
摘要:深度学习理论在机器翻译和字幕生成上取得了巨大的成功。在语音识别和视频,特别是如果我们使用深度学习理论来捕捉多样的时标时,会很有用。深度学习理论可用于解决长期的依存问题,让一些状态持续任意长时间。
Yoshua Bengio,电脑科学家,毕业于麦吉尔大学,在MIT和AT&T贝尔实验室做过博士后研究员,自1993年之后就在蒙特利尔大学任教,与 Yann LeCun、 Geoffrey Hinton并称为“深度学习三巨头”,也是神经网络复兴的主要的三个发起人之一,在预训练问题、为自动编码器降噪等自动编码器的结构问题和生成式模型等等领域做出重大贡献。他早先的一篇关于语言概率模型的论文开创了神经网络做语言模型的先河,启发了一系列关于 NLP 的文章,进而在工业界产生重大影响。此外,他的小组开发了 Theano 平台。
下文是Yoshua Bengio 2016年5月11日在Twitter Boston的演讲PPT实录,由新智元整理翻译,如果PPT看不过瘾,你还可以复制链接直接观看视频:https://www.periscope.tv/hugo_larochelle/1MYxNDlQkPpGw

原标题:自然语言词义中的深度学习

从ML到AI的三个关键要素:
1. 许多&许多的数据
2. 非常灵活的模型
3. 强大的先验知识,能打破“维度的诅咒”

突破“维度的诅咒”
我们需要在机器学习模型中创建组合词
正如人类语言会分析组合词,为组合词的概念赋予表示和意义
对组合词意挖掘,在指代的能力上获得指数级的增长
分布式表示/嵌入:特征学习
深度架构:多层次的特征学习
先验知识(Prior):组合性在有效地描述我们所处的世界时非常有用

深度学习理论的进展
分布式表示的指数级优势
深度的指数级优势
迷思:非凸性 ∉ 局部最小值
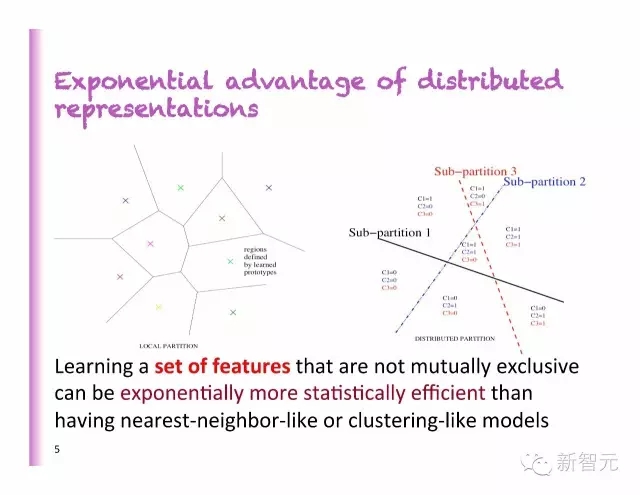
分布式表示的指数级优势
比起最近邻法或分类法的模型,学习一系列不相互排斥的特征,在数据上更有效。

