
摘要:本文来自搜狗资深研究员舒鹏在携程技术中心主办的深度学习中的主题演讲,介绍了深度学习在搜狗无线搜索广告中的应用及成果。近年来,深度学习在很多领域得到广泛应用并已取得较好的成果,本次演讲就是分享深度学习如何有效的运用在搜狗无线搜索广告中。
本文来自搜狗资深研究员舒鹏在携程技术中心主办的深度学习Meetup中的主题演讲,介绍了深度学习在搜狗无线搜索广告中的应用及成果。重点讲解了如何实现基于多模型融合的CTR预估,以及模型效果如何评估。

搜索引擎广告是用户获取网络信息的渠道之一,同时也是互联网收入的来源之一,通过传统的浅层模型对搜索广告进行预估排序已不能满足市场需求。近年来,深度学习在很多领域得到广泛应用并已取得较好的成果,本次演讲就是分享深度学习如何有效的运用在搜狗无线搜索广告中。
本次分享主要介绍深度学习在搜狗无线搜索广告中有哪些应用场景,以及分享了我们的一些成果,重点讲解了如何实现基于多模型融合的CTR预估,以及模型效果如何评估,最后和大家探讨DL、CTR预估的特点及未来的一些方向。
深度学习在搜索广告中有哪些应用场景
比较典型的深度学习应用场景包括语音识别、人脸识别、博奕等,也可以应用于搜索广告中。首先介绍下搜索广告的基本架构,如下图:
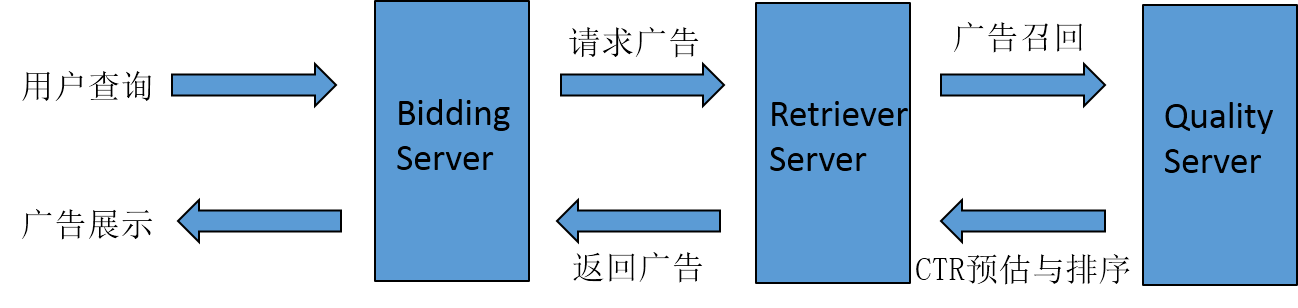
首先用户查询。
查询词给Bidding Server处理,Bidding Server主要负责业务逻辑。例如某种广告在什么情况下不能展现,或这个客户同一个广告在什么时间段什么地域展现。
Bidding Server请求Retriever Server,Retriever Server主要负责召回,广告库很庞大(搜狗的广告库大概在几十亿这个规模),因为数据量非常大,所以需要根据一些算法从中找出和当前查询词最相关的一批广告,这就是Retriever Server做的事情。
Retriever Server处理完后,会把这些比较好的广告回传给Quality Server,Quality Server主要负责点击率预估和排序,此时的候选集数量相对较少,Quality Server会采用复杂的算法针对每条广告预估它当前场景的点击率,并据此排序。
Quality Server将排序结果的top回传给Retriever Server。
Retriever Server回传给Bidding Server。
Bidding Server做封装最后展示给用户。
以上过程中可应用到深度学习的场景如下:

基于多模型融合的CTR预估
CTR预估流程
CTR预估的流程图如下:
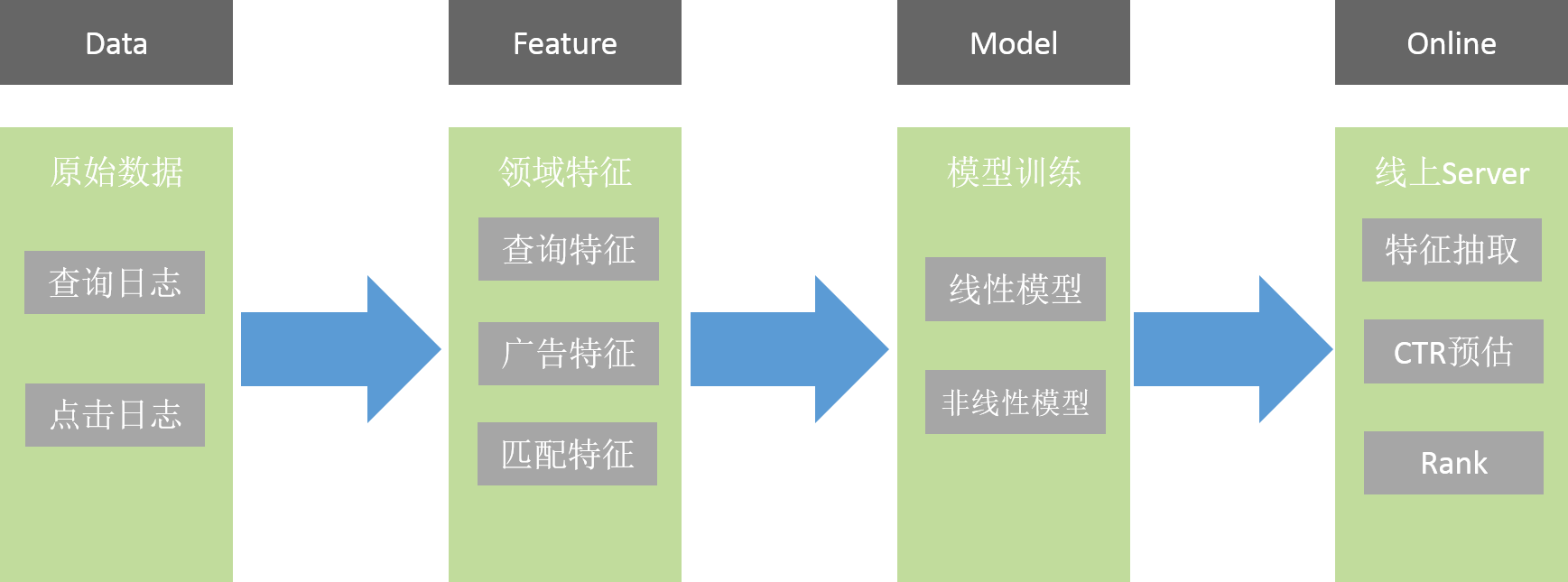
