
摘要:网络所有的神经元都与另外的神经元相连每个节点功能都一样。训练的方法是将每个神经元的值设定为理想的模式,然后计算权重。输入神经元在网络整体更新后会成为输入神经元。的训练和运行过程与十分相似将输入神经元设定为固定值,然后任网络自己变化。
新的神经网络架构随时随地都在出现,要时刻保持还有点难度。要把所有这些缩略语指代的网络(DCIGN,IiLSTM,DCGAN,知道吗?)都弄清,一开始估计还无从下手。
因此,我决定弄一个“作弊表”。这些图里面话的大多数都是神经网络,可也有一些是完全不同的物种。尽管所有这些架构都是新奇独特的,但当我开始把它们画下来的时候,每种架构的底层关系逐渐清晰。
一个问题是要把它们画成节点图:实际上这并没有展示出它们是如何被使用的。比如说,VAE 看起来跟 AE 差不都,但这两种网络的训练过程其实大不一样。训练好的网络的使用方法就更不同了,因为 VAE 是生成器,在新样本中插入噪音的,而 AE 则仅仅是将它们得到的输入映射到它们“记忆”中最近的训练样本!需要说明的是,这个图谱并没有清晰呈现不同节点内在工作原理(那个留做后话)。
要编一份完全的名单尤其困难,因为新的架构随时都在出现。即使是发表过的架构,有意识地去把它们都找全也有很大麻烦,要不就是有时候会落下一些。因此,虽说这幅图会为你提供一些见解,但可千万别认为这幅图里的内容就是全部了。
图中所描绘的每种架构,我都配上了非常非常简短的说明,希望有用。

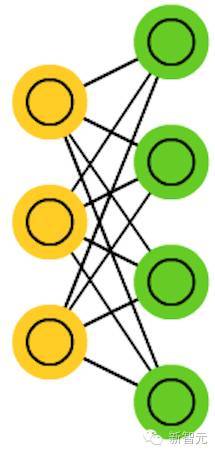
1. 前向传播网络(FF 或 FFNN)
非常直接,它们从前往后传输信息(分别是输入和输出)。神经网络通常都有很多层,包括输入层、隐藏层、输出层。多带带一层不会有连接,一般相邻的两层是全部相连的(每一层的每个神经元都与另一层的每个神经元相连)。最简单,从某种意义上说也是实用的网络结构,有两个输入单元,一个输出单元,可以用来为逻辑关口建模。FFNN 通常用反向传播算法训练,因为网络会将“进来的”和“我们希望出来的”两个数据集配对。这也被称为监督学习,相对的是无监督学习,在无监督学习的情况下,我们只负责输入,由网络自己负责输出。由反向传播算法得出的误差通常是在输入和输出之间差别的变化(比如 MSE 或线性差)。由于网络有足够多的隐藏层,从理论上说对输入和输出建模总是可能的。实际上,它们的使用范围非常有限,但正向传播网络与其他网络结合在一起会形成十分强大的网络。
2. 径向基函数(RBF)网络
是以径向基函数作为激活函数的 FFNN。RBF 就是这样简单。但是,这并不说它们没有用,只是用其他函数作为激活函数的 FFNN 一般没有自己多带带的名字。要有自己的名字,得遇上好时机才行。
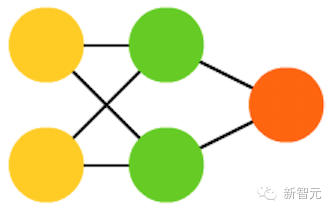
3. Hopfied 网络(HN)