相关推荐论文
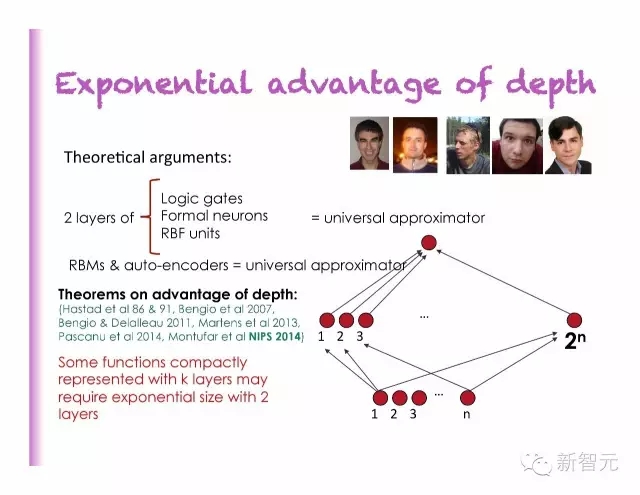
深度的指数级优势


迷思正在被打破:神经网络中的局部最小值
凸性并不是必须的
推荐论文
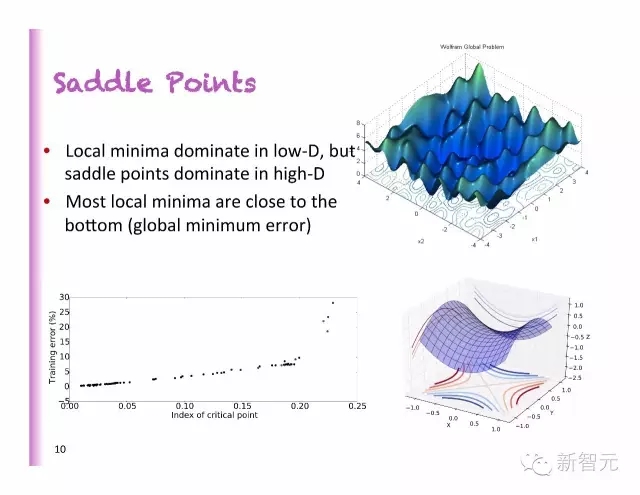
鞍点
局部最小值掌控着低维度,但是鞍点掌控高维度
大多数的局部最小值都很接近底部(全局最小值误差)

为什么N-gram 在泛化上表现很差
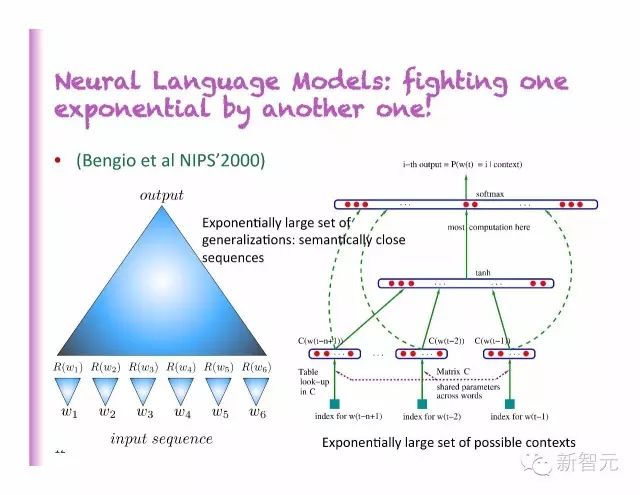
神经语言模型

下一个挑战:词序中丰富的语义表示
捕捉词义上令人印象深刻的进展
更容易的学习:非参数的(查表)
绘制序列来实现更加丰富和完整的指称进行优化的问题
好的测试案例:自动编码框架的机器翻译
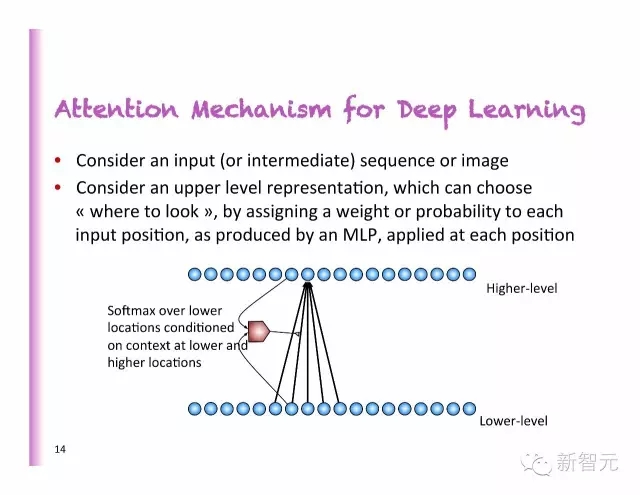
深度学习中的聚焦(Attention)机制
考虑一个输入(或者中间的)序列或者图像
考虑一个高层次的指称,通过设置权重或者每个输入位置的概率,正如MLP中所产生的那样,运用到每一个位置。

聚焦机制在翻译、语音、图像、视频和存储中的应用

端对端的机器翻译
传统的机器翻译:通过相似度的较大化对若干个模型进行独立地训练,在N型图中获的顶部、底部获得逻辑回归。
神经语言模型已经被证明在普遍化的能力上优于N型图模型。
为什么不训练一个神经翻译模型,端对端地评估P(目标句子|源句子)

