼亚山景城谷歌园区办公室的一块白板前,2013年他以杰出研究者身份加入这家公司。H...

阅读 3798·2021-11-24 09:39
阅读 1936·2021-11-16 11:45
阅读 655·2021-11-16 11:45
阅读 1111·2021-10-11 10:58
阅读 2536·2021-09-09 11:51
阅读 1985·2019-08-30 15:54
阅读 747·2019-08-29 13:13
阅读 3507·2019-08-26 12:18




