
摘要:而硬盘失效预测技术,很大程度上可把这种非计划性工作变为计划性工作,从而降低客户的运维成本。硬盘分为和两大类,其失效预测技术也不同。在硬盘失效预测领域,我们用召回率和虚警率来衡量预测算法的结果。
背景
硬盘是存储系统的最重要组件,其可靠性状况在很大程度上影响了存储系统的整体可靠性表现。虽然存储系统使用了多种技术来处理硬盘失效,确保一定程度的硬盘失效不影响数据可靠性。但在实际生产环境中,多种因素(如腐蚀、震动或硬盘批次缺陷等)仍可能导致双盘甚至多盘同时或在短时间内相继失效,影响用户数据安全。显而易见,如果能预测硬盘失效的概率,并做提前预防,可大大提升用户数据的可靠性。
同时,当硬盘失效后,运维人员需要尽快执行数据备份和换盘等操作。通常而言,这些操作属于非计划性工作,会显著增加数据中心运维人员的工作负担。而硬盘失效预测技术,很大程度上可把这种非计划性工作变为计划性工作,从而降低客户的运维成本。
硬盘分为SSD和HDD两大类,其失效预测技术也不同。SSD可通过擦写次数进行寿命预估,实现难度相对不高。而HDD的机械器件众多,系统精密度高,其失效模型非常复杂,我们很难用简单的算法预测其失效概率。随着人工智能技术的成熟,如何利用机器学习等技术对HDD进行失效预测,是存储阵列可靠性领域的一个重要创新方向。
预测算法的衡量指标
在进入算法设计前,我们需要首先定义一个算法的衡量指标。在硬盘失效预测领域,我们用召回率(Recall)和虚警率(FAR:False Alarm Rate)来衡量预测算法的结果。其中,召回率是指算法识别出的失效硬盘占所有失效硬盘的百分比;而虚警率指失效预测算法识别出错的百分比。显而易见,过低的虚警率(当我们把判定失效硬盘的条件设置得很严格时)将导致召回率降低(从而影响预测算法的有效性);而高的虚警率,将导致召回率的错误增高(从另一方面也影响算法的有效性)。
一个好的算法,需要在召回率和虚警率之间做取舍。当不同的厂商或者用户有不同的倾向时,预测模型的选择也会有较大的差别。基于多年的存储行业经验,我们定义了如下标准:就多数用户的使用场景而言,我们需要使得预测模型在虚警率尽量低(小于0.5%)的情况下召回率大于等于70%。
SATAHDD失效预测的实现原理
定义了硬盘失效预测的衡量指标后,可以真正讨论一下如何找到满足指标的预测模型。以SATA盘为例,其生产厂商会提供SMART (Self-Monitoring Analysisand Reporting Technology)信息,这些信息可以表征硬盘的运行状态:如SMART 187反映了不能用ECC(Error-correcting code)纠正的读请求计数,当这个值大于0时,硬盘则有可能出现了问题,需要更换。其它的SMART特征,如SMART 5(重分配扇区计数)、SMART 188(命令超时)等也都是表征硬盘可能失效的重要指标[1]。在[2]中展示了SMART 187与硬盘失效率的一张关系图(该图源自于Backblaze),如下所示。
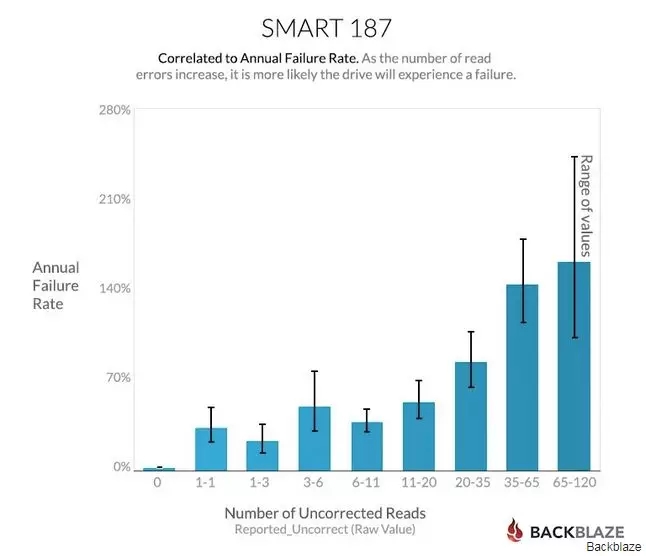
SMART 187指标与硬盘年失效率(AFR)的关系
可以看出,SMART 187确实在很大程度上与硬盘失效成相关性,当SMART 187高于35时,硬盘失效率上涨很多。所以,有理由相信,通过分析和利用硬盘的SMART数据,我们有可能训练出满足评价指标的SATA HDD失效预测模型。
如何训练模型?
