
摘要:神经网络在自然语言处理方面,未来有巨大的应用潜力。讲座学者之一与深度学习大神蒙特利尔大学学者在大会上发表了论文,进一步展现神经机器翻译的研究结果。那些指令的语义就是习得的进入嵌入中,来较大化翻译质量,或者模型的对数似然函数。
在 8月7日在德国柏林召开的2016 计算语言学(ACL)大会上,学者Thang Luong、Kyunghyun Cho 和 Christopher D. Manning进行了关于神经机器翻译(NMT)的讲座。神经机器翻译是一种简单的新架构,可以让机器学会翻译。该方法虽然相对较新,已经显示出了非常好的效果,在各种语言对上都实现了最顶尖的表现。神经网络在自然语言处理方面,未来有巨大的应用潜力。
讲座学者之一 Kyunghyn Cho 与深度学习“大神” Yoshua Bengio、蒙特利尔大学学者 Junyoung Chung 在 ACL 大会上发表了论文,进一步展现神经机器翻译的研究结果。在此,雷锋网(搜索“雷锋网”公众号关注)为大家分享名为《针对神经机器翻译,无需显性分割的字符等级解码器》论文全文。
概况
现有的机器翻译系统,无论是基于词组的还是神经的,几乎全部都依靠使用显性分割的、词语等级的建模。在这篇论文中,我们提出一个基本问题:神经机器翻译能否在生成字符序列时,不使用任何显性分割?要回答这一问题,我们分析一个基于注意的编码器解码器,在四个语言对——En-Cs、En-De、En-Ru 和 En-Fi——中,带有子字等级的编码器,以及一个字符等级的解码器,使用 WMT’ 15 的平行语料库。我们的实验证明,带有字符等级解码器的模型在所有四个语言对上,表现都优于带有子字等级解码器的模型。并且,带有字符等级解码器的神经模型组合在 En-Cs、En-De 和 En-Fi 上优于较先进的非神经机器翻译系统,在 En-Ru 上表现相当。
1、简介
现有的机器翻译系统几乎全部都依靠使用显性分割的、词语等级的建模。这主要是因为数据稀疏性的问题,这当句子表征为一系列字符而非词语时这个问题更为严重,尤其是针对 n-gram,由于序列的长度大大增加了。除了数据稀疏性之外,我们经常先入为主地相信词语——或其分割出的词位——是语义最基本的单位,使我们很自然地认为翻译就是将一系列的源语言词语匹配为一系列的目标语言词语。
在最近提出的神经机器翻译范示中,这种观点也延续了下来,虽然神经网络不受到字符等级建模的拖累,但是会被词语等级建模所特有的问题影响,例如目标语言的词汇量非常大,会造成增加的计算复杂性。因此,这篇论文中,我们研究神经机器翻译是否能够直接在一系列字符上进行,无需显性的词语分割。
为了回答这一问题,我们专注在将目标方表征为一个字符序列。我们用字符等级的解码器在 WMT’ 15 的四个语言对上评估神经机器翻译模型,让我们的评估具有很强的说服力。我们将源语言一方表征为一个子字序列,使用从 Sennrich 等人(2015) 中编码的字节对将其抽取而出,并将目标方改变为一个子字或者字符序列。在目标方,我们进一步设计了一个新的循环神经网络(RNN),称为双度量循环神经网络,能更好地处理序列中的多个时标,并额外在一个新的、堆积的循环神经网络中测试。
在所有四个语言对中——En-Cs、En-De、En- Ru 和 En-Fi——带有字符等级解码器的模型比带有子字等级解码器的模型更好。我们在每一个这些配置的组合中都观察到了类似的趋势,在 En-Cs、En-De 和 En-Fi 中超过了之前较好的神经和非神经翻译系统,而在 En-Ru 上实现了相同的结果。我们发现这些结果强有力地证明了,神经机器翻译真的可以学会在字符等级翻译,并且其实可以从中获益。
2、神经机器翻译
神经机器翻译指的是一个最近提出的机器翻译方法(Forcada 和 Neco, 1997;Kalchbrenner 和 Blunsom, 2013;Cho 等人, 2014;Sutskever 等人, 2014)。这种方法的目标是打造一个端到端的神经网络,将输入作为源句子 X = (x1, … , xTx),并输出其翻译 Y = (y1, … , yTy),其中 xt 和 yt’ 分别是源标志和目标标志。这个神经网络的打造方式是作为一个编码网络和解码网络。