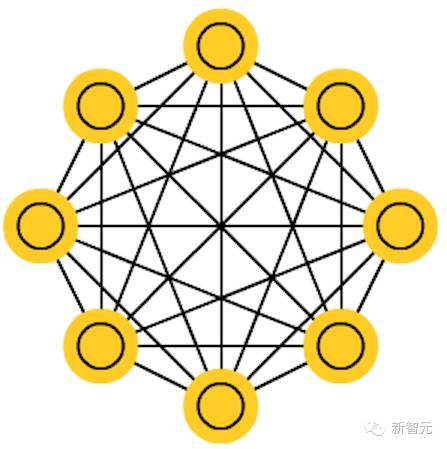
所有的神经元都与另外的神经元相连;每个节点功能都一样。在训练前,每个节点都是输入;在训练时,每个节点都隐藏;在训练后,每个节点都是输出。训练 HN 的方法是将每个神经元的值设定为理想的模式,然后计算权重。这之后权重不会发生改变。一旦接收了训练,网络总会变成之前被训练成的模式,因为整个网络只有在这些状态下才能达到稳定。需要注意的是,HN 不会总是与理想的状态保持一致。网络稳定的部分原因在于总的“能量”或“温度”在训练过程中逐渐缩小。每个神经元都有一个被激活的阈值,随温度发生变化,一旦超过输入的总合,就会导致神经元变成两个状态中的一个(通常是 -1 或 1,有时候是 0 或 1)。更新网络可以同步进行,也可以依次轮流进行,后者更为常见。当轮流更新网络时,一个公平的随机序列会被生成,每个单元会按照规定的次序进行更新。因此,当每个单元都经过更新而且不再发生变化时,你就能判断出网络是稳定的(不再收敛)。这些网络也被称为联存储器,因为它们会收敛到与输入最相似的状态;当人类看到半张桌子的时候,我们会想象出桌子的另一半,如果输入一半噪音、一半桌子,HN 将收敛成一张桌子。
4. 马尔科夫链(MC 或离散时间马尔科夫链,DTMC)

是 BM 和 HN 的前身。可以这样理解 DTMC:从我现在这个节点出发,达到相邻节点的几率有多大?它们是没有记忆的,也即你的每一个状态都完全取决于之前的状态。虽然 DTMC 不是一个真正的神经网络,他们却有与神经网络相似的性质,也构成了 BM 和 HN 的理论基础。
5. 玻尔兹曼机(BM)

和 HN 十分相似,但有些神经元被标记为输入神经元,其他的神经元继续保持“隐藏”。输入神经元在网络整体更新后会成为输入神经元。一开始权重是随机的,通过反向传播算法,或者通过最近出现的对比散度(用马尔科夫链决定两个获得信息之间的梯度)。相较于 HN,BM 的神经元有时候会呈现二元激活模式,但另一些时候则是随机的。BM 的训练和运行过程与 HN 十分相似:将输入神经元设定为固定值,然后任网络自己变化。反复在输入神经元和隐藏神经元之间来回走动,最终网络会在温度恰当时达到平衡。
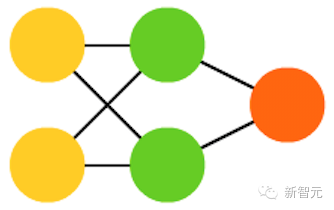
6. 受限玻尔兹曼机(RBM)
与 BM 十分相似(意外吧),因此也与 HN 十分相似。BM 与 RBM 较大的不同在于 RBM 因为受限所以实用性更大。RBM 的输入神经元不与其他输入神经元直接相连,隐藏神经元之间也不存在直接的连接。RBM 可以像 FFNN 一样训练:不采用将信息往前传输然后反向传播的方法,你将信息往前传,然后将输出作为输入(回到第一层)。这之后就可以用双向传播算法训练网络了。
7. 自编码器(AE)
