
摘要:浅层结构化预测方法有损失的条件随机域,有的较大边缘马尔可夫网络和隐支持向量机,有感知损失的结构化感知深层结构化预测图变换网络图变换网络深度学习上的结构化预测该图例展示了结构化感知损失实际上,使用了负对数似然函数损失于年配置在支票阅读器上。

卷积网络和深度学习的动机:端到端的学习
一些老方法:步长内核,非共享的本地连接,度量学习,全卷积训练
深度学习缺少什么?
基础理论
推理、结构化预测
记忆
有效的监督学习方法

深度学习=学习层次化表达
传统模式识别方法:固定或手动特征提取
2015年主流的模式识别:利用无监督中层特征进行分类
深度学习:特征具有层次性,通过训练获得
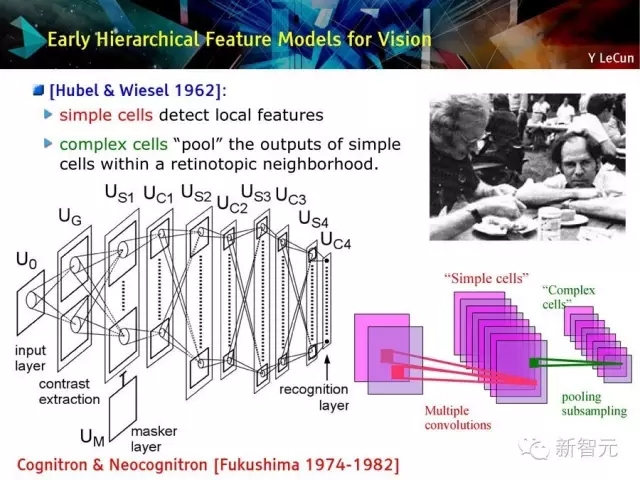
视觉领域早期层次化特征模型
简单细胞检测本地特征
复杂细胞把简单细胞的输出池化在视皮层附近
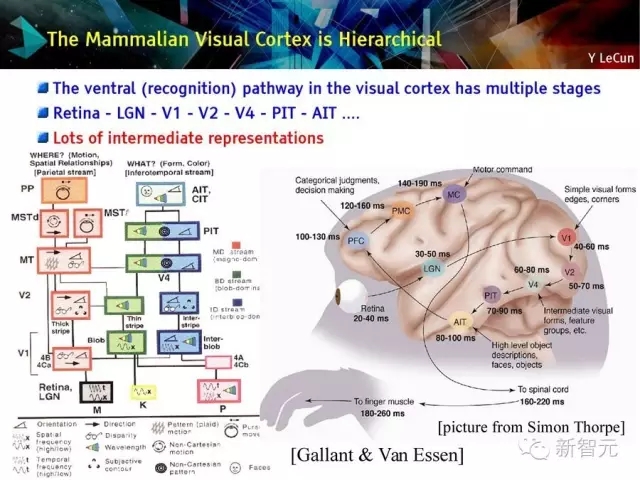
哺乳动物的视皮层是层次化的
视皮层的腹侧识别路径分多个阶段
视网膜 - LGN - V1 - V2 - PIT - AIT
有很多中间表征
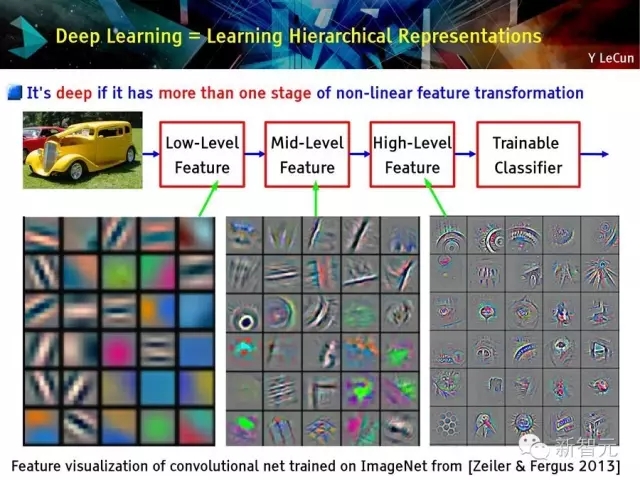
深度的定义:存在多次非线性特征转化
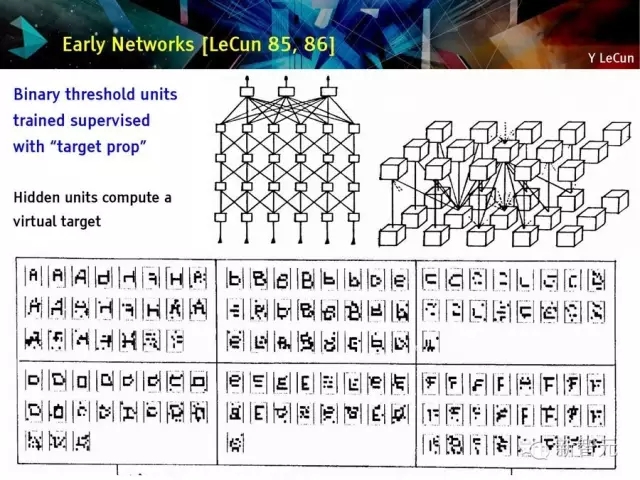
早期网络回顾
目标定位监督训练二值单元
隐藏单元计算虚拟目标
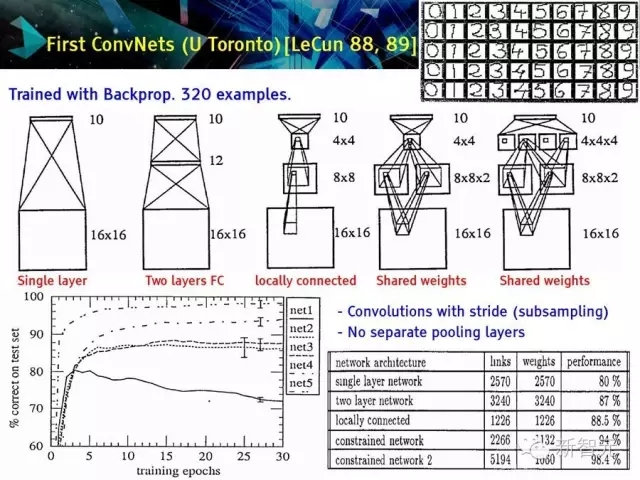
较早的卷积神经网络(U Toronto)[LeCun 88,89]
用反向传播训练320个例子
有步长的卷积
没有分离的池化层