编码网络将输入句子 X 编码为其连续的表征。在这篇论文中,我们紧密遵循 Bahdanau 等人(2015) 提出的神经翻译模型,使用一个双向循环神经网络,其中包含两个循环神经网络。前馈网络将输入句子在前馈方向读作:
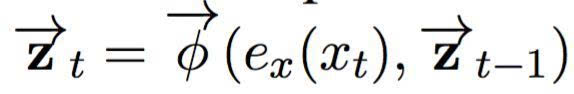
其中 ex (xt) 是对第 t 个输入象征的连续嵌入,是一个循环激活函数。相同地,反向网络将句子以反方向(从右到左)读入:
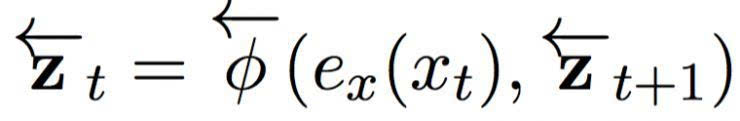
在输入句子的每一个位置,我们将前馈和反向 RNN 中的隐藏状态连接起来,形成一个情景组 C = { z1, …, zTx},其中
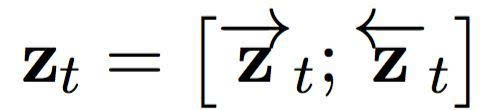
然后,解码器基于这个情景组,计算出所有可能翻译的条件分布。首先,重写一个翻译的条件分布:
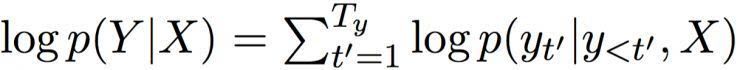
在总和的每一个条件中,解码器 RNN 通过以下方程(1)更新其隐藏状态:
h’t = φ (ey (yt’ - 1), ht’-1, ct’), (1)
其中 ey 是一个目标象征的连续嵌入。ct’ 是一个情景矢量,由以下的软堆砌机制计算而出:
ct’ = falign ( ey (yt’-1), ht’-1, C) )。 (2)
这个软对齐机制 falign 在情景 C 中基于已经翻译的内容,根据相关性权衡每一个矢量。每一个矢量 zt 的权重是由以下的方程(3)计算而出:
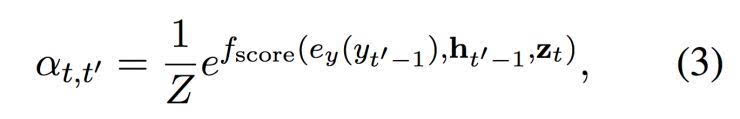
其中 fscore 是一个参数函数,对于 ht’-1 和 yt’-1 返回一个非标准化的得分。
这篇论文中,我们使用一个带有单一隐藏层的前馈网络。 Z 是一个标准化的常数:
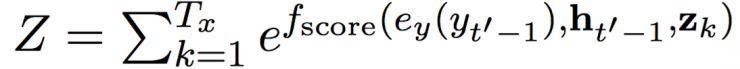
这个过程可以被理解为是在第 t’ 个目标符号和第 t 个源符号之间计算对齐概率。
在隐藏状态 ht’ 与之前的目标符号 yt’-1 和情景矢量 ct’ 一起,输入一个前馈神经网络,带来以下的条件分布:
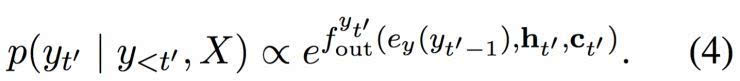
整个模型,由编码器、加码起和软对齐机制构成,然后经过端到端的调试,使用随机梯度下降将负面对数似然函数最小化。
3、向着字符等级翻译
3.1 动机
让我们回顾源句子和目标句子( X 和 Y ) 在神经机器翻译中是如何表征的。对于任何训练体中的源一方,我们可以扫描整体,来打造一个词汇 Vx , 包含分配了整数标记的令牌。然后,源句子 X 作为一系列属于该句子的类似令牌的标记,即 X = (x1, …, xTx) ,其中 xt ∈ { 1, 2, …, | Vx |}。与此类似地,目标句子转化为一个整数标记的目标序列。
然后,每一个令牌或其指数转化为 |Vx|所谓的 one-hot 矢量。除了一个以外,矢量中所有的元素都设置为 0。一个指数对应令牌指数的元素设置为 1。这个 one-hot 矢量就是任何神经机器翻译模型所看见的。嵌入函数 ex 或 ey,就是在这个 one-hot 矢量上应用一个线性转化(嵌入矩阵)的结果。
这种基于 one-hot 矢量的方法的重要特点是,神经网络忽视指令的底层语义。对于神经网络来说,词汇中的每一个指令,等同于与其他每个指令间的距离。那些指令的语义就是习得的(进入嵌入中),来较大化翻译质量,或者模型的对数似然函数。
