

AWS首席数据科学家Matt Wood
亚马逊云计算AWS首席数据科学家Matt Wood认为,大数据和云计算是天作之合,云计算平台的海量低成本的数据存储与处理资源为大数据分享提供了可能。
Matt Wood一天的工作不仅仅是帮亚马逊员工完成数据淘金工作,他还需要设法取悦亚马逊的客户。Wood帮助AWS的用户利用亚马逊云计算资源搭建大数据架 构,然后根据客户需求设计产品,例如数据管道服务(Data Pipeline Service)和Redshift数据仓库服务。
关于基于云计算的大数据服务的发展趋势,记者采访了Matt Wood,会谈的亮点摘录如下:
从资源优先到业务优先
不久前,计算机科学家已经掌握了今日之所谓数据科学的理论和概念,但当时的资源有限,能够进行的数据分析类型也很有限。
如今,数据存储和处理资源已经极大丰富和廉价,这使得大数据的概念成为可能。而云计算则进一步降低了数据存储和处理资源的成本,容量也更大。这意味着数据分析的观念正在经历一次重大的范型转移,从过去资源优先转向以企业需求为先。
如果他们能够突破传统的数据采样和处理模式,一个人就能专注于要做的事情,因为资源太多了。例如,点评网站Yelp允许开发者无限制使用Elastic MapReduce,这样开发者就不必为了测试某个疯狂想法而走繁琐的资源申请流程。Yelp能够在一年前发现网站流量的移动化趋势并及时开展移动业务都得益于此。
数据的问题不都是规模
总的来说,客户的数据问题并不都是如何更低的成本存储更多的数据,你不一定需要1PB的数据才能分析出谁是你社交游戏的用户。
实际上,能够无限制的存储和处理数据本身会产生新的问题。公司希望能够保存所有产生的数据,这会导致复杂性增加。从亚马逊的S3和DynamoDB服务到企业数据中心的物理服务器,当数据在所有的库中都堆积如山时,数据转移和复用的难度也会变得很大。
AWS新推出的数据管道服务(Data Pipeline Service)就是为了解决这个问题。管道非常复杂,从运行一个简单的数据业务逻辑到在Elastic MapReduce上运行所有的批任务,数据管道服务的目的就是将数据的移动和处理自动化,用户无需自己建立这些工作流程并手动运行。
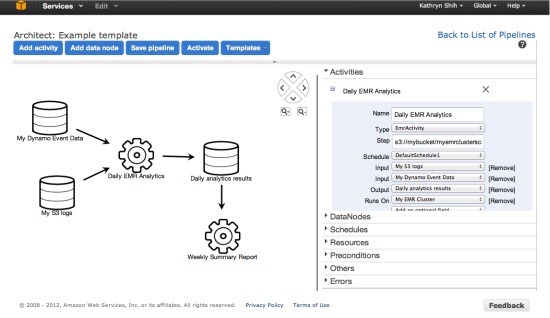
AWS数据管道服务控制台
把大数据快递给云计算
人们有时候会质疑云计算与大数据任务之间的相关度,因为如果将企业内部系统产生的数据都上传到云端,由于受到网速限制,数据规模越大,上传的时间就越长。为了解决这个问题,亚马逊想尽各种办法,包括与Aspera合作,甚至与那些研究在互联网上快速转移大文件(Wood说见过700MB/秒的技术)的开源项目合作。此外,亚马逊还取消了传入数据的收费,并开启了并行上传功能。此外亚马逊还与数据中心运营者合作启动了直连项目(Direct Connect Program),为亚马逊AWS设施提供专线连接。
最后,如果客户的数据量实在太大,网速又不够快,还可以直接将存有数据的硬盘快递给亚马逊。
协作是未来趋势
当数据迁移到云端后,就开启了一种全兴的协作方式,研究人员,乃至整个行业都能访问和分享这些过去因体量太大而无法移动的数据。一些产生海量数据的行业已经开始在云端分享数据,例如AWS上已经托管的1000个基因组项目。
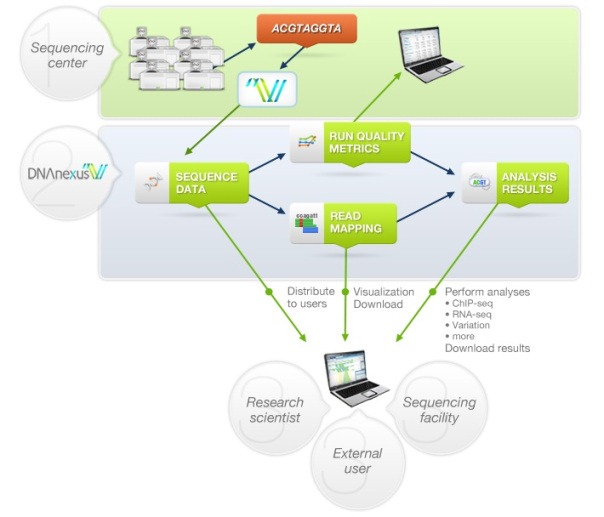
DNAnexus的云架构
遗传学项目从云计算中受益匪浅,虽然AWS上的1000个基因组项目的数据库只有200TB,但是单个项目很少有足够的预算存储这么多数据并与同事分享。即使在资金充裕的医药领域,亚马逊CTO Werner Vogels曾说过,医药企业正在使用云计算分享数据,企业们也无需花费时间和金钱"重新发明车轮"。
不再需要超级计算机?
Wood对亚马逊高性能计算客 户在AWS平台上的工作印象深刻——这些工作过去必须依赖超级计算机才能完成。这要感谢AWS的合作伙伴Cycle Computing,维斯康辛大学如今在AWS上能够一周内完成过去需要116年的计算任务。AWS正在不断增加实例的配置和性能,从较大的250GB内 存到GPU集群计算实例,AWS都将提供。出于成本的考虑,AWS目前仅在一部分市场提供集群计算实例和Elastic MapReduce。
如今很多运行数据密集型工作负载的企业都开始将目光投向云计算。大数据(尤其是Hadoop)和云计算年纪相仿,相辅相成,可谓天作之合。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4039.html







