
摘要:开源即时网络爬虫项目将与基于的异步网络框架集成,所以本例将使用采集淘宝这种含有大量代码的网页数据,但是要注意本例一个严重缺陷用加载网页的过程发生在中,破坏了的架构原则。
1,引言
本文讲解怎样用Python驱动Firefox浏览器写一个简易的网页数据采集器。开源Python即时网络爬虫项目将与Scrapy(基于twisted的异步网络框架)集成,所以本例将使用Scrapy采集淘宝这种含有大量ajax代码的网页数据,但是要注意本例一个严重缺陷:用Selenium加载网页的过程发生在Spider中,破坏了Scrapy的架构原则。所以,本例只是为了测试Firefox驱动和ajax网页数据采集这两个技术点,用于正式运行环境中必须予以修改,后续的文章将专门讲解修正后的实现。
请注意,本例用到的xslt文件是通过MS谋数台保存提取器后,通过API接口获得,一方面让python代码变得简洁,另一方面,节省调试采集规则的时间。详细操作请查看Python即时网络爬虫:API说明
2,具体实现
2.1,环境准备
需要执行以下步骤,准备Python开发和运行环境:
安装Python--官网下载安装并部署好环境变量 (本文使用Python版本为3.5.1)
安装lxml-- 官网库下载对应版本的.whl文件,然后命令行界面执行 "pip install .whl文件路径"
安装Scrapy--命令行界面执行 "pip install Scrapy",详细请参考Scrapy:Python3下的第一次运行测试
安装selenium--命令行界面执行 "pip install selenium"
安装Firefox--官网下载安装
上述步骤展示了两种安装:1,安装下载到本地的wheel包;2,用Python安装管理器执行远程下载和安装。
2.2,开发和测试过程
以下代码默认都是在命令行界面执行
1),创建scrapy爬虫项目simpleSpider
E:python-3.5.1>scrapy startproject simpleSpider
2),修改settings.py配置
有些网站会在根目录下放置一个名字为robots.txt的文件,里面声明了此网站希望爬虫遵守的规范,Scrapy默认遵守这个文件制定的规范,即ROBOTSTXT_OBEY默认值为True。在这里需要修改ROBOTSTXT_OBEY的值,找到E:python-3.5.1simpleSpidersimpleSpider下文件settings.py,更改ROBOTSTXT_OBEY的值为False。
3),导入API模块
在项目目录E:python-3.5.1simpleSpider下创建文件gooseeker.py(也可以在开源Python即时网络爬虫GitHub源 的core文件夹中直接下载),代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
# 模块名: gooseeker
# 类名: GsExtractor
# Version: 2.0
# 说明: html内容提取器
# 功能: 使用xslt作为模板,快速提取HTML DOM中的内容。
# released by 集搜客(http://www.gooseeker.com) on May 18, 2016
# github: https://github.com/FullerHua/jisou/core/gooseeker.py
from urllib import request
from urllib.parse import quote
from lxml import etree
import time
class GsExtractor(object):
def _init_(self):
self.xslt = ""
# 从文件读取xslt
def setXsltFromFile(self , xsltFilePath):
file = open(xsltFilePath , "r" , encoding="UTF-8")
try:
self.xslt = file.read()
finally:
file.close()
# 从字符串获得xslt
def setXsltFromMem(self , xsltStr):
self.xslt = xsltStr
# 通过GooSeeker API接口获得xslt
def setXsltFromAPI(self , APIKey , theme, middle=None, bname=None):
apiurl = "http://www.gooseeker.com/api/getextractor?key="+ APIKey +"&theme="+quote(theme)
if (middle):
apiurl = apiurl + "&middle="+quote(middle)
if (bname):
apiurl = apiurl + "&bname="+quote(bname)
apiconn = request.urlopen(apiurl)
self.xslt = apiconn.read()
# 返回当前xslt
def getXslt(self):
return self.xslt
# 提取方法,入参是一个HTML DOM对象,返回是提取结果
def extract(self , html):
xslt_root = etree.XML(self.xslt)
transform = etree.XSLT(xslt_root)
result_tree = transform(html)
return result_tree
4),创建SimpleSpider爬虫类
在项目目录E:python-3.5.1simpleSpidersimpleSpiderspiders下创建文件simplespider.py,代码如下:
# -*- coding: utf-8 -*-
import time
import scrapy
from lxml import etree
from selenium import webdriver
from gooseeker import GsExtractor
class SimpleSpider(scrapy.Spider):
name = "simplespider"
allowed_domains = ["taobao.com"]
start_urls = [
"https://item.taobao.com/item.htm?spm=a230r.1.14.197.e2vSMY&id=44543058134&ns=1&abbucket=10"
]
def __init__(self):
# use any browser you wish
self.browser = webdriver.Firefox()
def getTime(self):
# 获得当前时间戳
current_time = str(time.time())
m = current_time.find(".")
current_time = current_time[0:m]
return current_time
def parse(self, response):
print("start...")