这项特性让我们在选择指令的单位时获得了很大的自由度。神经网络已经被证实与词语指令配合良好 (Bengio 等人, 2001; Schwenk, 2007; Mikolov 等人, 2010),还与更细微的单元也配合良好,例如子字(Sennrich 等人, 2015; Botha 和 Blunson, 2014; Luong 等人, 2013) 和压缩或编码造成的符号(Chitnis 和 DeNero, 2015)。虽然已经有一系列先前的研究报告称使用了带有字符的神经网络(例如 Mikolov 等人 (2012) 和 Santos 和 Zadrozny (2014)的研究),主流的方法一直是将文字预先处理为一系列符号,每个与一个字符系列相关联,之后神经网络就用那些符号、而非字符来表征。
最近在神经机器翻译中,两组研究团队已经提出过直接使用字符。Kim 等人(2015)提出不像以前一样以单一整数指令来代表每一个词,而是作为一个字符序列,并使用一个卷积网络,随后用一个高速神经网络(Srivastava 等人, 2015)来抽取词语的连续表征。这种方法有效替换了嵌入函数 ex,被 Costa-Jussa 和 Fonollosa(2016)在神经机器翻译中采用。类似地,Ling 等人 (2015b) 使用了一个双向循环神经网络来代替嵌入函数 ex 和 ey,来分别从相应的连续词语表征中编码一个字符序列,并且编码进这个连续表征中去。Lee 等人(2015) 提出了一个类似、但是略有不同的方法,他们用字符在词语中的相对位置来显性地标记每一个字符,例如,英文单词中的 “B”eginning 和 “I”ntermediate。
虽然这些最近的方法是研究字符层面,但还是不如人意,因为它们都依赖于了解如何将字符分割为词语。虽然总体上这在英语等语言中还是相对简单的,这并不总是可行的。这种词语分割过程可以非常简单,就像带有标点符号常规化的指令化,不过,也可能非常复杂,就像词素分割,需要预先训练一个多带带的模型(Creutz 和 Lagus, 2005; Huang 和 Zhao,2007;)。而且,这些分割步骤经常是经过微调的,或者与最终的翻译质量目标分开设计,潜在来说可能造成非最优的质量。
基于这项观察和分析,这篇论文中,我们向自己和读者提出一个早该提出的问题:有没有可能,不使用任何显性的分割,就进行字符等级的翻译?
3.2 为什么要使用词语等级的翻译?
(1)词语作为语义的基本单位
词语可以被理解为两种意思。抽象意义来说,一个词语是语义(词素)的基本单位,在另一种意义来说,可以理解为“在句子中使用的具体词语” (Booij,2012)。在第一种意义中,一个词语通过词语形态学的过程——包括变音、组合和衍生——转化进入第二种意义。这三种过程的确改变词素的含义,但是经常与原意保持相近。因为这种语言学中的观点认为词语是语义的基本单位(作为词素或者衍生形式),自然语言处理中的很多先前研究都将词语作为基本单位,将句子编码为词语的序列。另外,匹配词语的字符序列和语义的潜在困难,也可能推动了这种词语等级建模的潮流。
(2)数据稀疏性
还有另一个技术原因,使得很多之前对于翻译匹配的研究都将词语作为基本单位。这主要是因为现有翻译系统中的主要组成部分——例如语言模型和词组表——都是基于字数的概率模拟。换句话说,标志子序列的概率(或者)一对标志,估计的方法是数出它在训练体出现了几次。这种方法严重地受到数据稀疏性问题的影响,这是因为一个很大的状态空间,子序列会出现指数级别的增长,而在训练体的体积方面只会线性增长。这对字符等级的建模带来了很大挑战,由于当使用字符(而非词语)时,任何子序列都会变长平均 4-5 倍。的确,Vilar 等人(2007)的报告提出,当基于词组的机器翻译系统直接使用字符序列时,表现变得更差。更加近期的,Neubig 等人(2013) 提出了一种方法,用基于词组的翻译系统来提升字符等级的翻译,不过成效有限。
(3)消失的梯度
具体到神经机器翻译,之所以词语等级的建模得到广泛采用,有一个主要原因是对循环神经网络的长期依存性的建模难度(Bengio 等人, 1994; Hochreiter, 1998)。当句子作为字符表征时,由于双方句子长度增长,我们很容易相信未来会有更多的长期依存性,循环神经网络一定会在成功翻译中使用。
3.3 为什么要使用字符等级的翻译?
