
摘要:于月日至日在意大利比萨举行,主会于日开始。自然语言理解领域的较高级科学家受邀在发表主旨演讲。深度学习的方法在这两方面都能起到作用。下一个突破,将是信息检索。深度学习在崛起,在衰退的主席在卸任的告别信中这样写到我们的大会正在衰退。
SIGIR全称ACM SIGIR ,是国际计算机协会信息检索大会的缩写,这是一个展示信息检索领域中各种新技术和新成果的重要国际论坛。SIGIR 2016于 7月17日至21日在意大利比萨(Pisa)举行,主会于18日开始。
自然语言理解领域的较高级科学家Christopher Manning受邀在SIGIR2016发表主旨演讲。
Christopher Manning是斯坦福大学计算机科学和语言学教授,曾在卡内基梅隆大学和悉尼大学任教。Manning关注使用机器学习研究计算机语言难题,比如句法分析,计算机语义学、机器翻译等,以及使用深度学习解决自然语言理解(NLP)难题。他还是 ACM Fellow, AAAI Fellow,ACL Fellow。

Manning说,信息检索(IR)和NLP中,有许多问题都是重叠的。IR系统是从理解用户需要和理解文档中生成,进而能够决定某一个文件是否能够满足用户的需要。大多数的NLP做的也是一样的事:NLP的目的是理解问题和文件的意思,以及关系。
NLP中深度学习方法的应用,为计算机语义理解带来了一个有效的工具。演讲集中在两个主题:一是NLP怎样能帮助文本关系理解;二是深度学习如何从根本上实现这一目标。
在这一方面,最成功的工具是新一代的分布式词语表征:神经词汇嵌入。然而,除了词义之外,我们还需要理解怎么分析大型文本的含义。这产生了两个基本的要求,一个是理解人类语言表达的结构,另一个是分析含义。
深度学习的方法在这两方面都能起到作用。最终,我们需要理解文本内的关系,能够处理例如自然语言推理、问答之类的问题。我会继续关注这些领域的研究,有神经网络和没有神经网络的都关注。