Data是原始数据,包括点击及查询日志,从这些原始数据里抽出一些特征。
Feature包括查询特征、广告特征、匹配特征。
查询特征是和查询词相关的特征,查询发生的地域、时间等。广告特征是指广告本身的信息,例如:来自哪个客户,是哪个行业的,它的关键词是什么,它的标题、描述、网址是什么等各种信息。匹配特征是指查询词和广告的匹配关系。
然后会进行模型的训练,包括线性和非线性。
模型在线下训练完后会到线上,线上Server会实时做特征抽取并预估。
例如:线上实时收到查询请求后,就会知道查询词是什么。前面讲的Retriever Server,它会召回一系列广告,并抽出相关信息,比如广告的标题、关键词、描述等信息,有了这些信息后会利用加载的模型给出预估CTR,最终会进行Rank排序,从而筛选出满足指定条件的一些广告进行展示。
特征设计
离散特征
离散特征是指把东西分散出来表示,比如OneHot,非常直观,例如用户当天所处的时间段,他和最终点击率有关系,那么我把一天24小时分成24个点,他在哪个小时就把哪个点点亮置1,这个特征就设计完了。它的刻画比较细致,设计比较简单,但他的特征非常稀疏,我们线上特征空间非常大,有上十亿,但任何一个请求场景到来,它真正有效的特征大概只有几百个,绝大部分都是空的。因为特征量非常大,不能设计太复杂的模型,否则无法用于线上。
离散特征总结:容易设计,刻画细致,特征稀疏,特征量巨大,模型复杂度受限。
连续特征
还是以时间举例,离散特征会把它变成24个点,连续特征就会变成一个值,比如1、2、3、4、5一直到24,它只会占一个位置。需要仔细设计,很难找到一个直接的方法来描述查询词中包括哪些东西。它是定长的,所以一个请求场景到来,它有多少特征是固定的。不像离散特征是不定长,查询词不一样,有的是两个特征或三个特征,对于特征点可能有两个或三个,这对于我们后面的工作也有一定的影响。连续特征比较稠密,每个位置都会有值,它特征量相对较小,如果用连续特征设计的话可能需要几百维就可以,因此可以使用多种模型来训练。
连续特征总结:需要仔细设计,定长,特征稠密,特征量相对较小,可以使用多种模型训练。
模型类别
线性
优点:简单、处理特征量大、稳定性好。
缺点:不能学习特征间的交叉关系,需要自己去设计。比较典型的如Logistic Regression,有开源的工具包,部署简单且效果不错。
非线性
优点:能够学习特征间非线性关系。
缺点:模型复杂、计算耗时。
比如LR模型就算特征再多,它只是查表加在一起做指数运算就出来了,像DNN、GBDT就会非常复杂,导致计算过程比较慢。