为什么不使用词语等级的翻译?
词语等级的处理中最紧迫的问题是,我们没有一个针对任何语言的、完美的词语分割算法。一个完美的词语分割算法需要能将任何已知的句子分割为一系列的词素和词位。然而,这个问题本身是一个严重的问题,经常需要几十年的研究(关于芬兰语和其他词素丰富的语言,参见例如 Creutz 和 Lagus (2005)的研究,关于中文,参见 Huang 和 Zhao (2007)的研究)。因此,许多人选择使用基于规则的指令化方法,或者非最优的、不过仍可行的、基于学习的分割算法。
这种非最优分割的结果是,词汇中经常充满许多词义相近的词语,分享同一个词位但是形态不同。例如,如果我们将一个简单的指令话脚本应用于英文,“run”、“runs”、 “ran” 和 “running”(英文“跑步”的一般式、第三人称单数形式、过去式和现在进行式)都是词汇中多带带的条目,尽管它们显然是共享一个相同的词位 “run”。这使得任何机器翻译——尤其是神经机器翻译——都没法正确高效地为这些词形变化的词语建模。
具体到神经机器翻译的情况下来说,每一个词形变体——“run”、“runs”、“ran” 和 “running”——将会分配一个 d 维词语矢量,产生四个独立矢量,虽然如果我们能将那些变体分割为一个词位和其他词素,显然我们就能更加高效地将其建模。举个例子,针对词位 “run” 我们可以有一个 d 维矢量,针对 “s” 和 “ing” 可以有一些更小的矢量。这些变体的每一个之后都会变成词位矢量(由这些变体共享)和语素矢量(由带有相同后缀或其它结构的词语共享)(Botha 和 Blunsom,2014)。这利用了分布表征,在总体上带来更好的抽象化,但好像需要一种最优分割,可惜这总是无法获得。
除了建模中的低效,使用(未分割的)词语还有两个额外的负面结果。首先,翻译系统不能很好地在新词上进行抽象化,经常匹配到一个预留给未知词语的指令上。这实际在翻译中忽略了任何词语的需要融合进来的语义或者结构。第二,即便是一个词位很普遍,经常在训练体里观察到,其词形变体可能不一定。这意味着模型更少地见到这种特定的、罕见的词形变体,而且将不能好好翻译。然而,如果这种罕见的变体与其它更常见的词语共享很大的一部分拼写,我们就希望机器翻译系统在翻译罕见变体时能利用那些常见词语。
为什么使用字符等级的翻译
从某种程度上,所有这些问题都可以通过直接建模字符来解决。虽然数据稀疏性的问题在字符等级的翻译中出现,通过使用一个基于循环神经网络的参数方法(而非一个基于字数的非参数方法)就可以优雅地解决。而且,最近几年,我们已经了解如何打造和训练循环神经网络,来通过使用更复杂的激活函数,例如长短期记忆(LSTM)单元(Hochreiter 和 Schmidhuber,1997)和门限循环单元(Cho 等人, 2014),来良好抓取长期依存性。
Kim 等人(2015)和 Ling 等人(2015a)最近证明了,通过一个神经网络来将字符序列转化为词语矢量,我们可以避免很多词形变量作为词汇中的多带带实体出现。这之所以成为可能,是通过在所有独特指令之间分享“字符到词语”神经网络。一个类似的方法由 Ling 等人(2015b)应用在机器翻译中。
然而,这些最近的方法仍依赖获得一个好的(如果不是最优的)分割算法。Ling 等人(2015b) 的确说:“很多关于词形学、同源词和罕见词翻译等等等先前信息应该被融合进来。”
