
摘要:本文是关于我如何应用基本性能分析技术,借助火焰图做了一处小改进,使得我们计算机集群的状况获得了倍的改善,并在第二年帮助节省了几百万刀。最终,通过对平均大小在的事件进行批量插入,我们的吞吐量获得了的提高。
本文是关于我如何应用基本性能分析技术,借助火焰图做了一处小改进,使得我们 Postgres 计算机集群的 CPU 状况获得了 10 倍的改善,并在第二年帮助 Heap 节省了几百万刀。
针对用户分析的索引数据
Heap 是一个用户分析工具,它自动捕捉每个用户与网站或应用进行的交互行为。成功安装于网站后,Heap 会自动追踪每个页面的浏览量、点击量、表单提交等信息。这样每个网站拥有者可以针对不同子集的原始数据,使用 Heap 来执行不同种类的聚合。
为了能够对无意义的原始数据有所洞见,Heap 能让用户根据原始数据自定义事件。“登陆”就是一个例子,可以定义为“在 /login 页面进行表单提交”。
为了加快分析速度,我们用了一个非常规的索引策略,它基于 Postgres 的部分索引特性。部分索引就像一个普通的 Postgres 索引,不同点在于它只包含了满足特定谓词 (predicate) 的行,你可以把它想象成带有 WHERE 条件的常规索引。针对每个用户创建的事件定义,我们根据用户的原始事件数据,创造了一个部分索引,并将其绑定在满足定义的行上。每当我们的 events 表格中插入一条新行,Postgres 会自动将它与表内现存的每条部分索引的谓词进行测试,并将其加入匹配的索引中。
针对每个事件定义,对应的部分索引能让它快速获得所有的匹配事件,因为索引恰恰包含了满足定义的事件。你应该阅读我们这篇关于如何索引数据的博客,它更加深入地介绍了部分索引的相关内容。
问题初显:异常的高 CPU 占用率
当我们第一次运用这条索引策略时,对比之前的策略,我们的 CPU 占用率有了大幅上升。我们认为这是正常的现象,因为我们较大的客户有着成千上万条索引,而为了支持基于 CSS 选择器的过滤器,大部分的部分索引都包含了一个正则表达式过滤器。我们认为由于正则表达式的求值极其耗时耗力,而每个插入的事件都要经过上千条正则表达式的测试,这就成了高 CPU 占用率的合理解释。尽管没有明显的证据表明这就是原因,但每个使用 Heap 的人都慢慢将它当作了 CPU 占用率过高的合理解释。它被看作是新索引策略带来的根本妥协。
十月左右,随着数据量的持续增长,问题开始出现:高峰时间无法消化所有信息。有时候新事件需要花费数小时才能显示在 Heap 仪表板上,而这对一个实时分析工具而言完全不可理喻。抛开通过花钱解决问题的常规路线,我想动手尝试优化 Heap 的信息吞吐量问题。
用火焰图对 CPU 占用情况可视化
此前我鲜有调试此类性能问题的经验。在搜索了一阵后,我看到了大牛 Brendan Gregg 写的一篇关于火焰图的文章。火焰图是 Brendan Gregg 发明的一种可视化方法,用于快速查看哪些部分正在占用 CPU。创建火焰图的第一步是使用 Linux perf 工具从进程堆栈中取样:
perf record -p $(pid of process) -F 99 -g -- sleep 60
它会对指定的进程堆栈以每秒 99 次的速度,进行持续一分钟的取样,并将数据写入 perf.data 数据文件中。这样,你就可以从 Brendan Gregg 的火焰图数据库中运行以下命令,对文件进行分析并生成火焰图:
perf script | ./stackcollapse-perf.pl > out.perf-folded ./flamegraph.pl out.perf-folded > flame-graph.svg