总结:Logistic Regression即能处理连续值又能处理离散值。DNN几乎不能处理离散值,除非做特殊的预处理。
模型融合
前面讲过每个模型都有自己的特点:Logistic Regression处理特征量大,大概在2010年前后开始大量应用于业界,很难有模型能完全超越它;DNN可以挖掘原来没有的东西。我们就想这两个模型能不能将优点进行融合,扬长避短,从而得到更好的结果。
第一种方案:CTR Bagging
有多个模型,将多个模型的输出CTR加权平均。
实现方法简单,模型之间不产生耦合。
可调参数有限,只能调Bagging权重的参数,不能调其他东西,所以改进空间相对较小。
第二种方案:模型融合
任一模型的输出作为另一模型的特征输入,彼此进行交叉。
实现方法复杂,模型之间有依赖关系,因依赖关系复杂,风险也比较高。
好处是实验方案较多,改进空间较大。
我们选了后一种方案,因为单纯CTR Bagging太过简单粗暴了。
模型融合的工程实现
目标
可支持多个不同模型的加载和计算
可支持模型之间的交叉和CTR的bagging
可通过配置项随时调整模型融合方案
避免不必要的重复操作,减少时间复杂度
解决方法(引入ModelFeature的概念)
模型本身也看做一个抽象特征
模型特征依赖于其他特征,通过计算得到新的特征
模型特征输出可作为CTR,也可作为特征为其他模型使用
限定ModelFeature的计算顺序,即可实现bagging模型交叉等功能
模型融合
模型融合流程图如下:
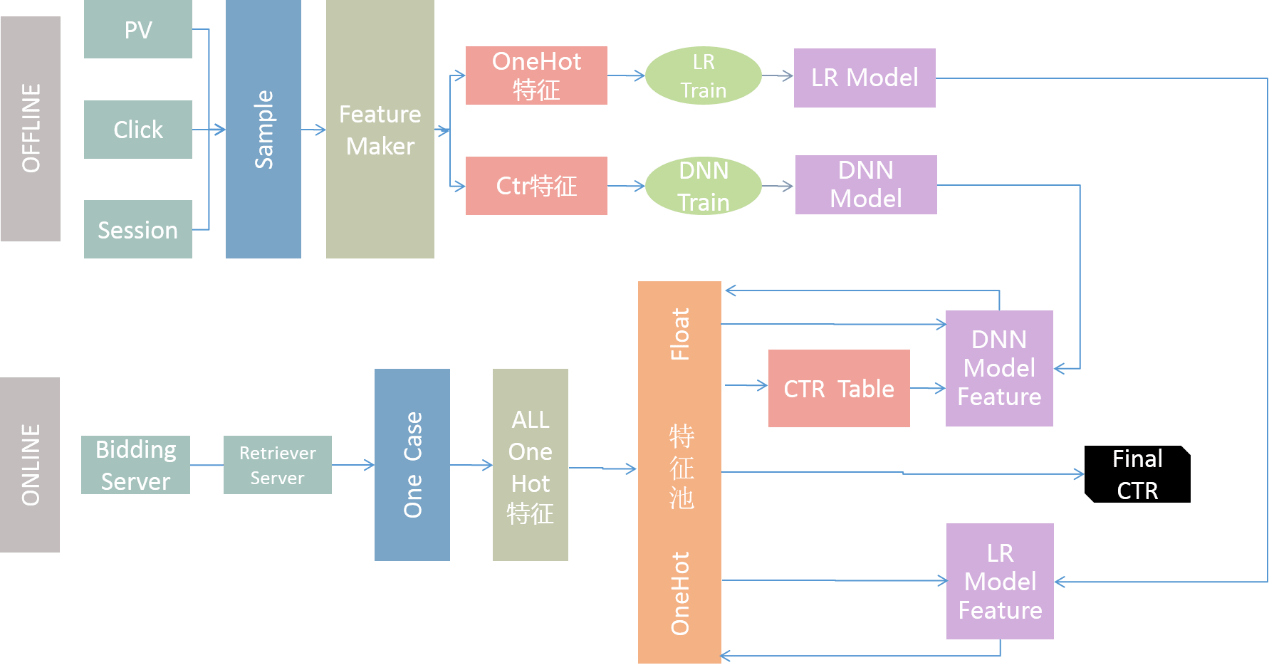
首先线下,将PV、Click、Session做成一个sample。
然后把sample做成特征,包括OneHot、CTR。
分别将OneHot、CTR传送到各自模块的train,就会得到相应的模型。
线上,Bidding Server 会经过 Retriever Server召回广告。
然后传给Quality Server进行计算,它是通过One Case存储和这个查询相关的所有信息。
Quality Server会把One Case里的信息转换成One Hot特征。
然后将结果存到特征池,特征池包含所有特征。
LR模型从特征池里读取数据,而后计算出CTR,还包括其他增量信息。
将这些回送到特征池。
此外DNN模型也会读取特征池里的信息,并将最终计算结果回传给特征池。
CTR可以从特征池里直接取出,然后进行后续的操作。
我们去年将这套框架部署到线上,并持续进行改进,在线上运行了半年多,基本能适用于业务的发展:曾经上线了LR和DNN的交叉,还上线了LR和GBDT的融合。GBDT会将过程信息回传给LR,由LR完成最终输出。此架构经过生产系统的检验,运转正常。