然而,如果我们直接在未分割的字符序列上使用一个神经网络——无论是循环的、卷积的或者它们的组合——就没有必要考虑这些先前信息了。使用未分割字符序列的可能性已经在深度学习领域中研究了很多年。例如,Mikolov 等人(2012)和 Sutskever 等人2011)在字符序列上训练了一个循环神经网络语言模型(RNN-LM)。后者证明了,只通过从这个模型中一次取样一个字符就可以生成合理的文本序列。最近,Zhang 等人(2015) 及 Xiao 和 Cho (2016)成功地对字符等级文档分别应用了一个卷积网络和一个卷积-循环网络,并且未使用任何显性分割。Gillick 等人 (2015) 进一步证明了可以在 unicode 字节(而非在字符或词语上)训练一个循环神经网络,来进行部分语音自动标注以及命名实体识别。
这些早先研究让我们看到了在机器翻译任务中应用神经网络的可能性,这经常被认为比文件分类和语言建模更加困难。
3.4 挑战与问题
针对源语言方和目标语言方,有两组相互重叠的挑战。在源语言方,我们还未知如何打造一个神经网络来学习拼写和句子语义之间的高度非线性匹配。
在目标语言方有两项挑战。第一项挑战是和源语言方相同,因为解码器神经网络需要总结翻译的内容。此外,目标语言方的字符等级建模更加具有挑战性,因为解码器网络必须得能生成长的、连贯的字符序列。这是一个大挑战,因为状态空间的大小会由于符号的数量而指数增长,而在字符的情况下,经常有300-1000个符号那么长。
所有这些挑战首先都应该描述为问题;目前的循环神经网络——在神经机器翻译中已经广泛使用——能否解决这些问题。这篇论文中,我们的目标是实证性地回答这些问题,并集中考虑目标方的挑战(由于目标方两项挑战都会显示)。
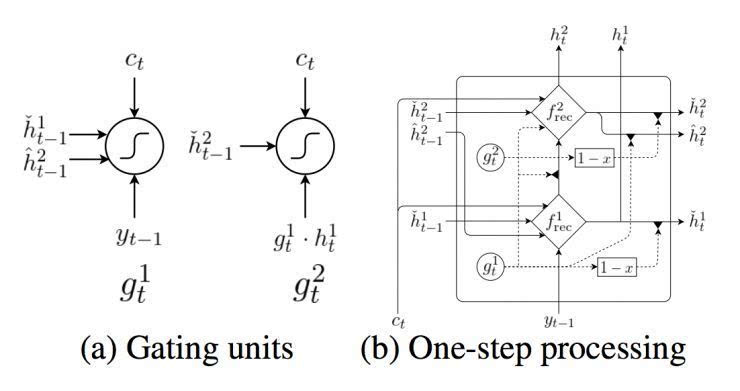
图1: 双度量循环神经网络。
4、字符等级翻译
这篇论文中,我们试图通过在目标方(解码器)测试两种不同类型的循环神经网络,回答早前提出的问题。
首先,我们用门限循环单元(GRU)测试一个现有的循环神经网络。我们将这个解码器称为基准解码器。
第二步,我们在 Chung 等人(2015)的门限反馈网络的启发之下,打造一个新的双层循环神经网络,称为“双度量”循环神经网络。我们设计这个网络来辅助抓取两种时间量程,初衷是由于字符和词语可能在两个分开的时间量程上运行。
我们选择测试这两种选项是为了以下这两种目的。使用基准解码器的实验会明确地回答这一问题:现有神经网络是否能够处理字符等级的解码。这一问题在机器翻译的领域内还没有良好解答过。另一个选项——双度量解码器——也经过测试,为了了解如果第一个问题的答案是肯定的,那么有没有可能设计一个更好的解码器。
4.1 双度量循环神经网络
在这个提出的双度量循环神经网络中有两组隐藏单元,h1 和 h2。它们包含同样数量的单元,即: dim (h1) = dim (h2)。第一组 h1 使用一个快速变化的时间度量(因而是一个更快的层),h2 使用更慢的时间度量(因而是一个更慢的层)。针对每一个隐藏单元,都有一个相关的门限单元,我们分别称为 g1 和 g2。接下来的描述中,我们为之前的目标符号和情景矢量分别使用 yt’-1 和 ct’ (见方程(2))。
让我们先从更快的层开始。更快的层输出两组激活,一个标准输出
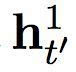
及其门限版本

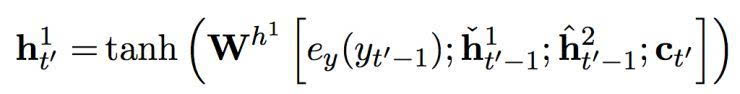
其中
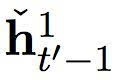
和
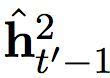
分别是快速层和慢速层的门限激活。这些门限激活由以下方程计算而出:
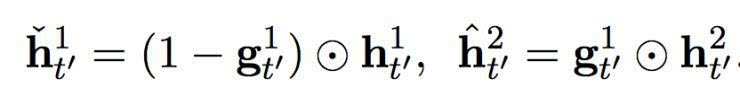
换句话说,快速层的激活是基于之前时间步中,快速层和慢速层的适应性结合。当快速层任务需要重启,即
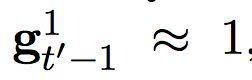
下一个激活将更多地由慢速层的激活而决定。