2014:神经机器翻译获得突破的一年
主要论文
早期的工作
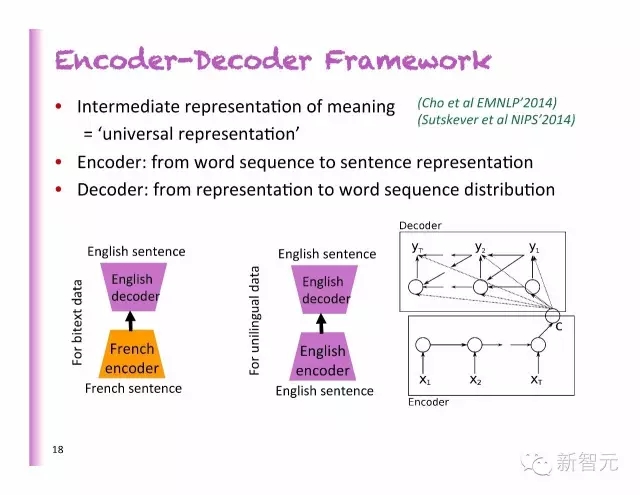
编码-解码框架
中间的意义表示=普遍的表示
编码:从词的排列到句子代表
解码:从代表到词序的分布
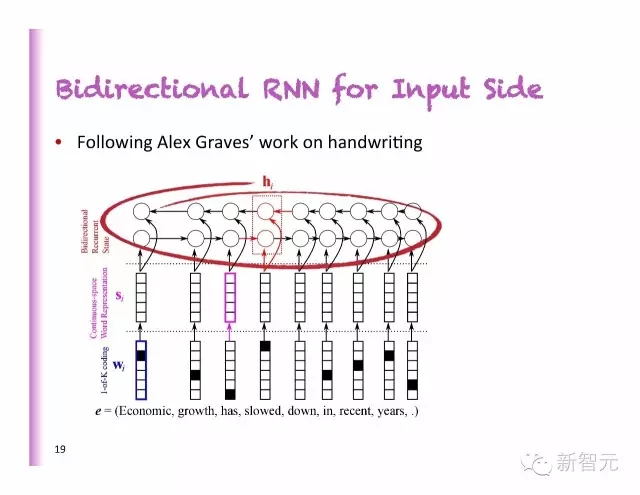
输入侧的双向RNN
模仿Alex Graves在手写体上的工作

聚焦:相关论文和旧论文

软聚焦VS随机硬聚焦
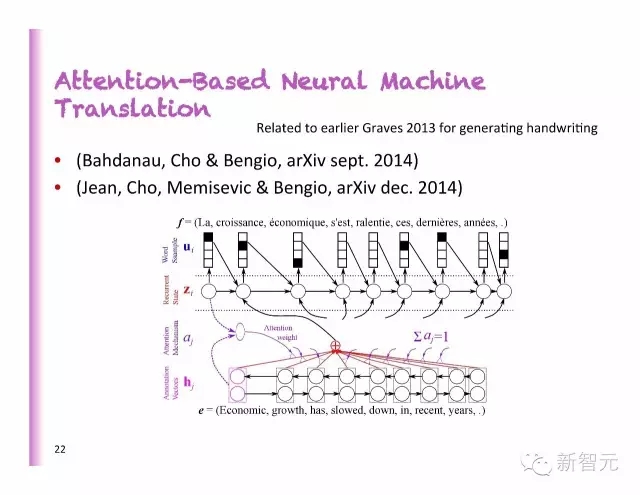
聚焦为基础的神经机器翻译
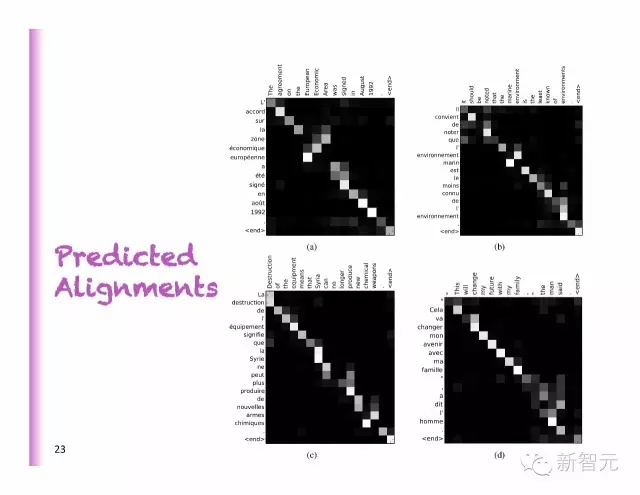
预测对齐

法语和德语不同的对齐

在纯AE模型上的提升
RNNenc:对整个句子进行编码
RNNsearch:预测平面图
BLEU 在全部的测试集中赋分(包括UNK)