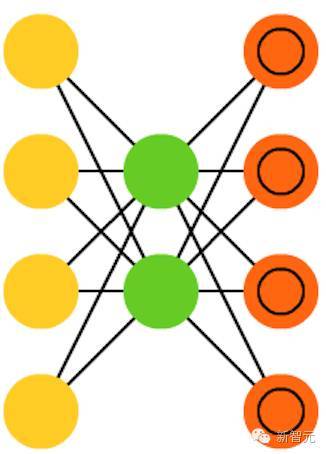
跟 FFNN 有些类似,它只是 FFNN 的一种不同的用法,称不上是从本质上与 FFNN 不同的另一种网络。AE 的外观看起来像沙漏,输入和输出比隐藏层大。AE 也沿中间层两边对称。最小的层总是在中间,这里也是信息压缩得最密集的地方。从开始到中间被称为编码部分,中间到最后被称为解码部分,中间(意外吧)被称为代码。你可以使用反向传播算法训练 AE。AE 两边是对称的,因此编码权重和解码权重也是相等的。
8. 稀疏自编码器(SAE)
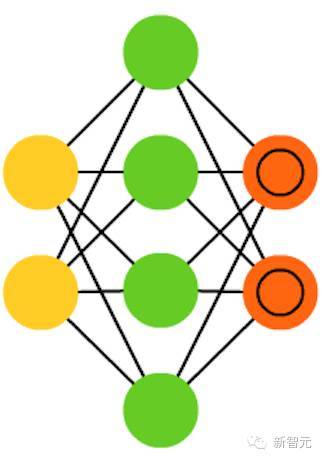
在某种程度上与 AE 相反。我们没有让网络在更少的“空间”或节点上表征一堆信息,而是将信息编码在更多的空间中。因此,网络不是在中间收敛,而是在中间膨胀。这种类型的网络可以被用来从一个数据集中提取很多小的特征。如果你使用训练 AE 的方法训练 SAE,最终你将会无一例外得到一个没有用的、跟输入一模一样的网络。因此,在反馈输入时要增加一个稀疏驱动器(sparsity driver),这样只有一定的误差才会被输送回去得到训练,其他的误差都“无关”,重新归零。在某种意义上,这就像脉冲神经网络一样,不是所有的神经元都在同一时间发射。
9. 变分自编码器(VAE)
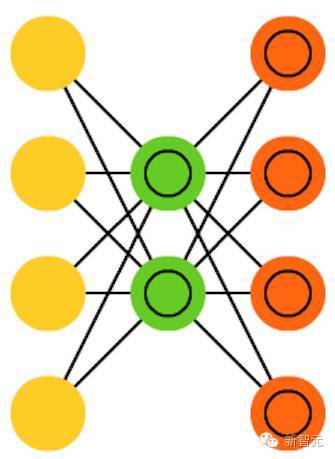
和 AE 拥有同样的架构,但“被教授”的东西却不同:输入样本的近似概率分布。这有点回到本源的感觉,因为它们和 BM 及 RBM 的联系更紧密一点。但它们确实依赖于贝叶斯数学来处理概率推理和独立(probabilistic inference and independence),以及依靠重新参数化(re-parametrisation)来实现这种不同的表征。这种推理和独立部件理解起来很直观,但它们或多或少依赖于复杂的数学。其基础可以归结为:将影响考虑在内。如果某种事物在一个位置发生,而其它地方则发生其它事物,那么它们不一定是相关的。如果它们不相关,那么误差传播应该考虑一下这一点。这是一种有用的方法,因为神经网络是大型的图(graph,从某种角度来看),所以在深入到更深的层时如果排除掉一些节点对其它节点的影响,就会带来帮助。
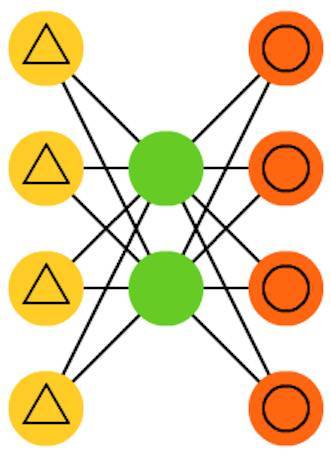
10. 去噪自编码器(DAE)
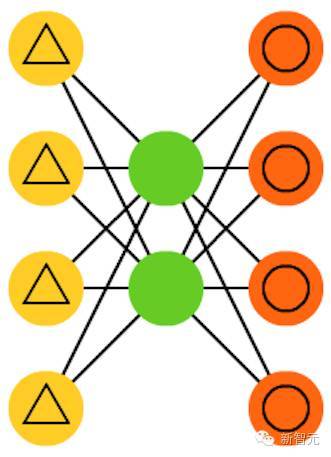
是一种输入中不仅包含数据,也包含噪声(比如使图像更有颗粒感)的自动编码器。但我们以同样的方式计算误差,所以该网络的输出是与不带噪声的原始输入进行比较。这能让网络不会学习细节,而是学习更广泛的特征,因为学习更小的特征往往会被证明是「错误的」,因为更小的特征会不断随噪声变化。
