
摘要:服务器被标记为不健康,并且在再次通过运行状况检查之前不会向其发送客户端请求。对于上面声明的样本组中的第一个服务器,运行状况检查会请求。响应必须满足块中定义的所有条件,以便服务器通过运行状况检查。
原文链接:何晓东 博客
翻译自 官方文档被动检查
对于被动健康检查,NGINX 和 NGINX Plus 会在事件发生时对其进行监控,并尝试恢复失败的连接。如果仍然无法恢复正常,NGINX 开源版和 NGINX Plus 会将服务器标记为不可用,并暂时停止向其发送请求,直到它再次标记为活动状态。
上游服务器标记为不可用的条件是为每个上游服务器定义的,其中包含块中 server 指令的参数 upstream:
fail_timeout - 设置服务器标记为不可用时必须进行多次失败尝试的时间,以及服务器标记为不可用的时间(默认为 10 秒)。
max_fails - 设置在 fail_timeout 服务器标记为不可用期间必须发生的失败尝试次数(默认为 1 次尝试)。
在以下示例中,如果 NGINX 未能在 30 秒内向服务器发送请求或未收到响应 3 次,则表示服务器在 30 秒内不可用:
upstream backend {
server backend1.example.com;
server backend2.example.com max_fails=3 fail_timeout=30s;
}
需要注意的是如果只有一个单一的服务器组中,将 fail_timeout 和 max_fails 参数被忽略,服务器永远不会标记为不可用。
服务器慢启动最近恢复的服务器很容易被连接淹没,这可能导致服务器再次被标记为不可用。慢启动允许上游服务器在恢复或变得可用之后逐渐将其权重从零恢复到其标称值。这可以指定 upstream 的 server 模块的 slow_start 参数来完成:
upstream backend {
server backend1.example.com slow_start=30s;
server backend2.example.com;
server 192.0.0.1 backup;
}
注意:如果组中只有一台服务器,则 slow_start 参数将被忽略,而服务器永远不会被标记位不可用状态。慢启动是 NGINX Plus 的专有功能
NGINX Plus的主动检查NGINX Plus 可以通过向每个服务器发送特殊的健康检查请求并验证正确的响应来定期检查上游服务器的运行状况。
要启用活动运行状况检查:
在 location 区块将 requests(proxy_pass)传递给上游组的过程中,包含 health_check 指令:
server {
location / {
proxy_pass http://backend;
health_check;
}
}
此代码段定义了一个服务器,它将所有请求匹配到 location / 传递给调用的上游组 backend。它还使用该 health_check 指令启用高级运行状况监视:默认情况下,NGINX Plus 每五秒向组中的每个服务器发送一个 "/" 请求 backend。如果任何通信错误或发生超时(在服务器返回的状态码超出 200- 399的范围)的健康检查失败。服务器被标记为不健康,并且 NGINX Plus 在再次通过运行状况检查之前不会向其发送客户端请求。
另一个可选项:您可以指定另一个用于运行状况检查的端口,例如,用于监视同一主机上的许多服务的运行状况。使用指令的 port 参数指定新端口 health_check:
server {
location / {
proxy_pass http://backend;
health_check port=8080;
}
}
在上游服务器组,使用 zone 指令定义一个共享内存区域:
http {
upstream backend {
zone backend 64k;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
server backend4.example.com;
}
}
该区域在所有工作进程之间共享,并存储上游组的配置。这使工作进程能够使用同一组计数器来跟踪组中服务器的响应。
可以使用 health_check 指令的参数覆盖活动运行状况检查的默认值:
location / {
proxy_pass http://backend;
health_check interval=10 fails=3 passes=2;
}
此处,该 interval 参数将运行状况检查之间的延迟从默认的 5 秒增加到 10 秒。该 fails 参数要求服务器三次运行状况检查失败时,以将其标记为运行状况不佳(从默认值开始)。最后,passes 参数意味着服务器必须通过两次连续检查才能再次标记为健康,而不是默认值。
指定请求的URL在 health_check 指令中指定 uri 参数来设置健康检查请求的路由:
location / {
proxy_pass http://backend;
health_check uri=/some/path;
}
指定的 URI 将附加到为 upstream 块中的服务器设置的服务器域名或IP地址。对于backend 上面声明的样本组中的第一个服务器,运行状况检查会请求URI http://backend1.example.com/s...。
您可以设置响应必须满足的自定义条件,以便服务器通过运行状况检查。条件在match块中定义,该块match在health_check指令的参数中引用。
在 http {} 级别,指定 match {} 块并为其命名,例如:"server_ok"
http {
#...
match server_ok {
# tests are here
}
}
health_check 通过指定块的 match 参数和 match 参数块的名称:
http {
#...
match server_ok {
status 200-399;
body !~ "maintenance mode";
}
server {
#...
location / {
proxy_pass http://backend;
health_check match=server_ok;
}
}
}
如果响应的状态代码在范围中,则传递运行状况检查 200- 399 并且其正文不包含字符串: "maintenance mode"
该 match 指令使 NGINX Plus 能够检查状态代码,标题字段和响应正文。使用此指令可以验证状态是否在指定范围内,响应是否包含标头,或者标头或正文是否与正则表达式匹配。该 match 指令可以包含一个状态条件,一个正文条件和多个标题条件。响应必须满足 match 块中定义的所有条件,以便服务器通过运行状况检查。
例如,下面的 match 指令匹配有状态代码响应 200,精确值 text/html 的Content-Type 标题,页面中的文字:"Welcome to nginx!".