快速层的门限单元由以下方程计算而出:
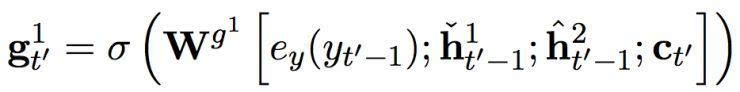
其中 σ 是一个 sigmoid 函数。
慢速层还输出两组激活,一个常规输出

及其门限版本
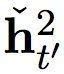
这些激活是由以下方程计算而出:

其中
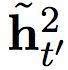
是一个候选激活。慢速层的门限单元是由以下方程计算而出:
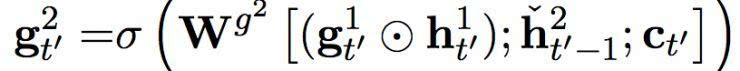
这项适应性融合是基于从快速层而来的门限单元,其结果是,慢速层只有当快速层重启时才更新其激活。这设置了一种软限制,通过防止慢速层在快速层处理一个当前部分时进行更新,使得快速层运行速率更快。
然后,候选激活由以下方程计算而出:
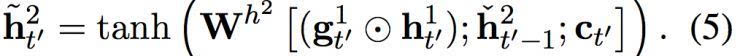

图2:(左)关于源句子长度在 En-Cs 上的 BLEU 分。(右)子字等级解码器和字符等级基准或双度量解码器之间的词语负面对数概率差异。
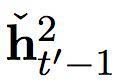
意味着之前时间步的重启,与在快速层中发生的相似,
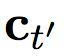
是情景中而来的输入。
根据方程(5)中的
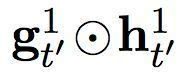 ,
,
只有当快速层已经完成处理目前部分、将要开始重启的时候,快速层才会影响到慢速层。换句话说,慢速层不会从快速层收到任何输入,直到快速层已经完成处理目前部分,因而比快速层的运行速率更慢。
在每一个时间步,所提出的双度量循环神经网络的最终输出,是快速层和慢速层输出矢量的结合,即:[h1; h2]。这个结合矢量用来计算所有符号在词汇中的分布概率,正如方程(4)。详见图1。
5、实验设定
为了评估,我们将一个源句子表征为一系列子字符号序列,用字节对编码(BPE,Sennrich 等(2015))抽取而来,并将目标句子编码为一系列基于 BPE 的符号序列或者一个字符序列。
主体和预处理
我们使用 WMT’ 15 的四个语言对——En-Cs、En-De、En-Ru 和 En-Fi——中所有可用的平行主体。它们分别由 12.1 M、4.5 M、2.3 M 和 2 M 句子对构成。我们我们将每一个主体指令化,使用一个包含在 Moses 中的指令化脚本。当源语言方长达 50 个子字,并且目标方长达 100 个子字标识或者 500 个字符时,我们只使用句子对。我们不使用任何单一语言主体。

表格1: 单一模型及组合的子字等级、字符等级技术和字符等级双量级解码器的 BLEU 分。每一个语言对的单一模型的较佳分数以黑体标记,而组合中的较佳分数以下划线标记。当可获得时,我们返回平均值、较高值和较低值,分别作为下标文字和上标文字。
针对除 En-Fi 之外的所有对,我们使用 newstest-2013 作为发展测试,并使用 newstests-2014 (Test 1) 和 newstests-2015 (Test 2) 作为测试组。针对 En-Fi, 我们使用 newsdev-2015 和 newstest-2015 分别作为发展组和测试组。
模型和训练
我们测试三个模型设定:(1)BPE → BPE,(2)BPE → Char (基准)和(3)BPE → Char (双度量)。后两项的不同点是我们使用的循环神经网络类型不同。我们在所有设定中都使用了 GRU 作为编码器。我们在前两个设定(1)和(2)中使用 GRU 作为解码器,而在最后一个设定(3)中使用了提出的双度量循环网络。针对每一个方向(前馈和反向),编码器具有 512 个隐藏单元,解码器有 1024 个隐藏单元。