周期性网络和聚焦机制下的端对端机器翻译
从零开始,一年后的现状:

英语到德语
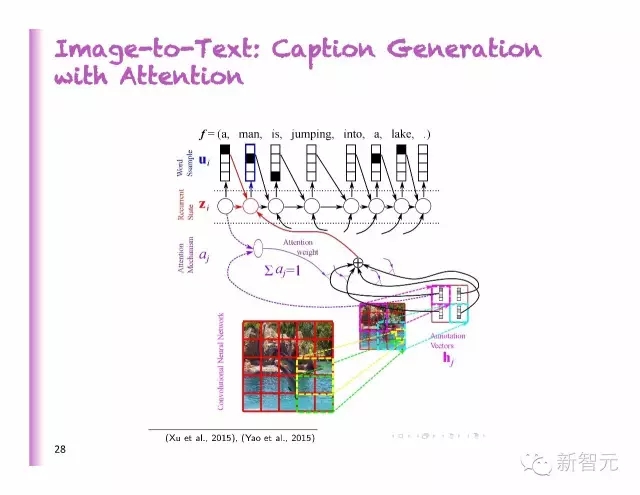
从图像到文字:聚焦模型下的字幕生成

聚焦选择部分图像,同时,生成对应描述词

说出看到的东西
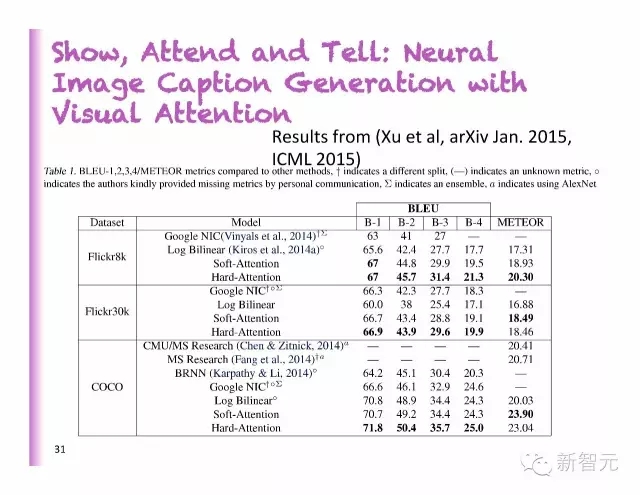
展示、参加和讲述:用视觉聚焦来达到神经图像字幕生成

好的识别

坏的识别

有趣的延伸
用重要性抽样近似值高效地处理大量的词汇(最小批的词=负面的例子)(Jean al, ACL’2015)
多语种 NMT:共享的编码器和解码器,在语言配对中,聚焦机制是一个条件
字符层次的NMT

用共享聚焦机制达成的多语言神经机器翻译
每一种语言对应1 编码器+ 1解码器
一个共享的聚焦模型,还有每一种语言编码和解码规定的“代表翻译函数”
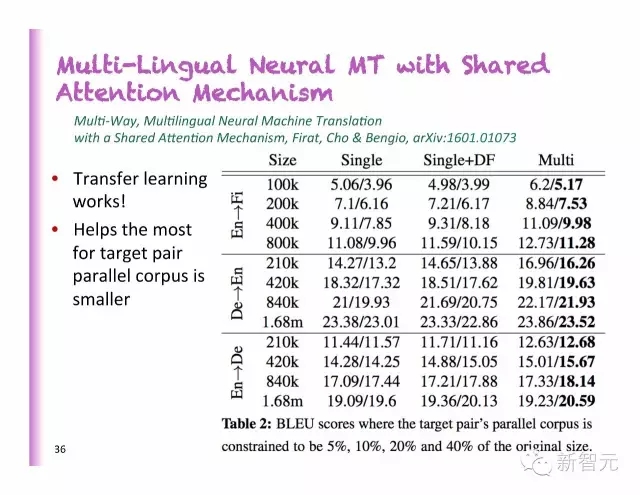
用共享聚焦机制达成的多语言神经机器翻译
迁移学习起了作用
在大多数情况下,对定位成对的平行语料库有益