11. 深度信念网络(DBN)
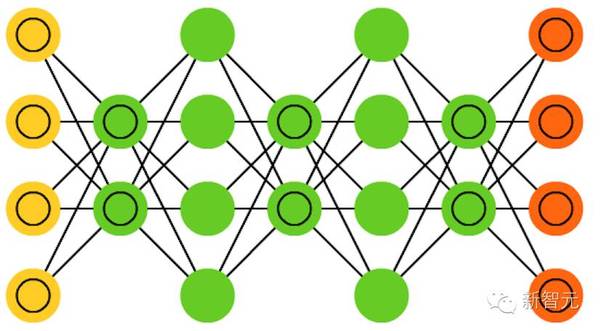
基本上是 RBM 或 VAE 堆叠起来的架构。事实已经证明这些网络可以堆叠起来高效地训练,其中的每一个 AE 或 REM 只必须编码编码之前的网络即可。这种技术也被称为贪婪训练(greedy training),其中贪婪是指得到局部最优的解决方案,从而得到一个合理的但可能并非最优的答案。DBN 可通过对比发散(contrastive divergence)或反向传播进行训练,以及学习将数据表征为概率模型,就像普通的 RBM 或 VAE 一样。一旦通过无监督学习训练或收敛成了一个(更)稳定的状态,该模型就可被用于生成新数据。如果采用对比发散进行训练,它甚至可以对已有的数据进行分类,因为其神经元已经学会了寻找不同的特征。
12. 卷积神经网络(CNN)或深度卷积神经网络(DCNN)
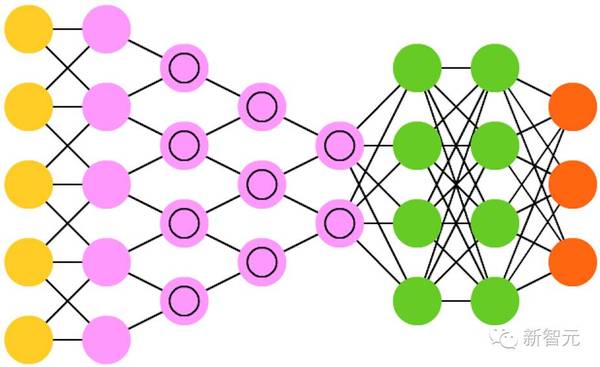
和其它大多数网络非常不同。它们主要被用于图像处理,但也可应用于音频等其它类型的输入。CNN 的一种典型的用例是让网络对输入的图像进行分类,CNN 往往开始带有一个输入“scanner”,其目的是不一次性解析所有的训练数据。CNN 的真实世界实现往往会在末端连接一个 FFNN 以便进一步处理数据,这可以实现高度非线性的抽象。这样的网络被称为 DCNN,但这两者的名字和缩写往往可以混用。
13. 解卷积神经网络(DNN)
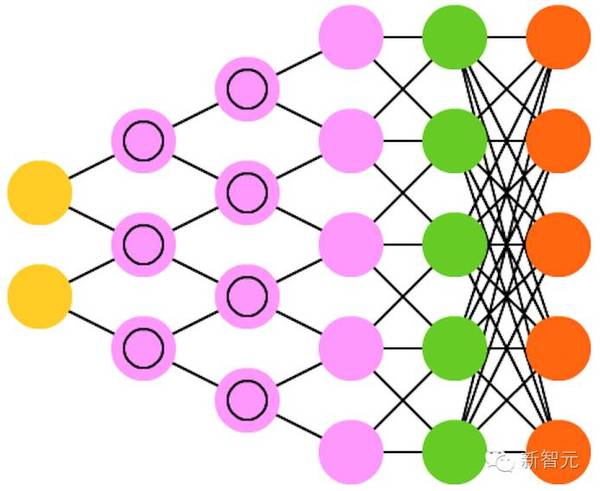
是反向的卷积神经网络。比如给网络输入一个词「cat」,然后训练它生成一张类似猫的图像(通过将其与真实的猫图片进行比较)。和普通的 CNN 一样,DNN 也能和 FFNN 结合使用,但我们就不给这种网络缩写了。我们也许可以将其称之为深度解卷积神经网络,但你也可以认为当你在 DNN 的前端和后端都接上 FFNN 时,你得到的架构应该有一个新名字。请注意在大多数应用中,人们实际上并不会为该网络送入类似文本的输入,而更多的是一个二元的分类输入向量。比如设 <0, 1> 是猫,<1, 0> 是狗,<1, 1> 是猫和狗。CNN 中常见的池化层往往会被相似的逆向运算替代,主要使用偏差假设(biased assumptions)做插值和外推(interpolation and extrapolation )(如果一个池化层使用的是较大池化,你可以通过其逆向过程产生特定度更低的新数据)。
14. 深度卷积反向图形网络(DCIGN)
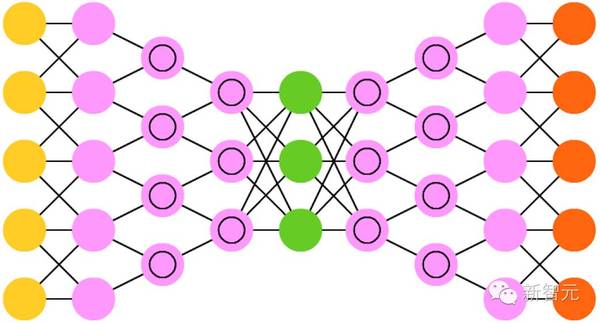