模型效果评估
期间我们会做很多实验,比如DNN训练比较耗时,线上也比较耗时,因此我们会进行多种优化和评估。那么就涉及到一个问题,如何评估一个模型的好坏?线下指标主要采用AUC,定义如下图所示:

我们来分析下这个图,选定一系列阈值将对应一系列点对,形成一条曲线,曲线下方的面积总和就是AUC的值:红线就是纯随机的结果,对应的AUC是0.5;模型越好,曲线离左上角就越近。这个值在我们模型评估里用得非常多,该值考察的是模型预估的排序能力,它会把模型预估排序结果和实际结果进行比对运算。该值很难优化,一般而言,AUC高,模型的排序能力就强。
线下指标AUC很重要,但我们发现单纯靠这指标也是有问题的,不一定是我们的线上模型出了问题,可能是其他的问题。做广告预估,AUC是线下指标,除此之外,最核心的指标是上线收益,有时这两个指标会有不一致的地方,我们也尝试去定位,可能的原因主要有:
Survivorship bias问题:线下训练时所有的数据都是线上模型筛选过的比较好的样本,是我们展示过的比较好的广告,一次查询三条左右,但实际上到了线上之后,面临的场景完全不一样。前面讲过RS筛选出最多近千条广告,这些广告都会让模型去评判它的CTR大概是多少,但实际上训练的样本只有最终的三条,对于特别差的广告模型其实是没有经验的。如果一个模型只适用于对比较好的广告进行排序,就会在线上表现很差,因为从来没有见过那些特别差的广告是什么样的,就会做误判。
特征覆盖率的问题,例如:我们有个特征是和这个广告自身ID相关的,该信息在在线下都能拿到,但真正到了线上之后,因为广告库非常大,很多广告是未展示过的,相关的信息可能会缺失,原有的特征就会失效,线上该特征的覆盖率比较低,最终将不会发挥作用。
并行化训练
做DNN会遇到各种各样的问题,尤其是数据量的问题。大家都知道模型依赖的数据量越大效果越好,因为能知道更多的信息,从而提升模型稳定性,所以我们就会涉及到并行化训练的事情。
加大数据量,提升模型稳定性
我们做搜索广告有一个重要指标:覆盖率,是指此情况下是否需要显示广告。覆盖率高了,用户可能会不满意,而且多出来那些广告多半不太好;但如果覆盖率很低,又等于没赚到钱。这个指标很重要,所以我们希望融合模型上到线上后覆盖率是可预测的。
我们发现这个融合模型会有自己的特点,上到线上之后会有些波动。例如:今天我们刚把模型覆盖率调好了,但第二天它又变了。然后我们分析,可能是因为数据量的问题,需要在一个更大的数据集上训练来提升模型的稳定性。
加大数据量,提升模型收益
其实就是见多识广的意思,模型见得多,碰到的情况多,在遇到新问题的时候,就知道用什么方法去解决它,就能更合理的预估结果。