虽然SMART 5 和 SMART 187等指标对于SATA HDD的失效预测非常重要,但是基于HDD失效模式的复杂度,仅仅用这几个指标(机器学习中称为特征-Feature)训练的模型是不能够满足要求的,所以我们需要选取尽可能多的特征来训练模型。但由于维度诅咒(Curse of Dimensionality,指选择的特征过多反而会导致模型失效),我们不可能将所有的SMART特征值都作为模型输入来训练模型,特别是SMART特征值中包括原始值和归一化值等不同纬度的特征时。
另外,SMART属性中并不是所有值都与硬盘失效有关,甚至有些值与硬盘失效的关系跟人们的预计并不相符,例如下图:

SMART 12与硬盘年失效率的关系
该图仍来自[2],其中SMART 12代表硬盘上电次数,与直觉相反的是,它的值与硬盘失效率并没有正相关性。因为SMART 12非常大的时候,硬盘失效率反而下降了。
所以,如何合理选择合理的特征,并且有可能对这些特征进行组合、转换等操作生成新的特征以满足模型训练的要求,这是硬盘失效预测模型训练的关键。下图展示了当特征选择不恰当时模型的输出结果。可以看出在FAR为0.5%时,Recall只有不到0.5,效果不甚理想:
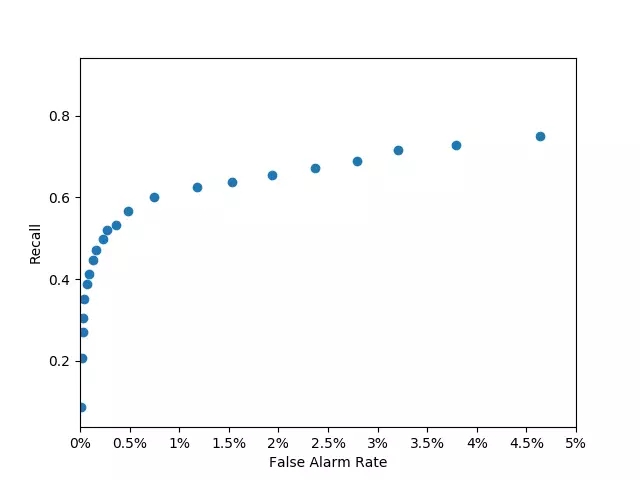
一个特征选择不恰当的模型训练结果
在华为存储实验室中,我们通过收集华为数据中心的大量硬盘信息,合理选择了特征和算法,得到了如下模型的训练结果,可以看到,其效果已满足我们对预测算法的目标要求:
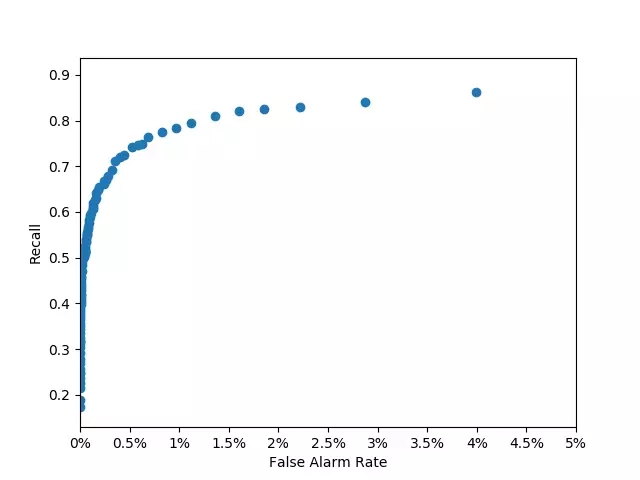
存储实验室开发的硬盘失效预测模型效果
SAS HDD的失效预测
上文解释了SATA HDD失效预测的原理,更进一步的,我们还需要考虑如何预测SAS HDD的失效。SAS HDD的失效预测不能采用与SATA HDD相同的模型,除了在生产制造工艺等方面的不同外,一个主要原因是SAS接口并不能提供像SMART一样的硬盘状态特征。SAS HDD提供了所谓的SCSI Log Page,提供了诸如grown defect list、non-medium error、unrecovered read error、unrecovered write error和unrecovered verified error等信息,而这些信息很多是硬盘厂商检查硬盘状态后自己定义的结果。在模型训练过程中,我们发现这些值并不足以支撑足够好的预测模型。因此,在SAS HDD的失效预测中,需要加入更详细的诊断信息(如希捷的FARM:Field-Accessible Reliability Metrics Specification),以提供在SAS Log Page里缺失却比较重要的硬盘特征,如SMART 7、SMART 188等等。因此在SAS HDD的失效预测中需要同时使用Log Page与FARM信息作为输入数据特征。