从某种程度上说,这个神经网络的名字有一点欺骗性,它们实际上是VAE,但是在编码和解码中分别有CNN 和 DNN。这些网络尝试在编码的过程中对“特征”作为概率建模,这样一来,它只需要分别“看”猫和狗的独照,就能学会生成一张既有猫又有狗的合照。类似的,你也可以让它把猫狗合照中的狗去掉,如果你很讨厌那只狗的话。Demo显示,这些模型可以学习为图像中复杂的转换进行建模,比如源文件中3D物体光线的改变。这种网络倾向于使用反向传播进行训练。
15. 生成对抗网络(GAN)
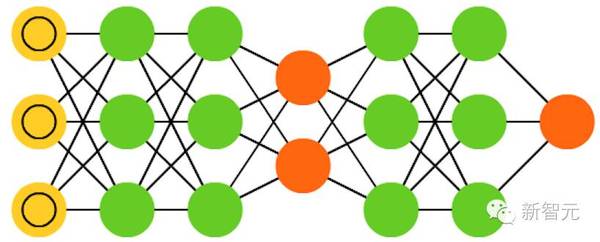
GAN由不同的网络组成,这些网络是成对的:每两个网络配对工作。任何一对网站都可以组成 GAN(虽然通常由FFs 和 CNN 配对),一个网络的任务是生成内容,另一个负责对内容进行评价。进行鉴别的网络从训练数据或者生成式的网络中获得内容。鉴别网络能正确地预测数据源,随后将会被当成误差生成网络中的一部分。这形成了一种对抗:鉴别器在对生成数据和真实数据进行区分时做得越来越好,生成器也在学习如何不被鉴别器预测到。这种网络能取得良好的效果,部分原因是,即便非常复杂的嘈杂模型最终也都是可预测的,但是它只生成与特征类似的内容,所以很难学会鉴别。GAN 很难训练,因为你不仅需要训练两个网络(况且其中的每一个都有自己的问题),而且二者的动态也需要被平衡。
16.循环神经网络(RNN)
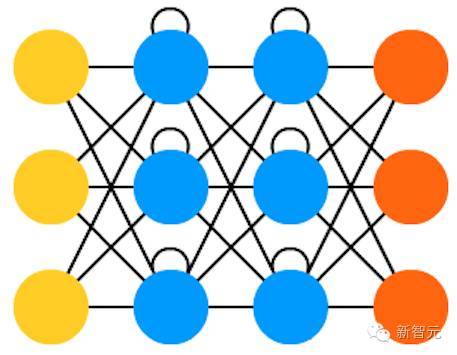
RNN 是一种包含时间纠缠的 FFNN: 他们不是无主的stateless;他们在通道间是有联系的,通过时间进行连接。神经元不仅从上一层神经网络获得信息,而且可以从自身、从上一个通道中获得信息。也就是说,输入和训练网络的顺序会变得很重要。RNN 有一个很大的问题是梯度消失或爆炸,这取决于所使用的激活函数,在这一过程中,信息会不断地迅速消失,正如极深的FFNN 网络在的信息丢失一样。直观地说,这并不是一个大问题,因为他们只是权重而不是神经元状态,但是,经过多次加权后,权重已经成为了旧信息的存储地,如果权重达到0或者100万,那么此前的状态就没有什么信息意义了。RNN 可以在许多领域得到应用,因为绝大多数形式的数据并不真的拥有可以用序列表示的时间线(比如,声音或者视频)。总的来说,循环网络对于完整的信息来说是一个很好的选择。
17.长/短时记忆网络 (LSTM)
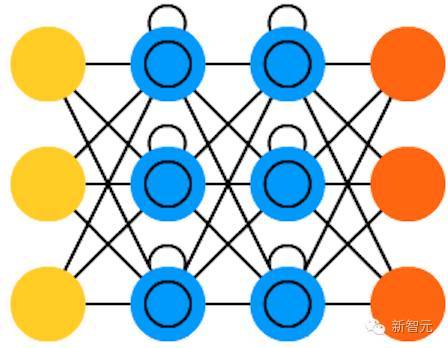
LSTM 通过引入关口(gate)和一个较精确定义的记忆单元,尝试解决梯度消失或者爆炸的问题。这一概念大部分是从电路学获得的启发,而不是从生物学。每一个神经元都有一个存储单元和三个关口:输入、输出和忽略(forget)。这些关口的功能是通过运行或者禁止流动来保证信息的安全。输入关口决定有多少上一层的信息可以存储到单元中。输出层承担了另一端的工作,决定下一层可以了解到多少这一层的信息。忽略关口初看是一个很奇怪的设计,但是,有时候忽略也是很重要的:如果网络正在学习一本书,并开始新的一章,那么忘掉前几章的一些内容也是很有必要的。LSTM已经被证明可以学习复杂的序列,包括像莎士比亚一样写作,或者创作音乐。需要注意的是,这些关口中的每一个都对前一个神经元中的存储单元赋有权重,所以他们一般会需要更多想资源来运行。
