
摘要:于是,中将做了拆解,认为中生成模型应该包含的先验分成两种不能再做压缩的和可解释地有隐含意义的一组隐变量,简写为。利用这种更加细致的隐变量建模控制,可以说将的发展又推动了一步。
摘要
在过去一两年中,生成式模型 Generative Adversarial Networks(GAN)的新兴为生成式任务带来了不小的进展。尽管 GAN 在被提出时存在训练不稳定等诸多问题,但后来的研究者们分别从模型、训练技巧和理论等方面对它做了改进。本文旨在梳理这些相关工作。
尽管大部分时候,有监督学习比无监督的能获得更好的训练效果。但真实世界中,有监督学习需要的数据标注(label)是相对少的。所以研究者们从未放弃去探索更好的无监督学习策略,希望能从海量的无标注数据中学到对于这个真实世界的表示(representation)甚至知识,从而去更好地理解我们的真实世界。
评价无监督学习好坏的方式有很多,其中生成任务就是最直接的一个。只有当我们能生成/创造我们的真实世界,才能说明我们是完完全全理解了它。然而,生成任务所依赖的生成式模型(generative models)往往会遇到两大困难。首先是我们需要大量的先验知识去对真实世界进行建模,其中包括选择什么样的先验、什么样的分布等等。而建模的好坏直接影响着我们的生成模型的表现。另一个困难是,真实世界的数据往往很复杂,我们要用来拟合模型的计算量往往非常庞大,甚至难以承受。
而在过去一两年中,有一个让人兴奋的新模型,则很好地避开了这两大困难。这个模型叫做 Generative Adversarial Networks(GAN),由 [1] 提出。在原始的 GAN paper [1] 中,作者是用博弈论来阐释了 GAN 框架背后的思想。每一个 GAN 框架,都包含着一对模型 —— 一个生成模型(G)和一个判别模型(D)。因为 D 的存在,才使得 GAN 中的 G 不再需要对于真实数据的先验知识和复杂建模,也能学习去逼近真实数据,最终让其生成的数据达到以假乱真的地步 —— D 也无法分别 —— 从而 G 和 D 达到了某种纳什均衡。[1] 的作者曾在他们的 slides 中,给出过一个比喻:在 GAN 中,生成模型(G)和判别模型(D)是小偷与警察的关系。G 生成的数据,目标是要骗过身为警察的判别模型(D)。也就是说,G 作为小偷,要尽可能地提高自己的偷窃手段,而 D 作为警察也要尽可能地提高自己的业务水平防止被欺骗。所以,GAN 框架下的学习过程就变成了一种生成模型 (G) 和判别模型 (D) 之间的竞争过程 —— 随机从真实样本和由生成模型 (G) 生成出的 “假样本” 中取一个,让判别模型 (D) 去判断是否为真。所以,体现在公式上,就是下面这样一个 minmax 的形式。
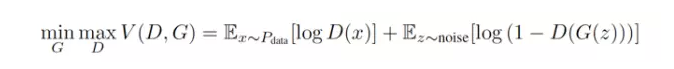
然而,GAN 虽然不再需要预先建模,但这个优点同时也带来了一些麻烦。那就是尽管它用一个 noise z 作为先验,但生成模型如何利用这个 z,是无法控制的。也就是说,GAN 的学习模式太过于自由了,使得 GAN 的训练过程和训练结果很多时候都不太可控。为了稳定 GAN ,后来的研究者们分别从 heuristic 、 模型改进和理论分析的角度上提出了许多训练技巧和改进方法。
比如在原始 GAN 论文 [1] 中,每次学习参数的更新过程,被设为 D 更新 k 回, G 才更新 1 回,就是出于减少 G 的 “自由度” 的考虑。

另一篇重量级的关于 GAN 训练技巧的研究的工作便是 Deep Convolutional Generative Adversarial Networks(DCGAN)[6] 。[6] 中总结了许多对于 GAN 这的网络结构设计和针对 CNN 这种网络的训练经验。比如,他们用 strided convolutional networks 替代传统 CNN 中的 pooling 层,从而将 GAN 中的生成模型 (G)变成了 fully differentiable 的,结果使得 GAN 的训练更加稳定和可控。