华为eService系统的云端硬盘失效预测能力
可以看出,正确的选择数据特征,使用合适的分类算法,合理的调节模型参数是一个成功的失效预测模型的关键。事实上,基于华为数据中心的海量机械盘数据,华为存储的云端智能运维系统- eService已经训练出HDD失效预测模型,并可以在近期提供云端的HDD失效预测能力。当客户数据中心硬盘状态数据接入eService系统,该系统会根据已有模型实时预测硬盘失效状态并及时提醒客户更换即将失效的硬盘,从而大幅提升客户数据可靠性,降低运维成本。
未来展望
虽然eService系统已经提供HDD的失效预测的能力,但是这仅仅是开始。随着接入eService的设备数量的上升,通过不断优化的训练过程,我们可以预期这个能力的较精确度会不断提升,给用户带来更大的价值。
参考资料
[1]https://www.pcworld.com/article/3129275/hardware/these-5-smart-errors-help-you-predict-your-hard-drives-death.html
[2]https://www.computerworld.com/article/2846009/the-5-smart-stats-that-actually-predict-hard-drive-failure.html
欢迎加入本站公开兴趣群软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3956.html
摘要:从那个时候开始,我就开始用一些机器学习人工智能的技术来解决的运维问题了,有不少智能运维的尝试,并发表了不少先关论文和专利。而处理海量高速多样的数据并产生高价值,正是机器学习的专长。也就是说,采用机器学习技术是运维的一个必然的走向。 大家上午好,非常荣幸,能有这个机会,跟这么多的运维人一起交流智能运维。最近这两年运维里面有一个很火的一个词叫做AIOps(智能运维)。我本人是老运维了,在2000...
摘要:一大数据平台介绍大数据平台架构演变如图所示魅族大数据平台架构演变历程年底,我们开始实践大数据,并部署了测试集群。因此,大数据运维的目标是以解决运维复杂度的自动化为首要目标。大数据运维存在的问题大数据运维存在的问题包括部署及运维复杂。 一、大数据平台介绍 1.1大数据平台架构演变 showImg(https://segmentfault.com/img/bVWDPj?w=1024&h=...

阅读 1548·2021-09-30 09:57
阅读 1548·2021-09-09 09:33
阅读 2343·2021-09-04 16:40
阅读 1904·2021-09-01 10:50
阅读 3304·2021-09-01 10:31
阅读 2597·2019-08-30 15:56
阅读 3023·2019-08-30 15:44
阅读 3527·2019-08-29 17:29