图片来自微博xiangnanhe
2013年,深度学习在语音上获得突破;2013年,在计算机视觉上获得突破;2015年,在自然语言理解上获得突破。下一个突破,将是信息检索(IR)。
点击阅读原文可获取Manning演讲笔记。
下面是Manning在斯坦福大学关于自然语言理解和深度学习的演讲,可以帮助我们更好地理解他所说的深度学习对自然语言理解的帮助。
大会另一场主旨演讲 2:Vipin Kumar : 气候大数据下深度学习的机会与挑战
大量数据变得可用的背景下,探讨机器学习的机遇与挑战。
此外,本次大会上共接收了62篇完整论文,其中包括谷歌、微软等大型公司的研究。中国有大量论文被接受,其中包括中科院、华为、百度、人民大学、清华大学、电子科技大学、武汉大学、华中师范大学、华东师范大学等研究机构的论文。
深度学习在崛起,SIGIR在衰退
SIGIR的主席Charlie Clarke 在卸任的告别信中这样写到:“我们的大会正在衰退。”在圈内,这其实已经是一个共识,不管是在大会的茶歇间隙还是热烈的会前讨论中,人们都会说到这一现象。
发生了什么?
现在,有人担心,SIGIR可能不会再吸引那么多的相关的论文。这一种担心基于下面两个观察:
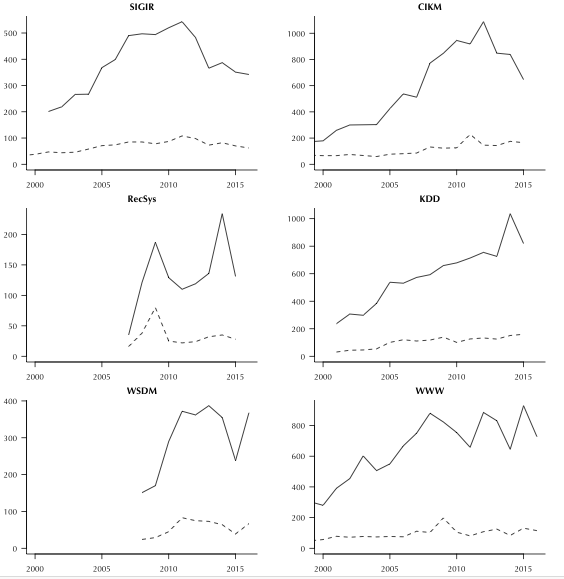
第一个是,2011年提交SIGIR的论文数量达到峰值543篇,但从那之后,就一直在下降。第二个观察,其他同类会议收到的论文数量依然维持在很高的水平,有一些还出现了增加。
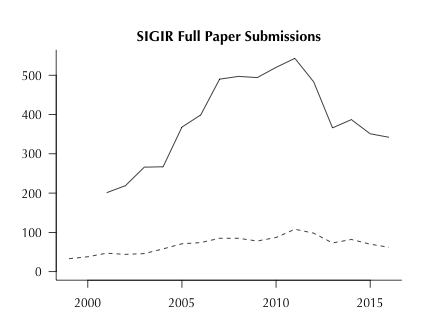
需要强调的是,SIGIR成员观察到,提交到其他会议的论文,其中不少也提交到了SIGIR。
这意味着什么?
从历史上看,SIGIR的研究影响范围很大,其中包括文本分析、计算、机器学习和推荐系统等等。SIGIR的成员担心,如果收到的论文越来越少,那么可能这些有影响力的论文会在别的会议上发表。
8大可能原因
1. 范围太过保守
SIGIR 强调 Ad-hoc 搜索、正式的模型和相关的价值。所以,评议员们会在短时间内就为提交的论文贴上“与大会主题无关”的标签。这么一来,一些带有新颖创意、技术或者问题的作者就会觉得,SIGIR似乎并不欢迎提交论文。范围太过保守带来的机会成本是,会错过一些相关的趋势,比如推荐系统和数据科学。
2.标准太高
SIGIR的评议员强调详尽的实验,没有深度分析的文章会被退回。这带来的影响是:实验分析或计算较少的作者选择了别的会议,尽管他们的研究的观点对于SIGIR社区来说是很有价值的。
3.太多的 IR 会议
SIGIR 虽然是较高级会议,但是还有许多小型的核心会议(CHIIR, ICTIR, ECIR, CIKM) 或者相关会议 ( RecSys, WSDM, WWW, KDD)。许多新的小型会议对SIGIR形成分流。
4.过于强调突破性
许多提交的论文关注于对现状的改进,但是评议员更看重颠覆性的研究。这样,可以指出新的研究方向的理论性论文可能会流向别的会议。
5.可复制性
SIGIR 重视实验的较精确和可复制性,所以一些使用了私有数据的行业性论文难以被接收。行业的研究员更喜欢那些“行业友好”的会议。
6.错误的实验标准
会议只关注一个特定的领域,其他领域受排斥。
7.注册费太贵
8.大公司研究兴趣已经转到了机器学习和核心数据挖掘
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4372.html
摘要:而自然语言处理被视为深度学习即将攻陷的下一个技术领域,在今年全球较高级的学术会议上,我们也看到大量的在深度学习引入方面的探索研究。和也是近几年暂露头角的青年学者,尤其是在将深度学习应用于领域做了不少创新的研究。 深度学习的出现让很多人工智能相关技术取得了大幅度的进展,比如语音识别已经逼近临界点,即将达到Game Changer水平;机器视觉也已经在安防、机器人、自动驾驶等多个领域得到应用。 ...
摘要:而自然语言处理被视为深度学习即将攻陷的下一个技术领域,在今年全球较高级的学术会议上,我们也看到大量的在深度学习引入方面的探索研究。 深度学习的出现让很多人工智能相关技术取得了大幅度的进展,比如语音识别已经逼近临界点,即将达到Game Changer水平;机器视觉也已经在安防、机器人、自动驾驶等多个领域得到应用。 而自然语言处理(NLP)被视为深度学习即将攻陷的下一个技术领域,在今年全球较高级...
摘要:深度学习浪潮这些年来,深度学习浪潮一直冲击着计算语言学,而看起来年是这波浪潮全力冲击自然语言处理会议的一年。深度学习的成功过去几年,深度学习无疑开辟了惊人的技术进展。 机器翻译、聊天机器人等自然语言处理应用正随着深度学习技术的进展而得到更广泛和更实际的应用,甚至会让人认为深度学习可能就是自然语言处理的终极解决方案,但斯坦福大学计算机科学和语言学教授 Christopher D. Mannin...
摘要:还有一些以后补充。十分推荐更多的教程斯坦福的公开课教学语言是。加盟百度前,余凯博士在美国研究院担任部门主管,领导团队在机器学习图像识别多媒体检索视频监控,以及数据挖掘和人机交互等方面的产品技术研发。 转载自http://baojie.org/blog/2013/01/27/deep-learning-tutorials/ Stanford Deep Learning wiki: htt...

阅读 2234·2021-11-16 11:45
阅读 673·2021-11-04 16:12
阅读 1539·2021-10-08 10:22
阅读 960·2021-09-23 11:52
阅读 4314·2021-09-22 15:47
阅读 3734·2021-09-22 15:07
阅读 608·2021-09-03 10:28
阅读 1817·2021-09-02 15:21