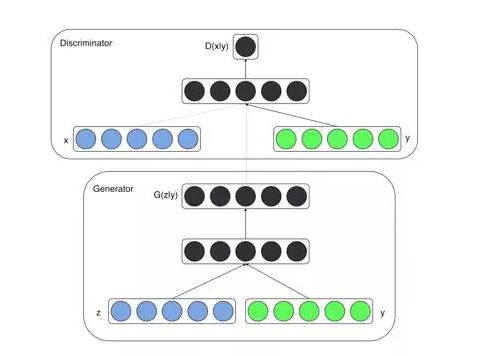
为了提高训练的稳定性,另一个很自然的角度就是改变学习方法。把纯无监督的 GAN 变成半监督或者有监督的。这便可以为 GAN 的训练加上一点点束缚,或者说加上一点点目标。[2] 中提出的 Conditional Generative Adversarial Nets (CGAN)便是十分直接的模型改变,在生成模型(G)和判别模型(D)的建模中均引入 conditional variable y,这个 y 就是数据的一种 label。也因此,CGAN 可以看做把无监督的 GAN 变成有监督的模型的一种改进。这个简单直接的改进被证明非常有效,并广泛用于后续的相关工作中。
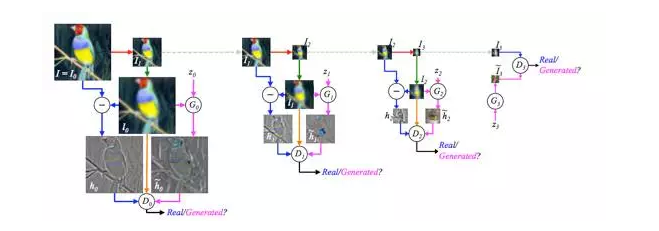
第三种改进 GAN 过于自由的思路,和第一种会比较相似。既然太难控制 GAN 的学习,不如我们就拆解一下,不要让 GAN 一次学完全部的数据,而是让 GAN 一步步完成这个学习过程。具体到图片生成来说就是,不要让 GAN 中的生成模型(G)每次都直接生成一整张图片,而是让它生成图片的一部分。这个思想可以认为是 DeepMind 也很有名的工作 DRAW 的一种变形。DRAW 的论文 [3] 开篇就说,我们人类在绘制一张图片时,很少是一笔完成的。既然我们人类都不是这样,为什么我们要寄希望于机器可以做到呢?论文 [4] 中提出的 LAPGAN 就是基于这个思想,将 GAN 的学习过程变成了 sequential “序列式” 的。 具体上,LAPGAN 采用了 Laplacian Pyramid 实现了 “序列化” ,也因此起名做 LAPGAN 。值得一提的是,这个 LAPGAN 中也有 “残差” 学习的思想(与后来大火的 ResNet 也算是有一点关联)。在学习序列中,LAPGAN 不断地进行 downsample 和 upsample 操作,然后在每一个 Pyramid level 中,只将残差传递给判别模型(D)进行判断。这样的 sequential + 残差结合的方式,能有效减少 GAN 需要学习的内容和难度,从而达到了 “辅助” GAN 学习的目的。
另一个基于 sequential 思想去改进 GAN 的工作来自于 [5] 中的 GRAN。与 LAPGAN [4] 每一个 sequential step(Pyramid level)都是独立训练的不同的是,GRAN 把 GAN 和 LSTM 结合,让 sequence 中的每一步学习和生成能充分利用上一步的结果。具体上来看,GRAN 的每一步都有一个像 LSTM 中的 cell,C_t,它决定了每一步生成的内容和结果;GRAN 中的 h_{c,t} 也如 LSTM 一样,代表着 hidden states 。既然是结合 LSTM 和 GAN,那么说完了 LSTM 方面的引入,便是 GAN 方面的了。GRAN 将 GAN 中生成模型(G)的先验也进行了建模,变成了 hidden of prior h_z;然后将 h_z 和 h_{c,t} 拼接(concatenate)之后传递给每一步的 C_t。
 最后一种改进 GAN 的训练稳定性的方式则更加贴近本质,也是的研究成果。这便是号称 openAI 近期五大突破之一的 infoGAN [7] 。InfoGAN [7] 的出发点是,既然 GAN 的自由度是由于仅有一个 noise z,而无法控制 GAN 如何利用这个 z。那么我们就尽量去想办法在 “如何利用 z” 上做文章。于是,[7] 中将 z 做了拆解,认为 GAN 中生成模型(G)应该包含的 “先验” 分成两种: (1)不能再做压缩的 noise z;(2)和可解释地、有隐含意义的一组隐变量 c_1, c_2, …, c_L,简写为 c 。这里面的思想主要是,当我们学习生成图像时,图像有许多可控的有含义的维度,比如笔划的粗细、图片的光照方向等等,这些便是 c ;而剩下的不知道怎么描述的便是 z 。