match welcome {
status 200;
header Content-Type = text/html;
body ~ "Welcome to nginx!";
}
以下示例使用感叹号(!)来定义响应不得通过运行状况检查的特征。在这种情况下,健康检查在非 301,302,303,或 307状态码,同时并没有 Refresh 头信息时将通过检查,。
match not_redirect {
status ! 301-303 307;
header ! Refresh;
}
健康检查可以在其他非 HTTP 协议中启用, 例如 FastCGI, memcached, SCGI, uwsgi 甚至 TCP 和 UDP。
很多很好的特性,就是需要 Nginx Plus 才能使用。
顺道推荐几个质量不错的小册 → 去看看
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/40416.html
摘要:服务器被标记为不健康,并且在再次通过运行状况检查之前不会向其发送客户端请求。对于上面声明的样本组中的第一个服务器,运行状况检查会请求。响应必须满足块中定义的所有条件,以便服务器通过运行状况检查。 原文链接:何晓东 博客 翻译自 官方文档 被动检查 对于被动健康检查,NGINX 和 NGINX Plus 会在事件发生时对其进行监控,并尝试恢复失败的连接。如果仍然无法恢复正常,NGINX...
摘要:实现负载均衡负载均衡是反向代理技术的一种运用。而实现负载均衡的核心在于如何将请求合理地分配给不同的后端服务器。 这是 Nginx 学习总结的第六篇,上一篇介绍到了 Nginx 学习总结(5) —— 反向代理,本文主要演示结合 proxy 和 upstream 模块的使用来实现 Nginx 的负载均衡。 Nginx 官网中对 upstream 模块的介绍:ngx_http_upstrea...
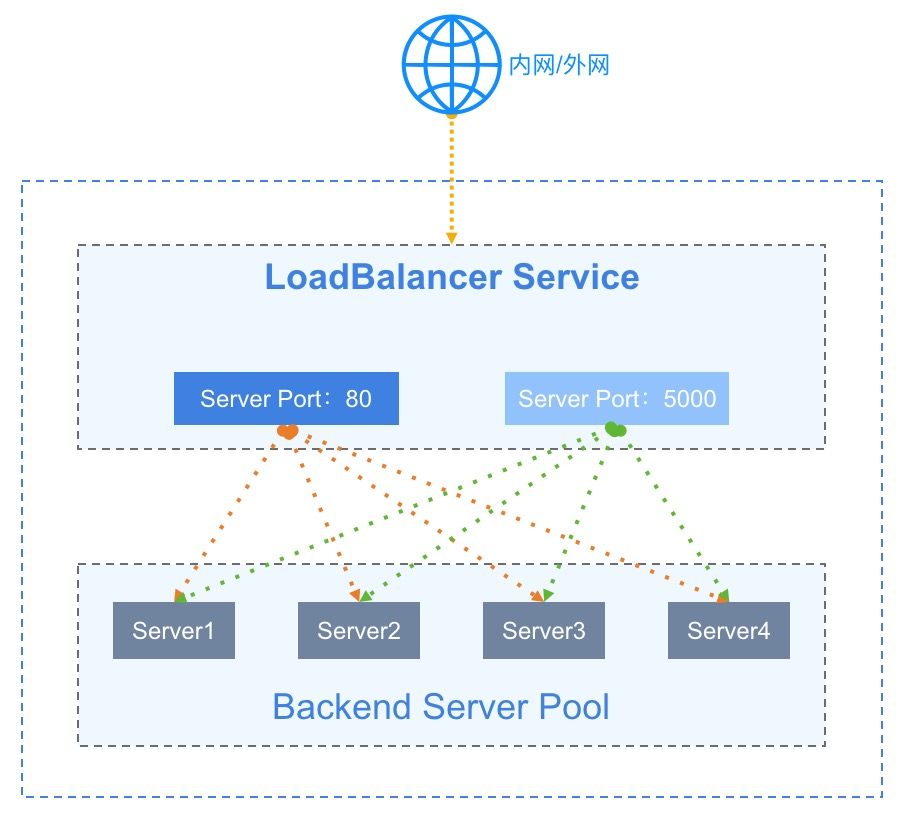
摘要:当负载均衡器接受到来自客户端的请求后,会通过一系列负载均衡算法,将访问请求路由分发到后端虚拟机服务器池进行请求处理,同时由将处理结果返回给客户端。支持内网和外网两种类型负载均衡器,满足内网数据中心及互联网服务负载均衡应用场景。4.7.1 负载均衡概述负载均衡( Load Balance )是由多台服务器以对称的方式组成一个服务器集合,每台服务器都具有等价的地位,均可单独对外提供服务而无须其它...
摘要:负载均衡的平衡机制轮询,向应用服务器的请求以循环方式分发。服务器健康检查中的反向代理实现包括带内或被动服务器运行状况检查。 nginx 负载均衡的平衡机制 轮询,向应用服务器的请求以循环方式分发。 最少连接,下一个请求被分配给具有最少数量活动连接的服务器(最清闲的服务器)。 ip-hash,哈希函数用于确定下一个请求(基于客户端的IP地址)应选择哪个服务器(相同IP 的发送到同一个服...

阅读 1155·2021-10-14 09:43
阅读 1215·2021-10-11 11:07
阅读 3159·2021-08-18 10:23
阅读 1534·2019-08-29 16:18
阅读 1051·2019-08-28 18:21
阅读 1532·2019-08-26 12:12
阅读 3815·2019-08-26 10:11
阅读 2559·2019-08-23 18:04





