
摘要:近十年监控系统开发经验,具有构建基于大数据平台的海量高可用分布式监控系统研发经验。监控多维数据特点监控的核心是对监控对象的指标采集处理检测和分析。通过单一对象的指标反映的状态已不能满足业务监控需求。
吴树生:腾讯高级工程师,负责SNG大数据监控平台建设。近十年监控系统开发经验,具有构建基于大数据平台的海量高可用分布式监控系统研发经验。
前言
在2015年构建多维监控平台时用kmeans做了异常点多维根因分析的尝试,后因种种原因而搁置了深入研究。虽中止了两年,但一直未忘当初的梦想。随着掀起AI浪潮,平台和技术也已成熟,监控团队历经两个月的重新调研和预研后取得突破,另辟蹊径地找到异常点的多维根因分析方法,我们称为MDRCA(Multi-Dimensional Root Cause Analysis)算法。
这篇文章为持续两年多的梦画上一个句号,它是监控团队第一代成果总结:介绍监控多维数据特点、基于kmeans多维根因分析方法、第一代MDRCA算法和AI在监控领域应用经验。笔者不敢贪功,仅将成果描述出来,如有偏差不全之处还望与读者多交流修正。
监控多维数据特点
监控的核心是对监控对象的指标采集、处理、检测和分析。传统监控的对象是一个单一的实体,例如服务器、路由器、交换机等。这些单一对象通过指标反映运行状态,例如服务器的状态指标有CPU使用率、内存使用大小、磁盘IO和网卡流量等。
传统监控系统通过定时任务采集这些监控对象的指标数据,经过校正后存储起来用于展示和异常检测。异常检测通过判断指标是否偏离设置的阈值来标识异常事件。
在传统监控之后,将监控对象扩展为一个虚拟的业务功能或业务模块,这时的对象仍是单一的,可用一个ID表达。对象的指标也相应的转变为反映业务功能状态的指标,例如接口调用次数、http返回200次数、http返回500次数等。
这些指标数据通常需要在应用程序埋点上报。数据处理、存储和异常检测与传统监控一致。
随着业务扩展,业务模块间的关系愈加复杂。通过单一对象的指标反映的状态已不能满足业务监控需求。业务异常往往体现在多个对象的指标异常,用户收到告警后需要在大量指标数据中剥丝抽茧般地分析异常原因。
这个状况伴生了运维痛点:一是告警量大;二是分析耗时长。
解决这一问题的关键是建立对象和指标的关联模型。通过相关性收敛对象和指标,减少告警量。并通过关联模型中的调用关系模型和层次关系模型快速找到问题根因。对传统监控中的对象翻译为多维度属性后对指标数据进行处理、存储和异常检测,形成多维监控。对象的维度属性将对象分类,构建了对象的关联模型。
这样对单一对象的异常检测可提炼为对某一维度属性的异常检测,从而减少检测对象。在发生异常后根据维度下钻分析,有规则地提供分析路径,避免盲目分析,减少分析耗时。
用A、B和C这三个业务模块来说明上面介绍的多维监控形成过程:
这三个模块的调用关系为A调用B,B调用C。C根据机房划分为C1和C2两个子模块。A模块下有2台机器(10.0.1.1和10.0.1.2),B下有3台机器(10.0.2.1、10.0.2.2和10.0.2.3),C1下有1台机器(10.0.3.11),C2下有2台机器(10.0.3.21和10.0.3.22)。
假设C模块下的机器负载已饱和,也就是说如果其中有一台机器异常,则提供有损服务,影响B和A的成功率。如果C2模块下的10.0.3.21机器异常,则会触发10.0.3.21机器告警及A和B下的5台机器告警,总共有6个对象产生告警。
在实际运营中,往往有多个指标反映一个功能状态,进一步增加告警量。