我最初创建的火焰图之一是 Postgres 的后端进程。因为我们使用了连接池,一个简单的后端进程要服务多项请求。由于我们运行的最多的请求是 INSERTs,Postgres 后端进程的火焰图能够让我们清楚地看到,事件插入数据库时的 CPU 占用情况。在 pid 中对来自 pg_stat_activity 的 Postgres 进程运行以上命令后,我获得了下面这张火焰图:
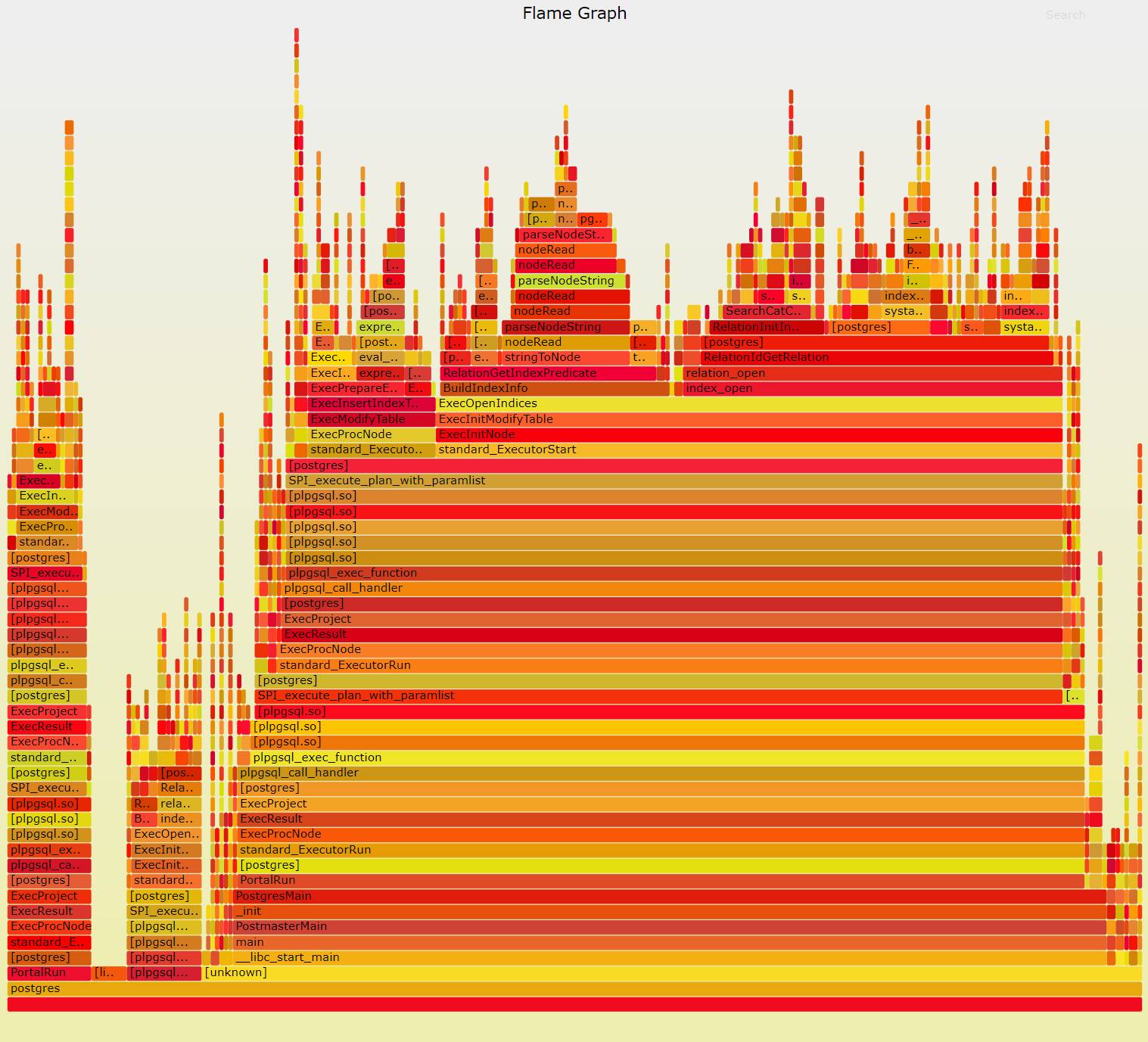
对于新手而言,火焰图可能非常难以理解。Brendan Gregg 给出以下解释帮助我们理解一张火焰图:
X 轴显示堆栈剖面群体,以字母顺序排序(而不是时间的流逝),Y 轴显示堆栈深度。每个方块框代表了一个堆栈帧。帧越宽,代表了它在堆栈中出现的频率越高。顶端显示了 CPU 正在运行的进程,下面是历史进程。颜色通常而言并不重要,它们是随机分配的,用来区分不同的框架。
从火焰图中可以清楚地看到,大约 55% 的 CPU 时间花在了 ExecOpenIndices 上(图中行右侧区域的大黄色条)。视线上移一点,可以看到大部分的时间被两个不同的功能所消耗,它们是 BuildIndexInfo 和 index_open。BuildIndexInfo 调用了 RelationGetIndexPredicate,而后者花费了 ~20% 的总 CPU 时间。这样来看,大部分时间都花在了 RelationGetIndexPredicate 上。
仔细查看 RelationGetIndexPredicate 的源代码,它的作用是解析和优化部分索引谓词。这就解释了为什么 RelationGetIndexPredicate 耗费了如此大量的时间,因为相比对已解析表达式进行求值,解析二进制表达式要更加困难。
现在我们再看看剩下花在 ExecOpenIndices 上的时间。其中大部分剩余时间花在了 index_open 上。看上去 index_open 先调用了 relation_open,后者又调用了 RelationIdGetRelation。从 RelationIdGetRelation 的源代码文件中,可以看到它的作用是查找不同关系的元数据(本次问题中它主要用于查找部分索引)。根据 RelationGetIndexPredicate 和 RelationIdGetRelation 消耗的时间,看起来 Postgres 花费了更多的时间用于获取和解析部分索引谓词,而不是对其求值。
实施修复
看了不同函数的源代码,可以发现存在着大量的缓存。在 RelationGetIndexPredicate中,Postfres 先检测是否已抽取谓词并立即返回它。
RelationIdGetRelation 先使用 RelationIdCacheLookup 来检查关系源数据是否已经过计算并缓存。通常情况下,索引元数据只需要经历一次获取和解析,剩下的时间都是从缓存中读取。
不幸的是,因为我们每次将一个事件写入数以万计的不同表格,缓存出了问题。Postgres 有一个服务请求的进程池,并且每个进程都有多带带的缓存。这些进程对每次插入都分配了轮询 (round-robin)。由于共享的模式中现存上万张基础表格,每次插入事件时,很有可能将两次事件插入同一进程的同一张表中,也就是说索引元数据几乎无法在执行插入时进行缓存。因此,Postgres 几乎每次都需要在插入事件时,获取并解析目的表格的索引元数据。
根据这一点,我们可以做一个简单的改进:与其将每个事件多带带插入表格,我们可以对需要插入相同表格的事件进行一次批量插入。通过运行一个简单的命令来批量插入事件,Postgres 就只需要在每次批处理时获取和解析索引元数据。我们之前本想进行批量插入以减少执行计数,但不是出于节省 CPU 资源的目的,因为我们假设所有的 CPU 都要用于对索引谓词求值。