第一个真正意义的深度卷积网络在贝尔实验室诞生 [LeCun et al 89]
用反向传播训练
数据:USPS 邮编号—7300 训练样本,2000测试样本
基于步长的卷积,不具备分离池化/采样层
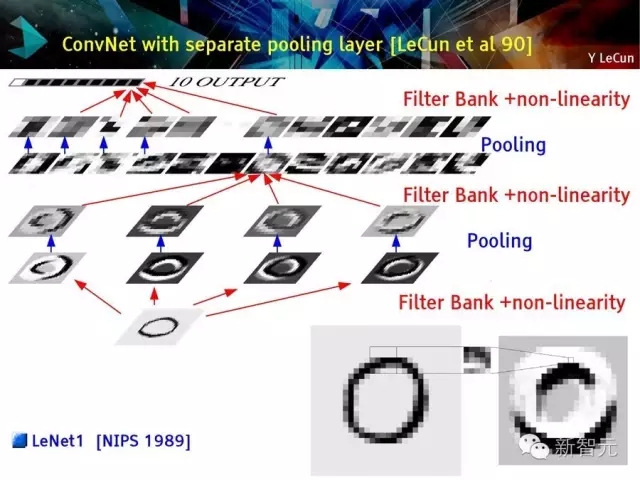
池化层分离的卷积网络

卷积网络 (Vintage 1992)
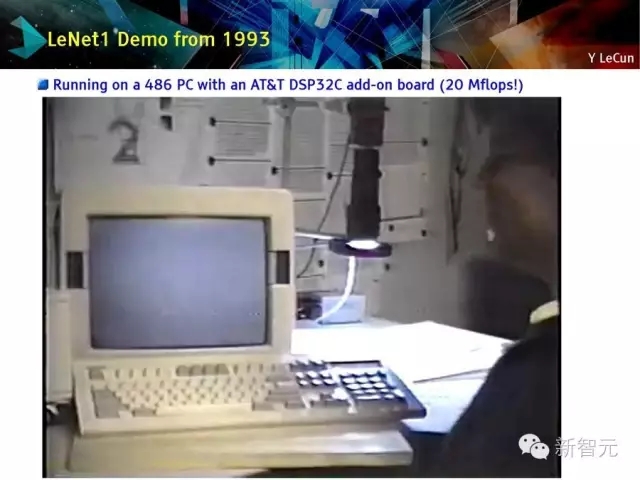
LeNet1 演示系统 (1993)
整合分割多字符识别