为解决例子描述的告警量大和分析耗时痛点,将监控对象的机器翻译成业务模块,从而形成一个业务模块和机器的多维度数据。异常检测也由机器维度更改为业务模块维度,减少检测对象的数量。在分析异常时,沿着业务模块到机器的层级关系可查找出异常点。
还有一种多维数据的场景是面向APP应用。APP的请求自身带有版本、机型、运营商和地域这些维度信息。发现指标异常后需要判断是哪个维度特性造成的异常或异常影响的维度范围。
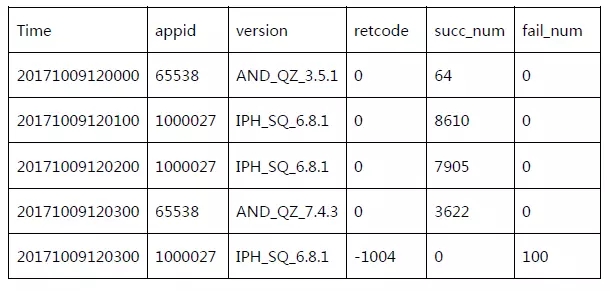
监控多维数据由三部分组成:
时间维度,监控系统时间粒度通常取1分钟粒度;
业务特性维度,后端服务的维度通常为业务模块,APP监控的维度通常为版本、机型、运营商和地域;
指标,如成功率,耗时和延时分段统计等。
下表是一个SNG移动监控的多维数据样例:
基于Kmeans分类的多维根因分析方法
在建设多维监控平台初期,为解决人工逐个观察各维度的异常数据带来的效率问题,使用kmeans对成功率指标分类。推荐出分类后的异常维度后再做二次分析。
下图是2014年12月手Q接入层SSO模块的成功率分钟曲线。当天中午13:00附近接入层成功率由接近99.9%下降为99.5%。

发生异常后,通过人工分析的步骤为分别查看某一维度的成功率,找出成功率低并且总量大的维度条件。选定最可疑的维度条件再重复刚刚介绍的分析过程。直到遍历完所有维度,找出成功率下降的维度组合。
例如:模块维度有A、B和C三个模块,A模块下有命令字(a1,a2和a3),B模块下有命令字(b1,b2),C模块下有命令字(c1,c2和c3)。在异常点的指标统计如下表:

按模块观察,模块A的成功率为99.75%,总数为300;模块B的成功率为95.83%,总数为150;模块C的成功率为99.4%,总数为300。
经过比较,模块B成功率显著低于模块A和模块C,并且接近95%。模块B成为可以维度条件。
接着观察模块B条件下的命令字,其中命令字b1的成功率显著低于异常点平均成功率95%。
分析完成后确定模块B的命令字b1造成成功率下降。
使用kmeans对成功率分类模拟人工分类操作。对各维度的成功率进行分类后可以得到显著差异的维度条件。
如对上面例子的各模块成功率做kmeans分类,可以获得成功率有显著差异的模块B和命令字b1。称具有显著差异的维度集合为反向分析。反向分析结果在二次分析时需要特别关注。
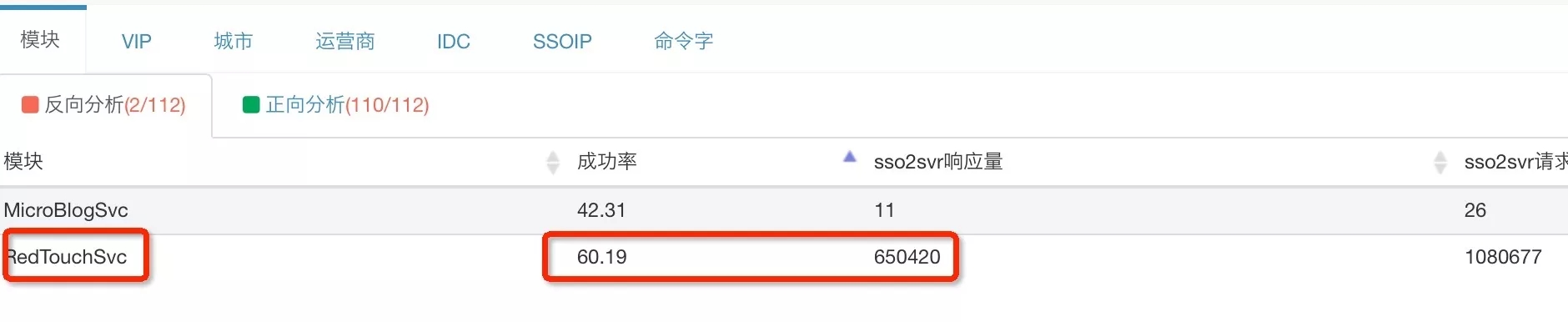
下面两张图是对手 Q 接入层异常模块分析的反向分析结果, 结合接入层的响应量判断出异常模块的RedTouchSvc,异常命令字为RedTouchSvc.ClientReport。
MDRCA(Multi-Dimensional Root Cause Analysis)算法
基于Kmeans对成功率分析方法在一定程度上提升了问题分析效率,但存在两个问题:
只能应用于成功率的指标分析,对于累积量的指标如请求量则失去作用;
未引入成功率总量的权重,分类后推荐出的异常维度条件需要二次人工分析。
中断近两年,并在建设完成多维监控平后,监控团队重新投入人力调研实现多维根因分析方法。在监控领域AI刚刚起步,可参考的论文和经验较少。我们在走了一段弯路后,借鉴和改进广告推荐中的异常分析算法,实现MDRCA算法,解决Kmeans成功率分类方法的两个问题。
对于指标我们分两类:单一变量指标和复合指标。
单一变量指标:请求量、响应量等不依赖其他变量独立统计的指标。
复合指标:成功率这类需要通过两个或多个变量做除法计算的指标。
这里我们用单一变量指标请求量来说明MDRCA算法的原理。
假设一个业务的请求量X(m)的某一维度下有m个值,分解到各维度的请求量为(x1,x2,…,xn,n=m)。X(m)可用公式表示:
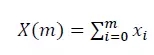
在异常时刻t 观察到异常的请求量为A(m)。A(m) 由各维度在t 时刻的值组成。A(m) 可用公式表示:
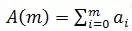
也就是说观察到的总体请求量异常由各维度的异常分量组成。
根据历史观察值获得时刻 t 的请求量预测值F(m)。F(m)由各维度的预测值组成。F(m) 可用公式表示:
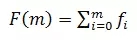
生成预测值算法有多种,一种方法是取前一天对于时刻 t 的值。在本文的 MDRCA 算法中,预测值取离前7天的 [t-20,t] 时刻的平均值最近的一天的 t 时刻作为参考点。
在MDRCA算法中定义一个值 Explanatory Power,简称EP来衡量观察维度 i 下维度值 j 对异常的占比,或称贡献度。EP的计算公式为:
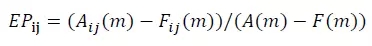
例如,异常时刻t的请求量为1000,根据历史数据预测时刻t的请求量为1500。维度 i 下的维度值 j 在异常时刻 t 的请求量值为200,根据j的历史数据预测时刻 t 下 j 的请求量值应为500。根据公式计算可知j的EP值为(200-500)/(1000-1500)=0.6。
当维度下有值的变化方向与异常值变化方向相反时,EP取值为负数。这时其他维度值的EP取值也可能大于1。但是观察维度下所有维度值的EP和为1。
MDRCA算法中定义另一个值Surprise来衡量观察维度 i 下维度值 j 的变化差异。为计算JSD,先计算两个变量 p 和 q 。其中 p 为维度值 j 在预测值中的占比,q 为维度值 j 在异常值中的占比。p 和 q 的计算公式如下:
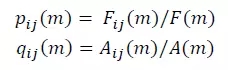
p 和 q 的取值为(0,1)。获得 p 和 q 后,维度值 j 的变化差异计算公式为:
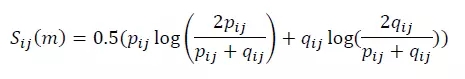
至此,我们获得衡量维度值 j 的异常贡献值 EP 和变化差异值 Surprise。对这两个值用四象限方法解释如下:
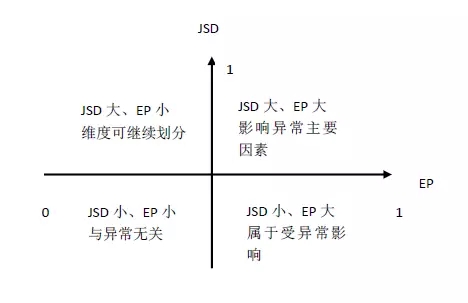
从四象限中可知,维度中 EP 和 Surprise 分类大的维度值可作为候选维度。对 EP 和Surprise 分类可采用前面介绍的 kmeans 分类方法。
选出每个维度下的候选维度集合后,计算各集合的 Surprise 和用于衡量各维度的异常变化差异。差异越大的维度越有可能成为异常的主要影响因素。
在这还用了另一个技巧: 异常的主要影响因素往往是少量维度值的集合。所以取后续集合的 Surprise均值大的维度作为优先选择的条件。选出维度后,在选择维度中贡献大的维度值作为优先条件。
MDRCA算法的多维根因分析方法如下:

以上为对单一变量的MDRCA算法介绍。对成功率这类复合指标EP计算为求分子分母两个变量的偏导,Surprise的计算方法为求分子和分母变量的Surprise值之和。
AI应用经验
为借助AI的东风解决监控领域的痛点,同时摸索AI在监控的实践经验。我们拿智能多维分析探路。中间经历曲折踩坑,反思当中的过程有几点经验值得在后续开发过程中借鉴。
其一,梳理AI应用开发过程的角色。
新近的互联网浪潮AI,必然吸引不少新老程序员踏浪,如何才能在浪中不翻船呢?