18 . 关口循环单元(GRU)
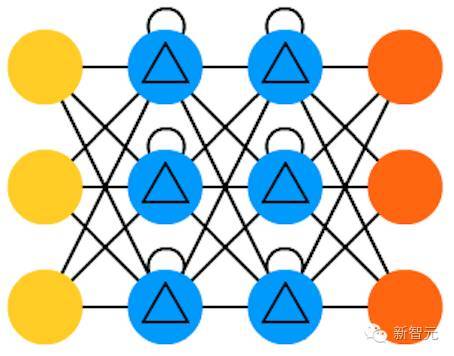
是 LSTM 的一种轻量级变体。它们有一个关口,连线方式也稍微不同:没有输入、输出、遗忘关口,它们有一个更新关口(update gate)。该更新关口既决定来自上个状态的信息保留多少,也决定允许进入多少来自上个层的信息。重置的关口函数很像 LSTM 中遗忘关口函数,但位置稍有不同。GRU 的关口函数总是发出全部状态,它们没有一个输出关口。在大多案例中,它们的职能与 LSTM 很相似。较大的不同就是 GRU 更快、更容易运行(但表达力也更弱)。在实践中,可能彼此之间要做出平衡,当你需要具有更大表达力的大型网络时,你可能要考虑性能收益。在一些案例中,r如果额外的表达力不再需要,GRU 就要比 LSTM 好。
19. 神经图灵机(NTM)
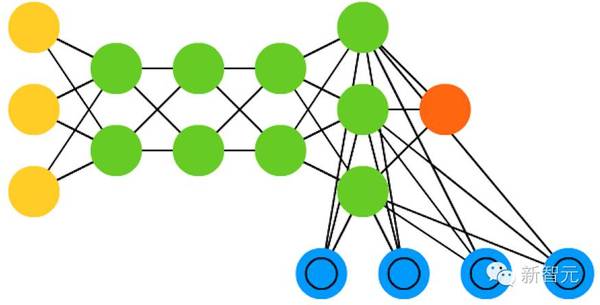
可被理解为 LSTM 的抽象化,并试图将神经网络去黑箱化( un-black-box,让我们洞见里面到底发生了什么。)NTM 中并非直接编码记忆单元到神经元中,里面的记忆是分离的。这种网络试图想将常规数字存储的功效与永久性和神经网络的效率与表达力结合起来。这种网络的思路是有一个可内容寻址的记忆库,神经网络可以直接从中读取并编写。NTM 中的「Turing」来自于图灵完备(Turing complete):基于它所读取的内容读取、编写和改变状态的能力,意味着它能表达一个通用图灵机可表达的一切事情。
20. 双向循环神经网络(BiRNN)、双向长短期记忆网络(BiLSTM)和双向关口控循环单元(BiGRU)

在词表中并未展现,因为它们看起来和各自单向的结构一样。不同的是这些网络不仅连接过去,也连接未来。举个例子,通过一个接一个的输入 fish 这个词训练单向 LSTM 预测 fish,在这里面循环连接随时间记住最后的值。而一个 BiLSTM 在后向通路(backward pass)的序列中就被输入下一个词,给它通向未来的信息。这训练该网络填补空白而非预报信息,也就是在图像中它并非扩展图像的边界,而是可以填补一张图片中的缺失。
21.深度残差网络(DRN)