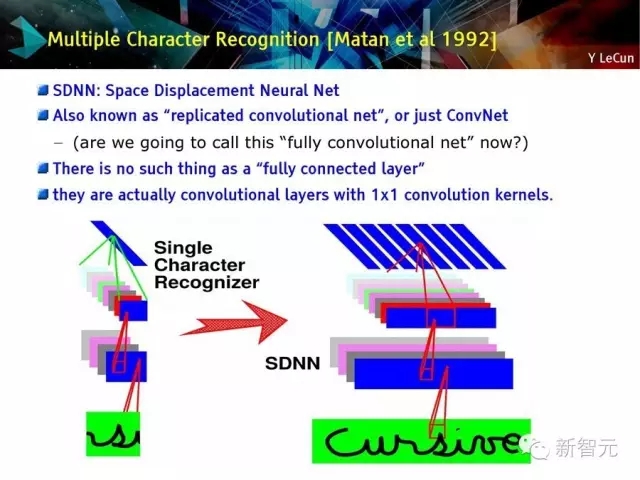
多字符识别 【Matan et al 1992】
SDNN空间移位神经网络
也被称为复制的卷积网络或 ConvNet——问题:我们能否称其为完全卷积网络?
不存在完全连接层
它们实际上是具有1×1卷积内核的卷积层

多字符识别:集成分割
用半合成数据训练
训练样本
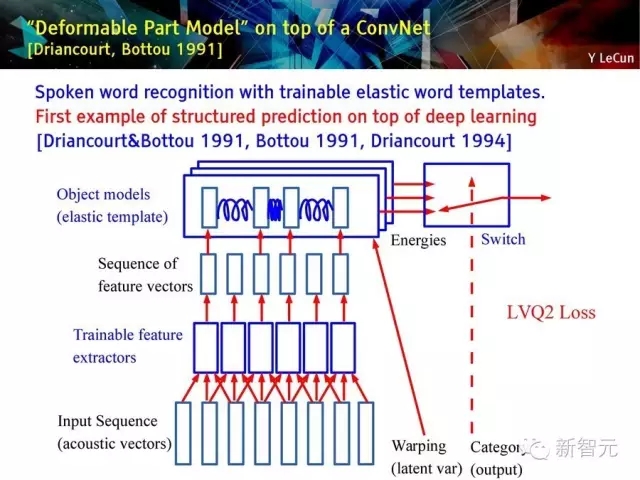
建立在深度卷积网络上的‘Deformable part model’ [Driancourt, Bottou 1991]
具有可训练灵活单词模板的口语单词识别方法;
是第一个建立在深度学习上的结构化预测的例子。

具有灵活单词模型的单词层级训练:
1. 独立的话语单词识别
2. 可训练的灵活模板和特征提取
3. 在单词层进行全局训练
4. 使用动态时间规整(Dynamic Time Warping)进行灵活匹配

结构化预测和深度学习的较早的例子:基于卷积网络(TDNN) 和 动态时间规整(DTW)的可训练自动语音识别系统

端到端学习 -- 单词层的差别训练:
使每一个系统模块成为可训练的
同时训练所有模块从而最优化全局损失函数
过程包括特征提取,识别器,环境后处理器(图像模型)
问题:通过图像模型进行梯度后向传播。
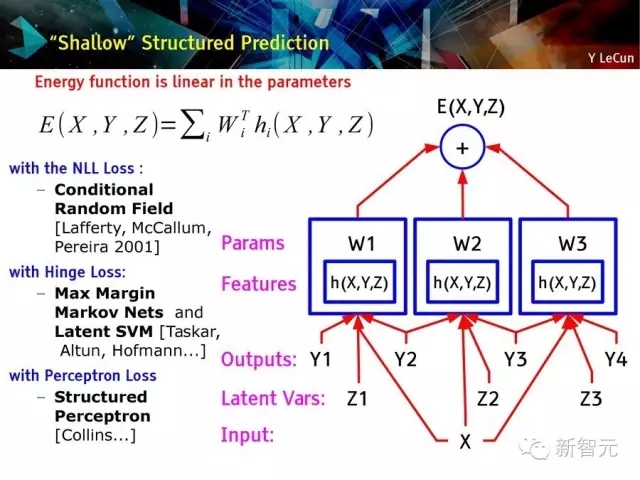
浅层结构化预测方法:
有NLL损失的条件随机域,
有Hinge Loss的较大边缘马尔可夫网络和隐支持向量机(Latent SVM),
有感知损失的结构化感知
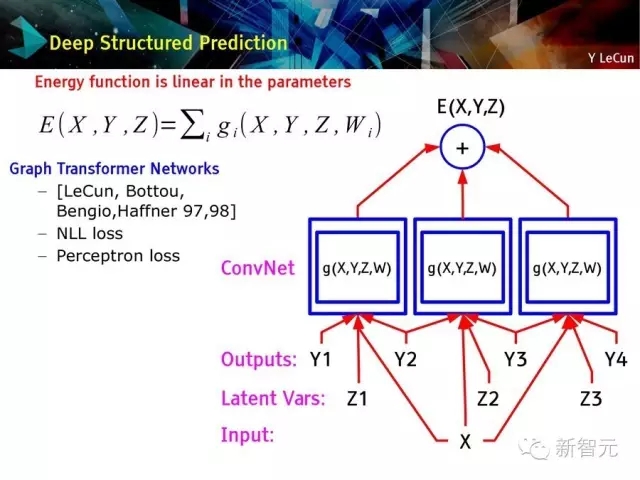
深层结构化预测:图变换网络