批量插入的初始基准显示 CPU 占用率得到了 10x 的缩减。得知了这一结果,我们开始在生产中测试批量插入。最终,通过对平均大小在 ~50 的事件进行批量插入,我们的吞吐量获得了 10x 的提高。这是对不同 Kafka 部分的吞吐量传输延迟时间,进行批处理前后的对比:左边的单位是延迟时间 (latency time)。我们能够在几分钟内清理完一个小时的积压 (backlog)。
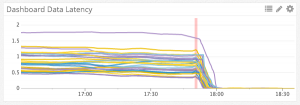
在实行批处理后,我又生成了一张插入事件的火焰图:

这一次图上显示大部分的时间都归于 ExecQual(中间的红条),而根据源码,而它是作用是对部分索引谓词进行求值,也就是说这一次 Postgres 将大量的 CPU 用在了正途上。
我在半年前发现了这个问题。自此,我们不需要给集群增加额外的 CPU,而且看起来以后的几个月也不用这样做。我只是运用了基本的性能分析就有如此成效,没花什么力气就获得了 10 倍的收益。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3965.html
摘要:美国金融行业监管局有的重要应用目前正运行于亚马逊云端服务上面,其中包括市场监测应用,每年因此节省万美元的费用。穆林斯负责与金融企业达成新的云服务协议。 配图:安全性不再是云服务客户最担心的事情北京时间3月19日消息,路透社今天撰文指出,对于美国金融公司而言,使用共享云服务的益处是显而易见的。市场研究公司IDC预计,得益于云服务,到2019年全球较大几家银行将节省150亿美元的庞大资金,技术基...
摘要:上榜较多的国家还有德英法,历年数量一直稳在附近。本年度上榜企业利润情况极少数负利润,大部分纯利润集中在一百亿美元以下。总结从世界五百强年的榜单分析了那么多,有些地方确实值得骄傲。 前言: 前几天看到新闻才知道今年的500强已经出炉了,后面又看到小米首次进榜,第468名,雷军蜀黍开心的像个只有几十亿元的小孩子。还特意发了好几条微博: showImg(https://segmentfau...

6月20日周四,OpenAI竞争对手Anthropic发布了公司迄今为止性能最强大的AI模型Claude 3.5 Sonnet。在覆盖阅读、编程、数学和视觉等领域的多项性能测试中,Claude 3.5 Sonnet的性能略胜一筹,吊打GPT-4o等一众竞争对手的AI模型,且优于自家旗舰模型Claude 3 Opus。如今,Claude 3.5 Sonnet已经面向全球开启免费试用了。在费用上,So...
摘要:后端开发的疑惑后端开发最常面对的一个问题性能高并发等等。而到了时代,在方面有了前后端分离概念移动后端更是无力渲染天然前后端分离。 先来上一张前端页面的效果图(Vue + Vux + Vuex + Vue-Router)。showImg(https://segmentfault.com/img/remote/1460000010207850); 第一次做gif 没什么经验,太大了。加载...

阅读 1556·2021-10-14 09:43
阅读 1527·2021-10-09 09:58
阅读 2020·2021-09-28 09:42
阅读 3816·2021-09-26 09:55
阅读 1830·2021-08-27 16:23
阅读 2835·2021-08-23 09:46
阅读 963·2019-08-30 15:55
阅读 1581·2019-08-30 15:54