这样一来,[7] 实际上是希望通过拆解先验的方式,让 GAN 能学出更加 disentangled 的数据表示(representation),从而既能控制 GAN 的学习过程,又能使得学出来的结果更加具备可解释性。为了引入这个 c ,[7] 利用了互信息的建模方式,即 c 应该和生成模型 (G)基于 z 和 c 生成的图片,即 G ( z,c ),高度相关 —— 互信息大。利用这种更加细致的隐变量建模控制,infoGAN 可以说将 GAN 的发展又推动了一步。首先,它们证明了 infoGAN 中的 c 对于 GAN 的训练是有确实的帮助的,即能使得生成模型(G)学出更符合真实数据的结果。其次,他们利用 c 的天然特性,控制 c 的维度,使得 infoGAN 能控制生成的图片在某一个特定语义维度的变化。
最后一种改进 GAN 的训练稳定性的方式则更加贴近本质,也是的研究成果。这便是号称 openAI 近期五大突破之一的 infoGAN [7] 。InfoGAN [7] 的出发点是,既然 GAN 的自由度是由于仅有一个 noise z,而无法控制 GAN 如何利用这个 z。那么我们就尽量去想办法在 “如何利用 z” 上做文章。于是,[7] 中将 z 做了拆解,认为 GAN 中生成模型(G)应该包含的 “先验” 分成两种: (1)不能再做压缩的 noise z;(2)和可解释地、有隐含意义的一组隐变量 c_1, c_2, …, c_L,简写为 c 。这里面的思想主要是,当我们学习生成图像时,图像有许多可控的有含义的维度,比如笔划的粗细、图片的光照方向等等,这些便是 c ;而剩下的不知道怎么描述的便是 z 。这样一来,[7] 实际上是希望通过拆解先验的方式,让 GAN 能学出更加 disentangled 的数据表示(representation),从而既能控制 GAN 的学习过程,又能使得学出来的结果更加具备可解释性。为了引入这个 c ,[7] 利用了互信息的建模方式,即 c 应该和生成模型 (G)基于 z 和 c 生成的图片,即 G ( z,c ),高度相关 —— 互信息大。利用这种更加细致的隐变量建模控制,infoGAN 可以说将 GAN 的发展又推动了一步。首先,它们证明了 infoGAN 中的 c 对于 GAN 的训练是有确实的帮助的,即能使得生成模型(G)学出更符合真实数据的结果。其次,他们利用 c 的天然特性,控制 c 的维度,使得 infoGAN 能控制生成的图片在某一个特定语义维度的变化。


然而实际上, infoGAN 并不是第一个将信息论的角度引入 GAN 框架的工作。这是因为,在 infoGAN 之前,还有一个叫做 f-GAN [8] 的工作。并且,GAN 本身也可以从信息论角度去解释。如本文开篇所说,在原始 GAN 论文 [1] 中,作者是通过博弈论的角度解释了 GAN 的思想。然而,GAN 的生成模型(G)产生的数据和真实数据就可以看做一颗硬币的两面。当抛硬币抛到正面时,我们就将一个真实数据样本展示给判别模型(D);反之,则展示由生成模型 (G)生成的“假”样本。而 GAN 的理想状态是,判别模型(D)对于硬币的判断几乎等同于随机,也就是生成模型(G)产生的数据完全符合真实数据。那么这时候,GAN 的训练过程实际在做的就是最小化这颗硬币和真实数据之间的互信息。互信息越小,判别模型(D)能从观察中获得的信息越少,也就越只能像 “随机” 一样猜结果。既然有了这样一个从互信息角度的对于 GAN 的理解,那么是否能对 GAN 进行更进一步的改造呢?其实是可以的。比如可以把针对互信息的建模更进一步地泛化为基于 divergence 的优化目标。这方面的讨论和改进可以见论文 [8],f-GAN 。