图变换网络:深度学习上的结构化预测
该图例展示了结构化感知损失
实际上,使用了负对数似然函数损失
于1996年配置在支票阅读器上。
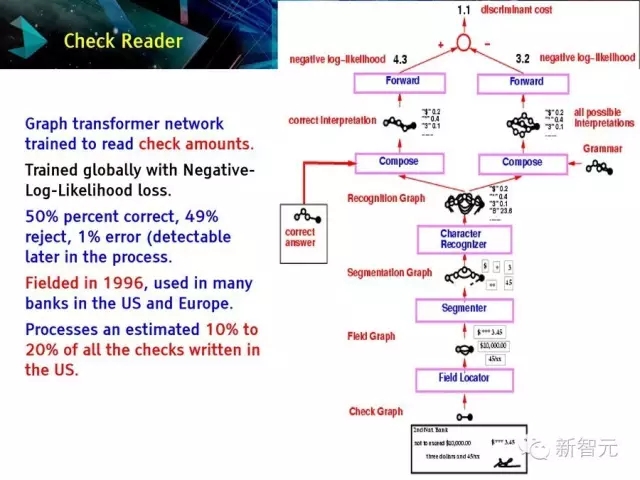
支票阅读器。
图变换网络被用于读支票数量。
是一种基于负对数似然性损失的全局训练。
在1996年被提出,并被美国和欧洲的许多银行应用
目标检测


人脸检测 [Vaillant et al. 93, 94]: ConvNet 被用于大型图片。
利用多个规格的热图,对候选者做非极大值抑制。
在SPARC处理器上运行,处理一副256×256像素的图像需要6秒。

2000年代中期的人脸检测技术成果[Garcia & Delakis 2003][Osadchy et al. 2004] [Osadchy et al, JMLR 2007]

同步人脸识别和姿势估计
语义分割


ConvNets 在生物图像分割领域的应用:
生物图像分割[Ning et al. IEEE-TIP 2005]。
使用convnet在大环境进行像素标记:
ConvNet 对一个窗口中的像素进行处理,并标记该窗口的中心像素。
使用一种条件随机域的方法进行噪音像素清理。
连接组学的三维版本。

ConvNet在长距离适应性机器人视觉中的应用。

用卷积网络建模长距离视觉。

卷积网络体系结构
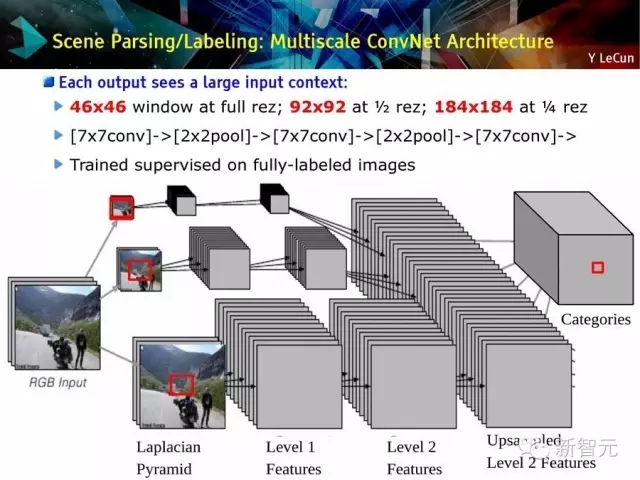
场景分解/标记:多尺度的ConvNet体系
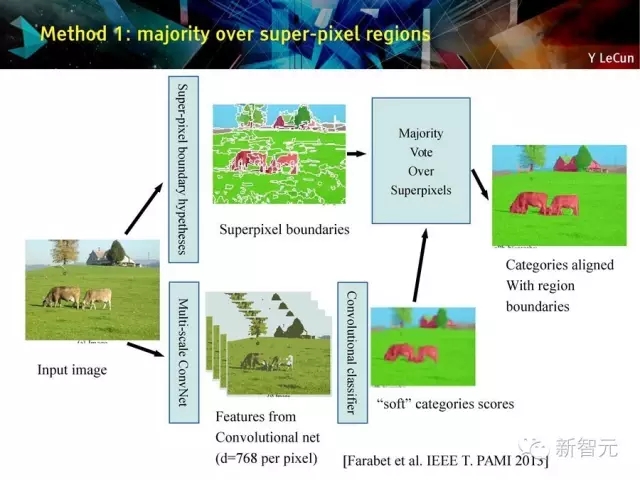
方法1:多数在超像素区

