
摘要:作为当下最热门的话题,等巨头都围绕深度学习重点投资了一系列新兴项目,他们也一直在支持一些开源深度学习框架。八来自一个日本的深度学习创业公司,今年月发布的一个框架。
深度学习(Deep Learning)是机器学习中一种基于对数据进行表征学习的方法,深度学习的好处是用 非 监督式或半监督式 的特征学习、分层特征提取高效算法来替代手工获取特征(feature)。作为当下最热门的话题,Google、Facebook、Microsoft等巨头都围绕深度学习重点投资了一系列新兴项目,他们也一直在支持一些开源深度学习框架。
目前研究人员正在使用的深度学习框架不尽相同,有 TensorFlow、Torch 、Caffe、Theano、Deeplearning4j等,这些深度学习框架被应用于 计算机视觉 、 语音识别、 自然语言处理 与 生物信息学 等领域,并获取了极好的效果。
下面让我们一起来认识目前深度学习中最常使用的八大开源框架:
一.TensorFlow

TensorFlow是一款开源的数学计算软件,使用数据流图(Data Flow Graph)的形式进行计算。图中的节点代表数学运算,而图中的线条表示多维数据数组(tensor)之间的交互。TensorFlow灵活的架构可以部署在一个或多个CPU、GPU的台式以及服务器中,或者使用单一的API应用在移动设备中。TensorFlow最初是由研究人员和Google Brain团队针对机器学习和深度神经网络进行研究所开发的,目前开源之后可以在几乎各种领域适用。
Data Flow Graph: 使用有向图的节点和边共同描述数学计算。graph中的nodes代表数学操作,也可以表示数据输入输出的端点。边表示节点之间的关系,传递操作之间互相使用的多位数组(tensors),tensor在graph中流动——这也就是TensorFlow名字的由来。一旦节点相连的边传来了数据流,节点就被分配到计算设备上异步的(节点间)、并行的(节点内)执行。
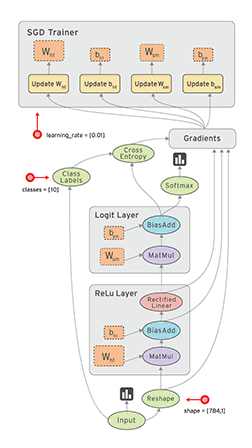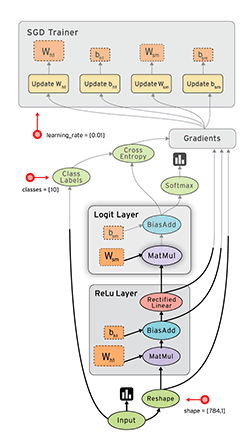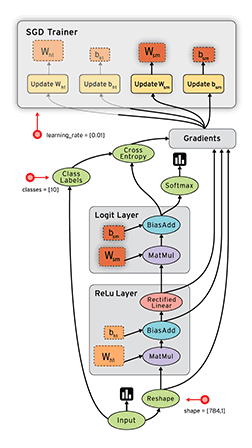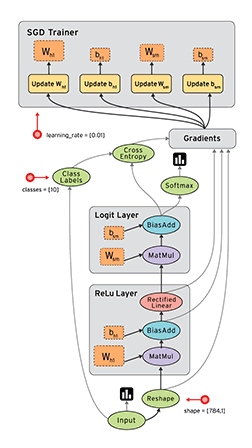
TensorFlow的特点:
机动性: TensorFlow并不只是一个规则的neural network库,事实上如果你可以将你的计算表示成data flow graph的形式,就可以使用TensorFlow。用户构建graph,写内层循环代码驱动计算,TensorFlow可以帮助装配子图。定义新的操作只需要写一个Python函数,如果缺少底层的数据操作,需要写一些C++代码定义操作。
可适性强: 可以应用在不同设备上,cpus,gpu,移动设备,云平台等
自动差分: TensorFlow的自动差分能力对很多基于Graph的机器学习算法有益
多种编程语言可选: TensorFlow很容易使用,有python接口和C++接口。其他语言可以使用SWIG工具使用接口。(SWIG—Simplified Wrapper and Interface Generator, 是一个非常优秀的开源工具,支持将 C/C++ 代码与任何主流脚本语言相集成。)
最优化表现: 充分利用硬件资源,TensorFlow可以将graph的不同计算单元分配到不同设备执行,使用TensorFlow处理副本。
二.Torch

Torch是一个有大量机器学习算法支持的科学计算框架,其诞生已经有十年之久,但是真正起势得益于Facebook开源了大量Torch的深度学习模块和扩展。Torch另外一个特殊之处是采用了编程语言Lua(该语言曾被用来开发视频游戏)。
Torch的优势:
构建模型简单
高度模块化
快速高效的GPU支持
通过LuaJIT接入C
数值优化程序等
可嵌入到iOS、Android和FPGA后端的接口
三.Caffe