上面这些对于 GAN 的改进工作都几乎是在短短一年半时间内完成的,尤其是近半年。这里面较大的原因就在于 GAN 相较于以前的 generative models,巧妙地将 “真假” 样本转换为一种隐性的 label,从而实现了一种 “无监督” 的生成式模型训练框架。这种思想也可以从某种程度上看做 word2vec 中 Skip-Gram 的一种变形。未来,不仅仅是 GAN 的更多改进值得被期待,无监督学习和生成式模型的发展也同样值得关注。
References:
1.《Generative Adversarial Nets》
2.《Conditional Generative Adversarial Nets》
3.《DRAW: A Recurrent Neural Network For Image Generation》
4.《Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks》
5.《Generating Images with Recurrent Adversarial Networks》
6.《Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks》
7.《InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets》
8.《f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization》
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4380.html
摘要:引用格式王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃生成对抗网络的研究与展望自动化学报,论文作者王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃摘要生成式对抗网络目前已经成为人工智能学界一个热门的研究方向。本文概括了的研究进展并进行展望。 3月27日的新智元 2017 年技术峰会上,王飞跃教授作为特邀嘉宾将参加本次峰会的 Panel 环节,就如何看待中国 AI学术界论文数量多,但大师级人物少的现...
摘要:我们将这些现象笼统称为广义的模式崩溃问题。这给出了模式崩溃的直接解释。而传统深度神经网络只能逼近连续映射,这一矛盾造成了模式崩溃。 春节前夕,北美遭遇极端天气,在酷寒中笔者来到哈佛大学探望丘成桐先生。新春佳节,本是普天同庆的日子,但对于孤悬海外的游子而言,却是更为凄凉难耐。远离父母亲朋,远离故国家园,自然环境寒风凛冽,飞雪漫天,社会环境疏离淡漠,冷清寂寥。在波士顿见到导师和朋友,倍感欣慰。笔...
摘要:判别器胜利的条件则是很好地将真实图像自编码,以及很差地辨识生成的图像。 先看一张图:下图左右两端的两栏是真实的图像,其余的是计算机生成的。过渡自然,效果惊人。这是谷歌本周在 arXiv 发表的论文《BEGAN:边界均衡生成对抗网络》得到的结果。这项工作针对 GAN 训练难、控制生成样本多样性难、平衡鉴别器和生成器收敛难等问题,提出了改善。尤其值得注意的,是作者使用了很简单的结构,经过常规训练...
摘要:近日,谷歌大脑发布了一篇全面梳理的论文,该研究从损失函数对抗架构正则化归一化和度量方法等几大方向整理生成对抗网络的特性与变体。他们首先定义了全景图损失函数归一化和正则化方案,以及最常用架构的集合。 近日,谷歌大脑发布了一篇全面梳理 GAN 的论文,该研究从损失函数、对抗架构、正则化、归一化和度量方法等几大方向整理生成对抗网络的特性与变体。作者们复现了当前较佳的模型并公平地对比与探索 GAN ...

阅读 3297·2023-04-26 02:27
阅读 2184·2021-11-22 14:44
阅读 4165·2021-10-22 09:54
阅读 3236·2021-10-14 09:43
阅读 796·2021-09-23 11:53
阅读 13066·2021-09-22 15:33
阅读 2760·2019-08-30 15:54
阅读 2754·2019-08-30 14:04