基于字符的模型
在基于N型图的模型中几乎是不可能的;
但是,对于处理开放词汇问题、拼写错误而、音译、数字等端对端的问题却是有必要的;
对于词汇并没有清晰的区分或者组合线(让词汇量显示)的语言来说是有必要的;
在词的规律(前缀、后缀、连接等)上进行时是有必要的;
障碍:
对于RNNs:更长期的依赖性
较差的容量和计算率
2年前的前期实验:比起基于词汇的模型,可持续性要更差
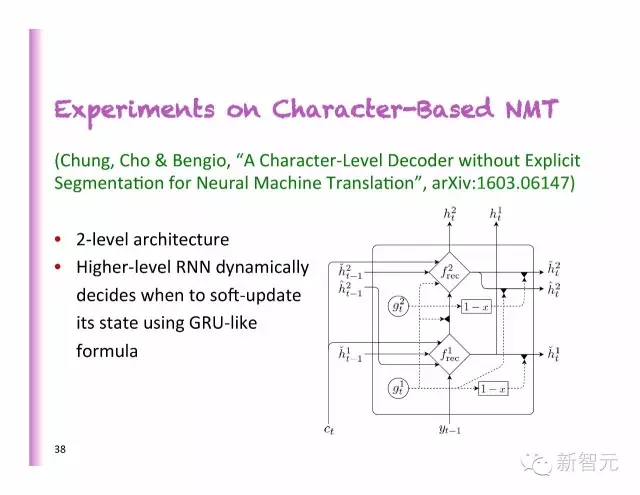
基于字符的NMT实验
2层的架构
更高级别的RNN动态地决定了何时使用类似GRU的公式软性地更新状态

基于字符的NMT实验
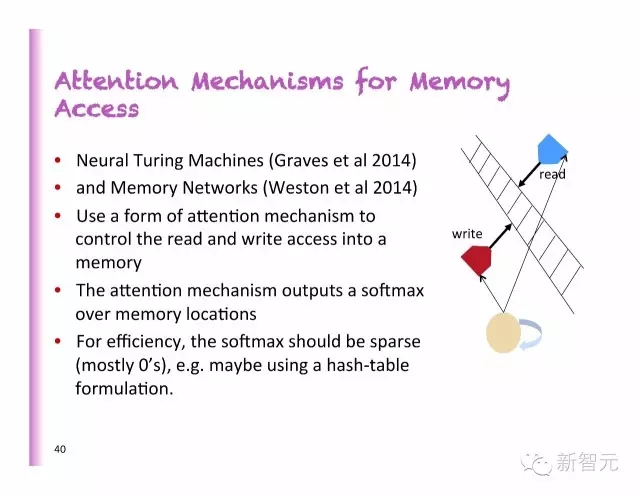
内存访问中的聚焦模型
神经图灵机器
内存网络
使用一个聚焦机制形式来控制对存储器的读取和写入
聚焦机制在内存上输出一个softmax
从效率上看,softmax必须是稀疏的(大多数情况下是0),例如,或许可以使用一个混合图表格式。
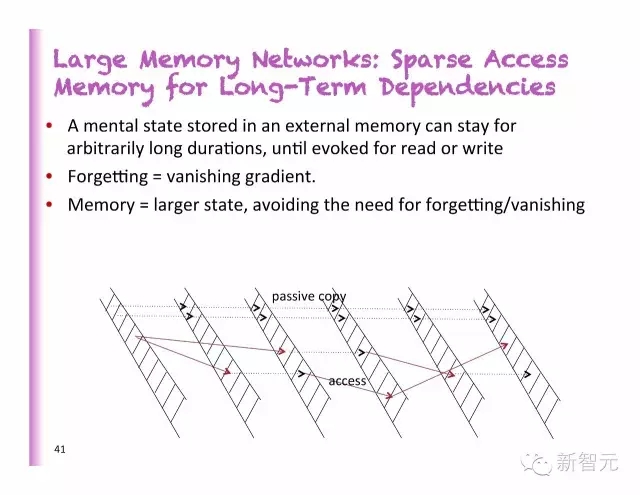
大型内存网络:长期依存的稀疏内存访问
一个外部存储器中的状态,可以保存任意长的时间,直到被读取或写入
忘记=消失的梯度
内存=更大的状态,避免遗忘或者消失的必要