经过摸索后,我们认为在AI应用开发中需要以下四类角色:
领域专家
深入了解业务的领域专家能把握住该业务的核心痛点,结合AI找出着力点和给AI专家提供业务领域信息;
AI专家
这个角色知识渊博、深入掌握算法和实践。理解领域专家提供的痛点信息后,预研并提供算法指导和支撑。
算法工程化专家
这个角色拿到AI专家提供的算法后做工程化实现和优化提升算法性能。
应用开发专家
这类角色是将AI成果上线应用,提升易用性和用户体验,同时在应用中预设收集用户操作和反馈信息的渠道。
其二,先调研、读论文和参考业界做法的研究步骤。
读论文很重要。领域专家梳理出核心痛点,业界也存在类似痛点,并且有相关研究。不妨先参考业界做法,读懂和理解相关论文和应用场景后再做改进。
其三,沟通交流。
在监控领域AI应用刚刚起步,大家还在摸着石头过河,可参考的成功案例较少。所谓三个臭皮匠抵过一个诸葛亮,聚在一起学习交流,有利于纠正错误认识,明晰算法应用场景和扩展思路。
参考资料:
[1] Adtributor: Revenue Debugging in Advertising Systems
Ranjita Bhagwan,Rahul Kumar,Ramachandran Ramjee, George Varghese,Surjyakanta Mohapatra, Hemanth Manoharan, and Piyush Shah, Microsoft, 2014
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3958.html
摘要:近十年监控系统开发经验,具有构建基于大数据平台的海量高可用分布式监控系统研发经验。的哈勃多维监控平台在完成大数据架构改造后,尝试引入能力,多维根因分析是其中一试点,用于摸索的应用经验。 作者丨吴树生:腾讯高级工程师,负责SNG大数据监控平台建设。近十年监控系统开发经验,具有构建基于大数据平台的海量高可用分布式监控系统研发经验。 导语:监控数据多维化后,带来新的应用场景。SNG的哈勃多...
摘要:从那个时候开始,我就开始用一些机器学习人工智能的技术来解决的运维问题了,有不少智能运维的尝试,并发表了不少先关论文和专利。而处理海量高速多样的数据并产生高价值,正是机器学习的专长。也就是说,采用机器学习技术是运维的一个必然的走向。 大家上午好,非常荣幸,能有这个机会,跟这么多的运维人一起交流智能运维。最近这两年运维里面有一个很火的一个词叫做AIOps(智能运维)。我本人是老运维了,在2000...
摘要:本文将介绍美团点评整个数据库平台的演进历史,以及我们当前的情况和面临的一些挑战,最后分享一下我们从自动化到智能化运维过渡时,所进行的思考探索与实践。 从自动化到智能化运维过渡时,美团DBA团队进行了哪些思考、探索与实践?本文根据赵应钢在第九届中国数据库技术大会上的演讲内容整理而成,部分内容有更新。 背景 近些年,传统的数据库运维方式已经越来越难于满足业务方对数据库的稳定性、可用性、灵活...
摘要:本文将介绍美团点评整个数据库平台的演进历史,以及我们当前的情况和面临的一些挑战,最后分享一下我们从自动化到智能化运维过渡时,所进行的思考探索与实践。 从自动化到智能化运维过渡时,美团DBA团队进行了哪些思考、探索与实践?本文根据赵应钢在第九届中国数据库技术大会上的演讲内容整理而成,部分内容有更新。 背景 近些年,传统的数据库运维方式已经越来越难于满足业务方对数据库的稳定性、可用性、灵活...

阅读 2559·2021-08-11 11:16
阅读 2983·2019-08-30 15:55
阅读 3391·2019-08-30 12:53
阅读 1626·2019-08-29 13:28
阅读 3315·2019-08-28 18:17
阅读 995·2019-08-26 12:19
阅读 2510·2019-08-23 18:27
阅读 759·2019-08-23 18:17