场景解析和标记:用于RGB + 深度图像

场景解析和标记:
没有后处理;
以帧为单位;
ConvNet在Virtex-6 FPGA上运行效率是50ms/帧;
但在以太网上交流特征信息限制系统性能

接下来,两个重要事件:
ImageNet数据集诞生[Fei-Fei et al. 2012],有1200万的训练样本,分类在1000个目录里;
快速图像处理单元(GPU):处理速度达到每秒1万亿次操作
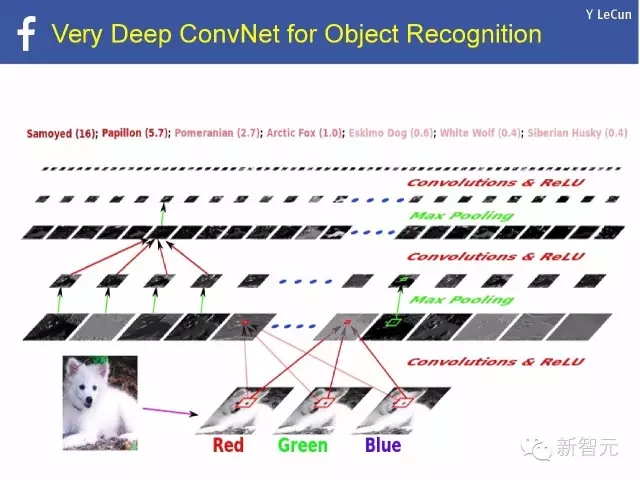
极深ConvNet在对象识别中的应用
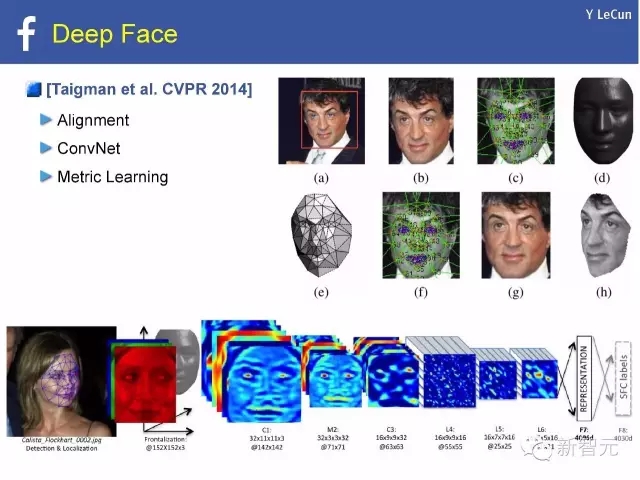
深度人脸[Taigman et al. CVPR 2014]:
对准,
ConvNet,
度量学习
深度学习存在的问题是什么?


深度学习缺少理论
· ConvNets 的优点是?
· 我们到底需要多少层?
· 在一个大型ConvNet中,有多少有效的自由参数?目前来看ConvNet冗余过多
· 局部极小值有什么问题?
(1)几乎所有局部极小值都相等;局部极小的效能退化;
(2)针对这个问题,随机矩阵/spin glass理论被提出[Choromanska, Henaff, Mathieu, Ben Arous, LeCun AI-stats 2015]
基于ReLU 的深度网络:目标函数是分段多项式

深度学习缺少论证
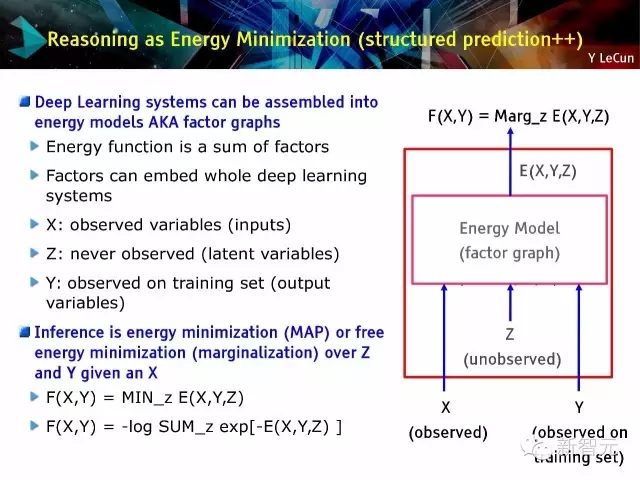
能量最小化论证(结构化预测:structured prediction++)
· 深度学习系统能被组装为能量模型,又名因子图
· 推理过程是能量最小化过程或自由能量最小化(边缘化)
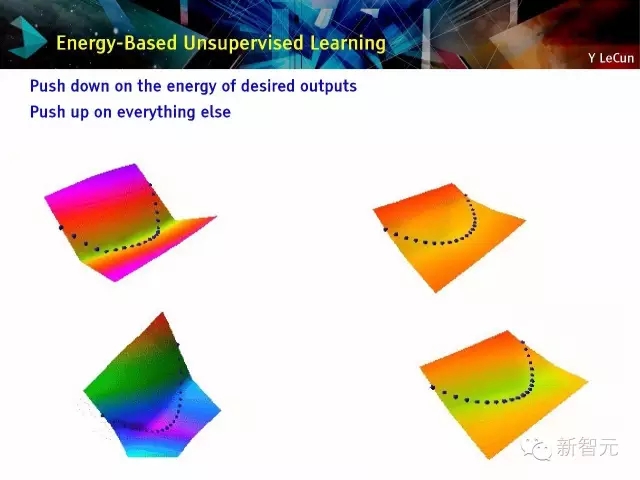
基于能量的学习[LeCun et al. 2006]:按所需输出的能量向下推;按其他向上推