延迟不代表能更进一步
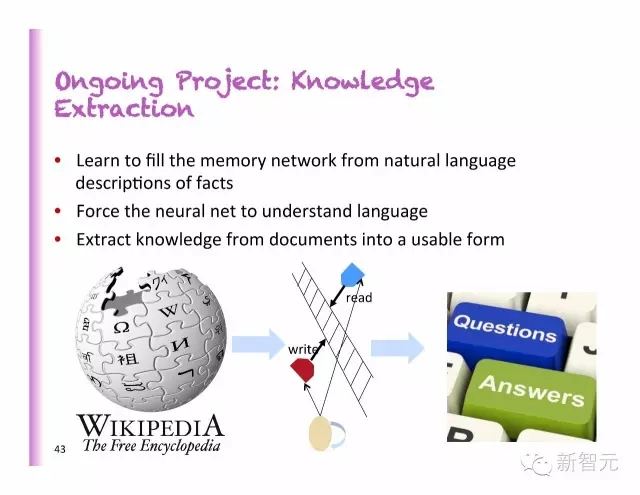
在运行的项目:知识提取
学习从自然语言对事实的描述中填入记忆网络
强迫神经网络理解语言
从档案中提取知识,并浓缩成可使用的格式

下一个大难题:非监督式学习
最近的突破大多数都是在监督式深度学习中
非监督式学习中的真实挑战
潜在的好处:
能处理海量的非标签数据
针对观察的变量,回答新的问题
正则化矩阵——迁移学习——领域自适应
更容易优化(局部训练信号)
结构性的输出
对于没有特定模型或在主要模拟的RL来说很有必要

结论
深度学习理论在许多前沿地带都取得了显著的进步:为什么能更好地泛化?为什么局部最小值不是人们考虑的问题?深度无监督学习的概率解释。
聚焦机制让学习者模型更好地做选择,不管是软聚焦还硬聚焦。
深度学习理论在机器翻译和字幕生成上取得了巨大的成功。
在语音识别和视频,特别是如果我们使用深度学习理论来捕捉多样的时标时,会很有用。
深度学习理论可用于解决长期的依存问题,让一些状态持续任意长时间。
 欢迎加入本站公开兴趣群
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4335.html
摘要:但是在当时,几乎没有人看好深度学习的工作。年,与和共同撰写了,这本因封面被人们亲切地称为花书的深度学习奠基之作,也成为了人工智能领域不可不读的圣经级教材。在年底,开始为深度学习的产业孵化助力。 蒙特利尔大学计算机科学系教授 Yoshua Bengio从法国来到加拿大的时候,Yoshua Bengio只有12岁。他在加拿大度过了学生时代的大部分时光,在麦吉尔大学的校园中接受了从本科到博士的完整...
摘要:年的深度学习研讨会,压轴大戏是关于深度学习未来的讨论。他认为,有潜力成为深度学习的下一个重点。认为这样的人工智能恐惧和奇点的讨论是一个巨大的牵引。 2015年ICML的深度学习研讨会,压轴大戏是关于深度学习未来的讨论。基于平衡考虑,组织方分别邀请了来自工业界和学术界的六位专家开展这次圆桌讨论。组织者之一Kyunghyun Cho(Bengio的博士后)在飞机上凭记忆写下本文总结了讨论的内容,...
摘要:八月初,我有幸有机会参加了蒙特利尔深度学习暑期学校的课程,由最知名的神经网络研究人员组成的为期天的讲座。另外,当损失函数接近全局最小时,概率会增加。降低训练过程中的学习率。对抗样本的训练据最近信息显示,神经网络很容易被对抗样本戏弄。 8月初的蒙特利尔深度学习暑期班,由Yoshua Bengio、 Leon Bottou等大神组成的讲师团奉献了10天精彩的讲座,剑桥大学自然语言处理与信息检索研...
摘要:另外,当损失函数接近全局最小时,概率会增加。降低训练过程中的学习率。对抗样本的训练据最近信息显示,神经网络很容易被对抗样本戏弄。使用高度正则化会有所帮助,但会影响判断不含噪声图像的准确性。 由 Yoshua Bengio、 Leon Bottou 等大神组成的讲师团奉献了 10 天精彩的讲座,剑桥大学自然语言处理与信息检索研究组副研究员 Marek Rei 参加了本次课程,在本文中,他精炼地...

阅读 967·2019-08-30 15:55
阅读 1463·2019-08-30 13:55
阅读 2055·2019-08-29 17:13
阅读 2889·2019-08-29 15:42
阅读 1389·2019-08-26 14:04
阅读 1077·2019-08-26 13:31
阅读 3330·2019-08-26 11:34
阅读 898·2019-08-23 18:25