Caffe由加州大学伯克利的PHD贾扬清开发,全称Convolutional Architecture for Fast Feature Embedding,是一个清晰而高效的开源深度学习框架,目前由伯克利视觉学中心(Berkeley Vision and Learning Center,BVLC)进行维护。(贾扬清曾就职于MSRA、NEC、Google Brain,他也是TensorFlow的作者之一,目前任职于Facebook FAIR实验室。)
Caffe基本流程:Caffe遵循了神经网络的一个简单假设——所有的计算都是以layer的形式表示的,layer做的事情就是获得一些数据,然后输出一些计算以后的结果。比如说卷积——就是输入一个图像,然后和这一层的参数(filter)做卷积,然后输出卷积的结果。每一个层级 (layer)需要做两个计算:前向forward是从输入计算输出,然后反向backward是从上面给的gradient来计算相对于输入的 gradient,只要这两个函数实现了以后,我们就可以把很多层连接成一个网络,这个网络做的事情就是输入我们的数据(图像或者语音等),然后来计算我们需要的输出(比如说识别的标签),在训练的时候,我们可以根据已有的标签来计算损失和gradient,然后用gradient来更新网络的参数。
Caffe的优势:
上手快:模型与相应优化都是以文本形式而非代码形式给出
速度快:能够运行最棒的模型与海量的数据
模块化:方便扩展到新的任务和设置上
开放性:公开的代码和参考模型用于再现
社区好:可以通过BSD-2参与开发与讨论
四.Theano

2008年诞生于蒙特利尔理工学院,Theano派生出了大量深度学习Python软件包,最著名的包括Blocks和Keras。 Theano的核心是一个数学表达式的编译器,它知道如何获取你的结构。并使之成为一个使用numpy、高效本地库的高效代码,如BLAS和本地代码 (C++)在CPU或GPU上尽可能快地运行。它是为深度学习中处理大型神经网络算法所需的计算而专门设计的,是这类库的首创之一(发展始于2007 年),被认为是深度学习研究和开发的行业标准。
Theano的优势:
集成NumPy-使用numpy.ndarray
使用GPU加速计算-比CPU快140倍(只针对32位float类型)
有效的符号微分-计算一元或多元函数的导数
速度和稳定性优化-比如能计算很小的x的函数log(1+x)的值
动态地生成C代码-更快地进行计算
广泛地单元测试和自我验证-检测和诊断多种错误
灵活性好
五.Deeplearning4j

顾名思义,Deeplearning4j是“for Java”的深度学习框架,也是较早的商用级别的深度学习开源库。Deeplearning4j由创业公司Skymind于2014年6月发布,使用 Deeplearning4j的不乏埃森哲、雪弗兰、博斯咨询和IBM等明星企业。 DeepLearning4j是一个面向生产环境和商业应用的高成熟度深度学习开源库,可与Hadoop和Spark集成,即插即用,方便开发者在APP 中快速集成深度学习功能,可应用于以下深度学习领域:
人脸/图像识别
语音搜索
语音转文字(Speech to text)
垃圾信息过滤(异常侦测)
电商欺诈侦测
除了以上几个比较成熟知名的项目,还有很多有特色的深度学习开源框架也值得关注:
六.ConvNetJS

这是斯坦福大学博士生Andrej KarPathy开发的浏览器插件,基于万能的JavaScript可以在你的游览器中训练深度神经模型。 不需要安装软件,也不需要GPU。
七.MXNet

出自CXXNet、Minerva、Purine 等项目的开发者之手,主要用C++ 编写。MXNet 强调提高内存使用的效率,甚至能在智能手机上运行诸如图像识别等任务。
MXNet的系统架构如下图所示:
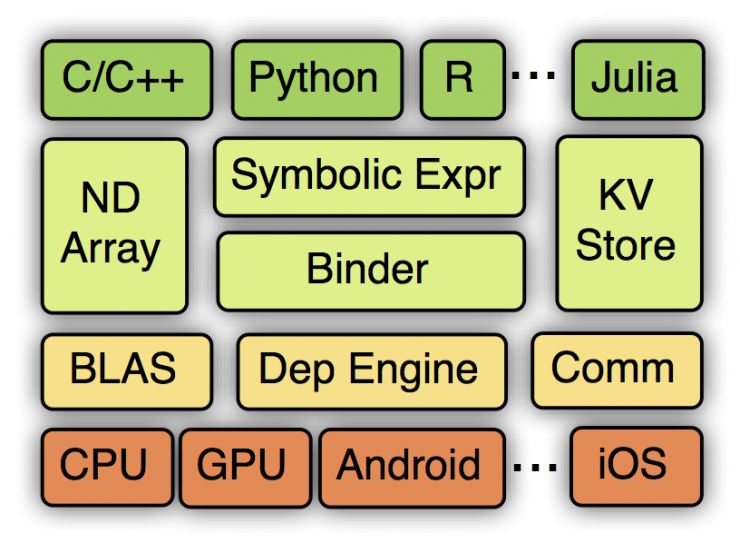
从上到下分别为各种主语言的嵌入,编程接口(矩阵运算,符号表达式,分布式通讯),两种编程模式的统一系统实现,以及各硬件的支持。
八.Chainer

来自一个日本的深度学习创业公司Preferred Networks,今年6月发布的一个Python框架。Chainer 的设计基于 define by run原则,也就是说该网络在运行中动态定义,而不是在启动时定义。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4388.html
摘要:十年铲码,八大体系超千篇数百万字技术笔记系列汇总悦享版十年铲码两茫茫,纵思量,却易忘不觉笔者步入程序员已有十年。十年之期,正巧笔者从阿里离开,重回打印制造业的怀抱,希望能依托于设备优势逐步真正构建分布式制造网络。 showImg(https://segmentfault.com/img/remote/1460000020151971); 十年铲码,八大体系超千篇数百万字技术笔记系列汇总...

阅读 3267·2023-04-26 01:39
阅读 3411·2023-04-25 18:09
阅读 1666·2021-10-08 10:05
阅读 3286·2021-09-22 15:45
阅读 2894·2019-08-30 15:55
阅读 2445·2019-08-30 15:54
阅读 3210·2019-08-30 15:53
阅读 1369·2019-08-29 12:32