是非常深度的 FFNN 网络,有着额外的连接将输入从一层传到后面几层(通常是 2 到 5 层)。DRN 并非是要发现将一些输入(比如一个 5 层网络)映射到输出的解决方案,而是学习将一些输入映射到一些输出 + 输入上。大体上,它在解决方案中增加了一个恒等函数,携带旧的输入作为后面层的新输入。有结果显示,在超过 150 层后,这些网络非常擅长学习模式,这要比常规的 2 到 5 层多得多。然而,有结果证明这些网络本质上只是没有基于具体时间建造的 RNN ,它们总是与没有 关口的 LSTM 相对比。
22. 回声状态网络(ESN)
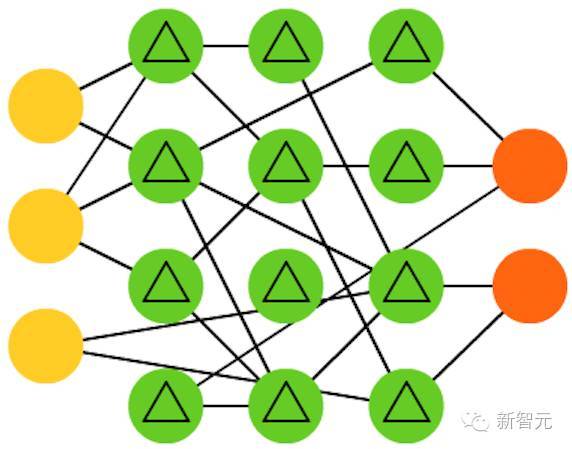
是另一种不同类型的网络。它不同于其他网络的原因在于它在不同神经元之间有随机连接(即,不是在层之间整齐连接。),而且它们训练方式也不同。在这种网络中,我们先给予输入,向前推送并对神经元更新一段时间,然后随时间观察输出,而不是像其他网络那样输入信息然后反向传播误差。ESN 的输入和输出层有一些轻微的卷积,因为输入层被用于准备网络,输出层作为随时间展开的激活模式的观测器。在训练过程中,只有观测器和隐藏单元之间连接会被改变。
23. 液态机(LSM)
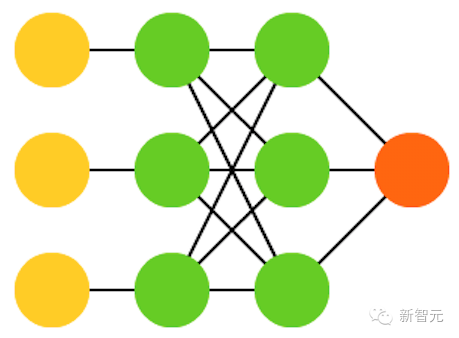
看起来与 ESN 非常类似。不同的是,LSM 是脉冲神经网络(spiking neural networks)这一类型的:用阈值函数取代 sigmoid 激活函数,每个神经元也是一个累加记忆细胞。所以当更新神经元的时候,里面的值并不是被设为临近值的总和,也不是增加到它自身上。一旦达到阈值,它将能量释放到其他神经元。这就创造出了一种类似 spiking 的模式——在突然达到阈值的之前什么也不会发生。
24. 支持向量机(SVM)

能发现分类问题的较佳解决方案。传统上只能够分类线性可分的数据,比如说发现哪个图像是加菲猫,哪张图片是史努比,不可能有其他输出。在训练过程中,SVM 可被视为在一张图上(2D)标绘所有数据(加菲猫和史努比),并搞清楚如何在这些数据点间画条线。这条线将分割数据,以使得加菲猫在一边,史努比在一边。调整这条线到较佳的方式是边缘位于数据点之间,这条线较大化到两端。分类新数据可通过在这张图上标绘一个点来完成,然后就简单看到这个点位于线的哪边。使用核(kernel)方法,它们可被教授进行 n 维数据的分类。这要在 3D 图上标绘数据点,从而让其可分类史努比、加菲猫、Simon’s cat,甚至分类更多的卡通形象。
25.Kohonen 网络(KN)
KN 利用竞争学习在无监督情况下分类数据。向网络输入信息,然后网络评估哪个神经元最匹配该输入信息。进而调整这些神经元以更好地匹配输入,在这个过程中附带着相邻神经元。相邻神经元能移动多少取决于它们与较好的匹配单元之间的距离。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4399.html