深度学习缺少记忆
自然语言处理:单词嵌入
从上下文预测当前单词
进行成分语义特征
基于卷积或循环网络的文本嵌入:在向量空间中嵌入句子
自然语言处理例子:问答系统
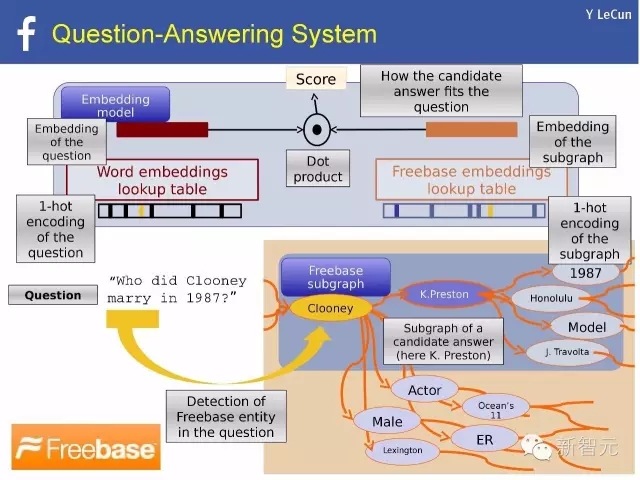
用 Thought vector 表示世界
· 每一个对象,概念,或“想法(Thought)”能被表示成一个向量
· 推理的过程在于对thought vector的操纵
· 记忆存储thought vectors:例子:MemNN(记忆神经网络)
· 在FAIR,我们正试图把世界嵌入思维向量中
· 我们把这个使命叫做:World2Vec
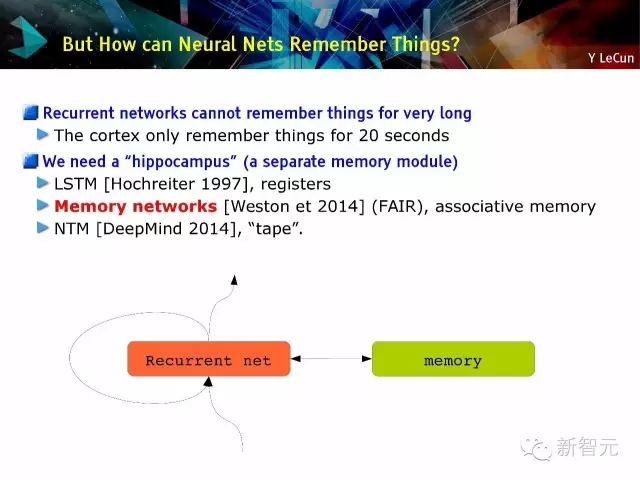
那么神经网络是如何记忆的?
· 循环网络没有长期记忆:皮层只能有20秒的记忆
· 我们需要一个‘海马体’(另一个记忆模块),例如(1)LSTM[Hochreiter 1997] ,寄存器;(2)记忆网络[Weston et 2014](FAIR),联想记忆 (3)NTM[DeepMind 2014],磁带。