我们调研了一些方案,如下:
Caffe只支持单机单卡
TensorFlow不支持较大BatchSize
MxNet支持多机多卡,底层C++,上层Python接口
MxNet我们用得还不错,基本能达到预期的效果。
若干思考
Deep Learing的强项
输入不规整,而结果确定。
例如:图像理解,这个图像到底是什么,人很难描述出到底是哪些指标表明它是一个人脸还是猫或狗。但结果非常确定,任何人看一眼就知道图片是什么,没有争议。
具体到我们的广告场景,广告特征都是有具体的含义。例如:时间信息,说是几点就是几点,客户的关键词信息,它写的是什么就是什么,文本匹配度是多少,是高还是低,都有确定的含义。
CTR预估
输入含义明确,场景相关,结果以用户为导向。
例如:一个查询词,出现一条广告,大家来评判它是好是坏,其实它的结果是因人而异的,有人觉得结果很好,而有人却觉得一般,它没有一个客观度量的标准。所以我们认为CTR预估跟传统的DL应用场景不太一样。
我们DNN用到线上后,收益大概提升了百分之五左右,但相对Deep Learing在其他场景的应用,这个提升还是少了些。语音输入法很早就有人做,因为准确率的问题一直没有太大应用,但Deep Learing出来后,比如讯飞及我们搜狗的语音输入法,用起来很不错,准确率相比之前提高了一大截。
未来方向
Deep Learing既然有这些特性,我们会根据特定的业务场景进行应用,比如在某些情况下把它用上去效果会很好,我们还想做一些模型融合的事情。
我们做实验发现把DNN和LR融合后,较好的结果相比LR本身,AUC大概高不到一个百分点。我们也尝试过直接把DNN模型用到线上去,效果很差,就算在线下跟LR可比,但到线上后会有一系列问题,不管是从覆盖率还是从最终收益都会有较大的差异,这是我们在搜狗无线搜索数据上得出的实验结论,大家在各自的业务场景下可能有所区别。
如果你们没有足够经验去手工做各种交叉特征的设计,直接用DNN可能会有好的成果。如果在非常成熟的模型上做,可能需要考虑下,收益预期不要太高。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4370.html

阅读 2890·2021-09-28 09:45
阅读 1550·2021-09-26 10:13
阅读 960·2021-09-04 16:45
阅读 3735·2021-08-18 10:21
阅读 1144·2019-08-29 15:07
阅读 2679·2019-08-29 14:10
阅读 3187·2019-08-29 13:02
阅读 2511·2019-08-29 12:31