摘要:多种学科为神经科学做出贡献。对正常的心智功能如学习和记忆,以及异常功能如抑郁精神分裂和阿尔茨海默病,遗传学鉴定了与之相关的基因。 大脑的未来,在作者的描述之下,真是一个令人兴奋又令人担忧的未来。——蒲慕明我是一个神经科学家,也就是说,我在研究脑如何工作。就像其他许多神经科学家一样,我做这门学问,是因为我相信在分子、细胞和系统层次探索脑如何工作,我们可以对思维如何运作有些理解。对我来说,这是一...
摘要:作为生命科学的神经科学,依然以和蛋白质为基础,横跨分子,细胞,组织,动物行为等各个尺度,描绘神经系统的形态和行为。你埋头在蛋白质的研究中,不代表你对神经网络有任何有效的理解。平衡状态的神经网络具有较大的对外界信号较大的响应能力。 承接上文,计算神经科学是一门超级跨学科的新兴学科,几乎综合信息科学,物理学, 数学,生物学,认知心理学等众多领域的成果。大脑像一台超级计算机,同时它又迥异于计算机,...
摘要:浅层结构化预测方法有损失的条件随机域,有的较大边缘马尔可夫网络和隐支持向量机,有感知损失的结构化感知深层结构化预测图变换网络图变换网络深度学习上的结构化预测该图例展示了结构化感知损失实际上,使用了负对数似然函数损失于年配置在支票阅读器上。 卷积网络和深度学习的动机:端到端的学习一些老方法:步长内核,非共享的本地连接,度量学习,全卷积训练深度学习缺少什么?基础理论推理、结构化预测记忆有效的监督...
摘要:有几次,人工智能死在人工神经网络上。在过去十年中,他一直在举办为期一周的有关神经网络的暑期学校,我曾经拜访过。神经网络压缩信息之后,这些信息无法复原。 魔法已经进入这个世界。如今,许多美国人口袋里装着薄薄的黑色平板,这些机器接入遥远的数字云和卫星,它们解码语言、通过摄像头观察并标记现实,挖掘个人数据,它们以某种方式理解、预测着我们的心愿。倾听、帮助着人类。因为与多伦多大学有个约会,这个夏天,...
摘要:多加了这两层卷积层和汇集层是卷积神经网络和普通旧神经网络的主要区别。卷积神经网络的操作过程那时,卷积的思想被称作权值共享,也在年和关于反向传播的延伸分析中得到了切实讨论。 导读:这是《神经网络和深度学习简史》第二部分,这一部分我们会了解BP算法发展之后一些取得迅猛发展的研究,稍后我们会看到深度学习的关键性基础。神经网络获得视觉随着训练多层神经网络的谜题被揭开,这个话题再一次变得空前热门,罗森...

阅读 3976·2021-11-25 09:43
阅读 2241·2021-11-23 10:11
阅读 1476·2021-09-29 09:35
阅读 1411·2021-09-24 10:31
阅读 2100·2019-08-30 15:48
阅读 2419·2019-08-29 15:28
阅读 490·2019-08-29 12:36
阅读 3549·2019-08-28 18:12