我们使用带有 Adam 的随机梯度下降来训练每一个模型(Kingma 和 Ba,2014)。每一个更新都是使用由 128 个句子对组成的迷你批次来计算。梯度的常规是使用阈值 1 来剪切(Pascanu 等,2013)。
解码和评估
我们使用集束搜索来近似寻找特定源句子的最可能的翻译。集束宽对子字等级和字符等级解码器分别是 5 和 15。选择它们是基于发展组的翻译质量。翻译使用 BLEU 进行评估。
多层解码器和软对齐机制
当解码器是一个多层循环神经网络(包括一个堆积网络,以及提出的双度量网络),针对 L 层,解码器一次输出多个隐藏矢量 {h1, …,hL}。这使得软对齐机制(方程(3)中的 fscore)中可以有一个额外的自由度。我们使用其它选项来进行评估,包括(1)只使用 hL (慢速层)和(2)使用所有(结合)。
组合
我们还评估了神经机器翻译模型的组合,在所有四组语言对上,将其与较先进的基于词组翻译系统进行比较。我们取每一步输出概率大平均值,从而从某一个组合中解码。

图3:使用 BPE → Char (双度量)模型,En-De 中测试例子的对齐矩阵。
6、定量分析
用于对齐的慢速层
在 En-De 上,我们测试应该使用哪一层解码器来计算软对齐。在子字等级解码器的情况下,我们没有观察到选择解码器的两层与使用所有层的结合(表格1(a-b))有什么不同。另一方面,有了字符等级的解码器,我们注意到,当针对软对齐机制(表格1(c-g))只使用慢速层(h2)的时候,表现会有提升。这意味着,在目标中将更大的部分与源一方的子字单元对齐,会给软对齐机制带来益处,我们对所有其它语言对都只使用慢速层。
单一模型
在表格1中,我们呈现了一个关于所有语言对的翻译质量的综合报告,包括了(1)子字等级解码器、(2)字符等级基准解码器和(3)字符等级双度量解码器。我们可以看见,针对 En-Cs 和 En-Fi,两种字符等级解码器都比较明显地优于子字等级解码器。在 En-De 上,字符等级基准解码器比子字等级解码器和字符等级双度量解码器都更好,证实了字符等级建模的有效性。在 En-Ru 上,在单一模型中,字符等级解码器优于子字等级解码器,但是,我们观察到所有三种选项之间就总体来说都比较均等。
这些结果显然验证了这一点:不使用显性的分割而进行字符等级的翻译,的确是有可能的。实际上,我们观察到字符等级的翻译质量经常超过词语等级的翻译。当然,我们又一次提到我们的实验有限制,解码器只使用未分割字符序列,未来还需要研究用一个未分割的字符序列来代替源句子。
组合
每一个组合都是使用8个独立模型打造的。我们得出的第一个观察结论是,在所有的语言对中,神经机器翻译与较先进的非神经翻译系统表现相当,或者经常更好。而且,字符等级的解码器在所有情况中都优于子字等级的解码器。
7 定性分析
(1)字符等级的解码器能否生成长的、连贯的句子?
字符翻译比词语翻译要长得多,可能使得循环神经网络以字符生成连贯句子变得更难。这种想法证明是错误的。就像在图2(左)中,子字等级和字符等级的解码器之间没有什么明显不同,虽然生成翻译的长度总体来说在字符里会长5-10倍。
(2)字符等级的解码器对罕见词语有帮助吗?
基于字符建模的其中的一个好处是,可以将任何字符序列建模,因此能更好地对罕见的词形变体进行建模。我们实证性地证实了这一点,通过观察子字等级和字符等级解码器的平均负对数概率,随着词语频率下降,两者之间的差距也越来越大。这展示在图2(右),解释了我们实验中字符等级解码成功背后的一个原因(我们定义 diff (x, y) = x - y)。
(3)字符等级解码器能否在原词语和目标字符之间软对齐?