塑造能量函数的7个策略:
(1)建立学习机器使得低能量物体的量维持不变;(2)把有能量的数据点向上推,其他地方向下推;(3)把有能量的数据点向下推,特定区域向上推;(4)最小化梯度,较大化数据点周围的曲率;(5)训练一个动态系统使得动态因素转向流形;(6)使用正则化限制低能量区域的扩充;(7)压缩自动编码器(auto-encoder); 使auto-encoder饱和
以下由于篇幅原因,只列出文字,请在新智元后台回复“0703”下载PPT全文
S83. 低能量恒容:建立一个学习机,使得低能量容量恒定
S84. 使用正则器限制低能量区域:
S85. 不同方法的能量函数:二维小数据集:螺旋;能量表层可视化
S86. 基于快速近似推理的字典学习:稀疏自动编码器
S87. 如何在一个生成模型中加速推理?
S88. 稀疏建模:稀疏代码 + 字典学习
S89. 使用正则器限制低能量区域:
稀疏编码,
稀疏自动编码器(auto-encoder)
预测稀疏分解
S90. 编码器体系。
例子:大部分ICA 模型,专家产品
S91. 编码-解码体系。
在感兴趣的数据点上训练一个‘简单的’前向函数去预测复杂优化问题的结果 [Kavukcuoglu, Ranzato, LeCun, rejected by every conference, 2008-2009]
S92. 学习执行近似推理:预测稀疏分解,稀疏自动编码器
S93. 稀疏自动编码器:预测稀疏分解
· 用一个训练的编码器预测最优化代码
· 能量 = 重构错误+代码预测错误+代码稀疏性
S94. 用于非监督特征学习的正则化编码-解码模型(自动编码器)
· 编码器:基于X计算特征向量Z
· 解码器:从向量Z重构输入X
· 特征向量:高维和正则化的(e.g. 稀疏)
· 因子图的能量函数E(X,Z),3项:
线性解码函数和重构错误;
非线性编码函数和预测错误;
池化函数和正则项
S95. PSD: MNIST 上的基础函数:基础函数和(编码矩阵)是数字部分
S96. 预测稀疏分解(PSD):训练。在自然图像块上训练:12×12,256基础函数
S97. 在自然片段上学习特征:V1型感受域
S98. 学习近似推理: LISTA
S99. 更好的想法:把正确的结构给编码器
· ISTA/FISTA: 迭代算法收敛于最优稀疏码
· ISTA/FISTA: 重新参数化
· LISTA(Learned ISTA): 学习 We 和 S 矩阵以加速求解
S100. 训练 We 和 S 矩阵支持快速近似求解
· 把FISTA流图看成一个循环神经网络,其中We 和 S是可训参数
· 时间展开流图进行K次迭代
· 用定时后向传播学习We和S矩阵
· 在K次迭代中获得最优近似解
S101. 学习ISTA (LISTA) vs ISTA/FISTA
S102. 基于局部互抑矩阵的LISTA
S103. 学习坐标下降(LcoD): 比LISTA块
S104. 差异循环稀疏自动编码器(DrSAE)[Rolfe & LeCun ICLR 2013]
S105. DrSAE发现手写数字的流形结构
S106. 卷积稀疏编码
· 利用卷积把点积替换为字典元素;正则稀疏编码;卷积S.C.
S107. 卷积PSD: 用软函数sh()编码.
· 卷积公式:把稀疏编码从PATCH扩展到IMAGE
· 基于PATCH的学习
· 卷积学习
S108. 自然图像上的卷积稀疏自动编码
S109. 使用PSD 训练特征层次。
阶段1:使用PSD训练第一层
阶段2: 用编码器+值做特征提取器
阶段3:用PSD训练第二层
阶段4:用编码器+值做第二特征提取器
阶段5:在顶部训练一个监督分类器
阶段6(可选):用监督反向传播训练整个系统
S110. 行人检测:INRIA数据集。
缺失率(Miss rate)和误报率(False positives)[Kavukcuoglu et al. NIPS 2010] [Sermanet et al. ArXiv 2012]
S111. 非监督学习:不变特征
S112. 用L2组稀疏学习不变特征。
无监督PSD忽略空间池化。
我们能否设计一个相似的方法以学习池化层?
解决方案:特征池上的组稀疏,特点
(1)池的个数必须非0;
(2)一个池中的特征数不重要;
(3)各个池会重组相似特征。
S113. 用L2组稀疏学习不变特征. 该方法的中心思想和发展历程。
· 中心思想:特征被池化成组。
· 发展:
[Hyvärinen Hoyer 2001]: “子空间ICA(subspace ICA)”,仅用于解码,平方;
[Welling, Hinton, Osindero NIPS 2002]: 池化的专家产品(pooled product of experts):仅编码,过完备,L2池化上的对数student-T惩罚;
[Kavukcuoglu, Ranzato, Fergus LeCun, CVPR 2010]: 不变PSD( Invariant PSD)。编码-解码(像PSD),过完备,L2池化
[Le et al. NIPS 2011]: 重构ICA(Reconstruction ICA):与[Kavukcuoglu 2010]相似,具有线性编码器和紧凑解码器
[Gregor & LeCun arXiv:1006:0448, 2010] [Le et al. ICML 2012]: 局部相连非共享(片化的)编码-解码器
S118. 分组都局部于一个2维地形图。
过滤器能自我管理,从而相似过滤器聚集在一个池中。
池化单元可被看为复杂细胞。
池化单元的输出不随输入的局部转化而变化。
S119-120. 图像层训练,局部过滤器,不共享权重:在115×115图像上训练。内核是15×15(不通过空间共享):[Gregor & LeCun 2010]的方法;局部感知域;无共享权重;4倍过完备;L2池化;池上组稀疏。
S121. 地形图. 例子属性:119×119 图像输入,100×100编码,20×20感知域规格,sigma = 5.
S122. 图像层训练,局部过滤器,不共享权重。颜色表明方向(通过拟合Gabors函数)
S123. 不变特征的侧抑制。用侧抑制矩阵替换L1稀疏项;一种给稀疏项强加特定结构的简单方法[Gregor, Szlam, LeCun NIPS 2011]。
S124. 通过侧抑制学习不变特征:结构化稀疏。树中的每条边表明S矩阵中的一个0(无互抑制)。如果树中两个神经元离得远,它们的S比较大
S125. 通过侧抑制学习不变特征:地形图。S中的非0值形成2维拓扑图中的一个环。输入片被高通滤波过滤
S126. 有“慢特征”惩罚的稀疏自编码
S127. 时间恒常的不变特征。对象是实例化参数和对象类型的叉积:映射单元[Hinton 1981],胶囊[Hinton 2011]。
S128. What-Where 自编码体系。
S129. 连接到单个复杂细胞的低层过滤器
S130. 集成监督式和非监督式学习:叠放的What-Where自编码[Zhao, Mathieu, LeCun arXiv:1506.02351]
S132. The bAbI 任务。一个AI系统应该能回答的问题。
具有一个支撑事件的基本仿真QA
具有两个支撑事件的仿真QA
对具有两个支撑事件的仿真QA字符重新排序
有三个支撑事件的仿真QA
两个论证关系:可观的和主观的
三个论证关系
Yes/No 问题
计数
列表和集合
简单拒绝
非决定性知识
基本指代
连词
复合指代
时间操纵
基本推理
基本归纳
位置推理
关于尺寸的推理
寻找路径
行为动机推理
S157. 解决以上这些任务的一种方法:记忆网络(MeNN)
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4379.html
摘要:年的深度学习研讨会,压轴大戏是关于深度学习未来的讨论。他认为,有潜力成为深度学习的下一个重点。认为这样的人工智能恐惧和奇点的讨论是一个巨大的牵引。 2015年ICML的深度学习研讨会,压轴大戏是关于深度学习未来的讨论。基于平衡考虑,组织方分别邀请了来自工业界和学术界的六位专家开展这次圆桌讨论。组织者之一Kyunghyun Cho(Bengio的博士后)在飞机上凭记忆写下本文总结了讨论的内容,...
摘要:毫无疑问,现在深度学习是主流。所以科技巨头们包括百度等纷纷通过收购深度学习领域的初创公司来招揽人才。这项基于深度学习的计算机视觉技术已经开发完成,正在测试。 在过去的三十年,深度学习运动一度被认为是学术界的一个异类,但是现在, Geoff Hinton(如图1)和他的深度学习同事,包括纽约大学Yann LeCun和蒙特利尔大学的Yoshua Bengio,在互联网世界受到前所未有的关注...
摘要:几乎没有人比岁的更能与深度学习紧密地联系在一起。他于年成为纽约大学教授,并从此引领了深度学习的发展。最近,深度学习及其相关领域已然成为最活跃的计算机研究领域之一。 本文原载IEEE,作者Lee Gomes,由机器之心翻译出品,参与成员:电子羊、翬、泥泥刘、赤龙飞、郑劳蕾、流明。人工智能经历了几次低潮时期,这些灰暗时光被称作「AI寒冬」。这里说的不是那段时期,事实上,人工智能如今变得异常火热,...
摘要:今年月日收购了基于深度学习的计算机视觉创业公司。这项基于深度学习的计算机视觉技术已经开发完成,正在测试。深度学习的误区及产品化浪潮百度首席科学家表示目前围绕存在着某种程度的夸大,它不单出现于媒体的字里行间,也存在于一些研究者之中。 在过去的三十年,深度学习运动一度被认为是学术界的一个异类,但是现在, Geoff Hinton(如图1)和他的深度学习同事,包括纽约大学Yann LeCun和蒙特...
摘要:无监督式学习是突破困境的关键,采用无监督学习的对抗训练让拥有真正自我学习的能力。如何让拥有人类的常识认为要用无监督式学习。强化学习是蛋糕上不可或缺的樱桃,所需要资料量可能大约只有几个,监督式学习 6 月 29 日,台湾大学。卷积神经网络之父、FacebookAI 研究院院长 Yann LeCun 以「Deep Learning and the Path to AI」为题,对深度学习目前的发展...

阅读 3300·2021-11-02 14:44
阅读 3771·2021-09-02 15:41
阅读 1765·2019-08-29 16:57
阅读 1833·2019-08-26 13:38
阅读 3358·2019-08-23 18:13
阅读 2155·2019-08-23 15:41
阅读 1722·2019-08-23 14:24
阅读 3081·2019-08-23 14:03