在图3(左)中,我们展示了一个源句子软对齐的例子,“Two sets of light so close to one another” (两组互相非常接近的灯光)。很明显,字符等级的翻译模型良好抓取了源子字和目标字符之间的对齐。我们观察到,字符等级解码器在生成一个德语复合词 “Lichtersets”(灯的组合)时,正确对齐到了“lights”(灯)和“sets of”(组合)(放大版本详见图3(右))。这种行为在英语单词“one another”和德语单词“einaner” (编者注:都是“互相”的意思)也类似地出现了,这不意味着在原词语和目标字符之间存在对齐。相反,这意味着字符等级解码器的内在状态——基准或者双度量 ——良好抓取了字符有意义的部分,让模型可以将其匹配到源句子中更大的部分(子字)中去。
(4)字符等级解码器的解码速度有多快?
我们在 newstest - 2013 主体(En-De) 上,用一个单一的 Titan X GPU 评估了子字等级基准的解码速度、字符等级基准和字符等级双度量解码器。子字等级基准解码器每秒生产 31.9 个词,字符等级基准解码器和字符等级双度量解码器每秒分别生成 27.5 个单词和 25.6 个单词。注意,这是在一个在线设定中评估的,其中我们进行连续翻译,同一时间只翻译一句话。在批量设定中进行翻译,可能与这些结果不同。
8. 结论
在这篇论文中,我们研究一个基本问题,也就是一个最近提出的神经机器翻译系统是否能直接在字符等级处理翻译,不需要任何词语分割。我们集中在目标方,其中一个解码器需要一次生成一个字符,同时在目标字符和源子字之间进行软对齐。我们大量的实验利用了四个语言对——En-Cs、En-De、En-Ru 和 En-Fi——强有力证明了字符等级的神经机器翻译是可能的,并且实际上会从中获益。
我们的结果有一个局限:我们在源方使用子字符号。然而,这让我们可以获得更加细微的分析,但是在未来必须调查另一种设定,其中源一方也表征为字符序列。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4384.html
摘要:然而反向传播自诞生起,也受到了无数质疑。主要是因为,反向传播机制实在是不像大脑。他集结了来自和多伦多大学的强大力量,对这些替代品进行了一次评估。号选手,目标差传播,。其中来自多伦多大学和,一作和来自,来自多伦多大学。 32年前,人工智能、机器学习界的泰斗Hinton提出反向传播理念,如今反向传播已经成为推动深度学习爆发的核心技术。然而反向传播自诞生起,也受到了无数质疑。这些质疑来自各路科学家...
摘要:在与李世石比赛期间,谷歌天才工程师在汉城校区做了一次关于智能计算机系统的大规模深度学习的演讲。而这些任务完成后,谷歌已经开始进行下一项挑战了。谷歌深度神经网络小历史谷歌大脑计划于年启动,聚焦于真正推动神经网络科学能达到的较先进的技术。 在AlphaGo与李世石比赛期间,谷歌天才工程师Jeff Dean在Google Campus汉城校区做了一次关于智能计算机系统的大规模深度学习(Large-...
摘要:八月初,我有幸有机会参加了蒙特利尔深度学习暑期学校的课程,由最知名的神经网络研究人员组成的为期天的讲座。另外,当损失函数接近全局最小时,概率会增加。降低训练过程中的学习率。对抗样本的训练据最近信息显示,神经网络很容易被对抗样本戏弄。 8月初的蒙特利尔深度学习暑期班,由Yoshua Bengio、 Leon Bottou等大神组成的讲师团奉献了10天精彩的讲座,剑桥大学自然语言处理与信息检索研...
摘要:另外,当损失函数接近全局最小时,概率会增加。降低训练过程中的学习率。对抗样本的训练据最近信息显示,神经网络很容易被对抗样本戏弄。使用高度正则化会有所帮助,但会影响判断不含噪声图像的准确性。 由 Yoshua Bengio、 Leon Bottou 等大神组成的讲师团奉献了 10 天精彩的讲座,剑桥大学自然语言处理与信息检索研究组副研究员 Marek Rei 参加了本次课程,在本文中,他精炼地...

阅读 1468·2021-10-14 09:43
阅读 4363·2021-09-27 13:57
阅读 4632·2021-09-22 15:54
阅读 2673·2021-09-22 10:54
阅读 2511·2021-09-22 10:02
阅读 2193·2021-08-27 13:11
阅读 917·2019-08-29 18:44
阅读 1694·2019-08-29 15:20