#start browser
self.browser.get(response.url)
#loading time interval
time.sleep(3)
#get xslt
extra = GsExtractor()
extra.setXsltFromAPI("API KEY" , "淘宝天猫_商品详情30474")
# get doc
html = self.browser.execute_script("return document.documentElement.outerHTML");
doc = etree.HTML(html)
result = extra.extract(doc)
# out file
file_name = "F:/temp/淘宝天猫_商品详情30474_" + self.getTime() + ".xml"
open(file_name,"wb").write(result)
self.browser.close()
print("end")
5),启动爬虫
在E:python-3.5.1simpleSpider项目目录下执行命令
E:python-3.5.1simpleSpider>scrapy crawl simplespider
6),输出文件
采集到的网页数据结果文件是:淘宝天猫_商品详情30474_1466064544.xml
3,展望
调用Firefox,IE等全特性浏览器显得有点太重量级,很多场合可以考虑轻量级的浏览器内核,比如,casperjs和phantomjs等。同时运行在没有界面的浏览器(headless browser,无头浏览器)模式下,也许可以对网页数据采集性能有所提升。
然后,最重要的一点是要写一个 Scrapy 的下载器,专门驱动这些浏览器采集网页数据,也就是把这个功能从Spider中迁移出来,这样才符合Scrapy的整体框架原则,实现事件驱动的工作模式。
4,相关文档
1, Python即时网络爬虫:API说明
2, API例子:用Java/JavaScript下载内容提取器
5,集搜客GooSeeker开源代码下载源
1, 开源Python即时网络爬虫GitHub源
6,文档修改历史
1,2016-06-28:V1.0
2,2016-06-28:V1.1,在第一段明显位置注明本案例的缺陷
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/38024.html
摘要:也就是用可视化的集搜客爬虫软件针对亚马逊图书商品页做一个采集规则,并结合规则提取器抓取网页内容。安装集搜客爬虫软件前期准备进入集搜客官网产品页面,下载对应版本。 showImg(https://segmentfault.com/img/bVEFvL?w=300&h=300); 1. 引言 前面文章的测试案例都用到了集搜客Gooseeker提供的规则提取器,在网页抓取工作中,调试正则表达...
摘要:爬取网易云音乐的歌单。打开歌单的,然后用提取播放数。值得强调的是,不要将动态网页和页面内容是否有动感混为一谈。它会把网站加载到内存并执行页面上的,但是它不会向用户展示网页的图形界面。 爬取网易云音乐的歌单。 打开歌单的url: http://music.163.com/#/discov...,然后用lxml.html提取播放数3715。结果表明,我们什么也没提取到。难道我们打开了一个假...
摘要:上一篇文章网络爬虫实战请求库安装下一篇文章网络爬虫实战解析库的安装的安装在上一节我们了解了的配置方法,配置完成之后我们便可以用来驱动浏览器来做相应网页的抓取。上一篇文章网络爬虫实战请求库安装下一篇文章网络爬虫实战解析库的安装 上一篇文章:Python3网络爬虫实战---1、请求库安装:Requests、Selenium、ChromeDriver下一篇文章:Python3网络爬虫实战--...
摘要:自动化测试工具可能是网页应用中最流行的开源自动化测试框架。证书商业是一个开源的自动化测试框架,它实现了关键字测试驱动来实现测试驱动开发。 showImg(https://segmentfault.com/img/bVYz7D?w=1200&h=627); 简评:软件开发实践一直以来都在变化,工具和技术也是如此。这些改变都是为了提高生产率,质量,让客户满意,缩短交付时间,以及交付成功的产...
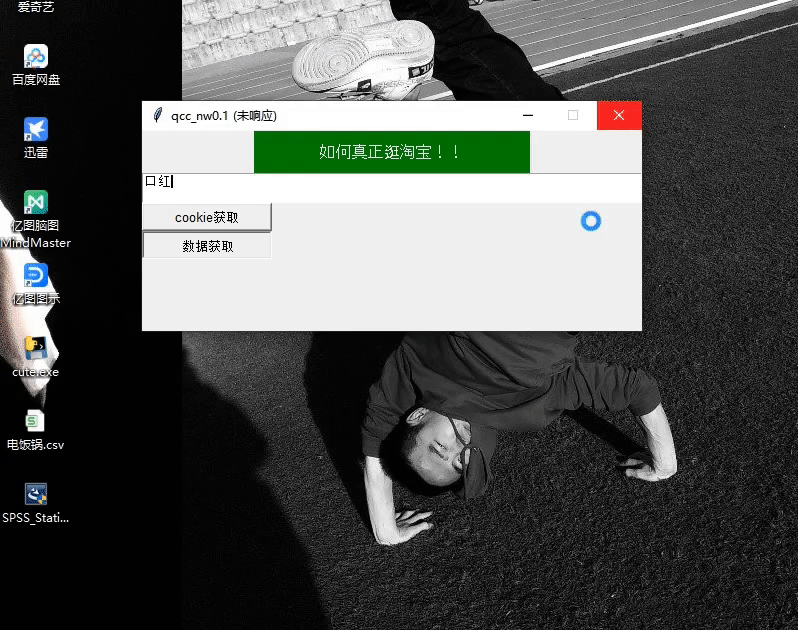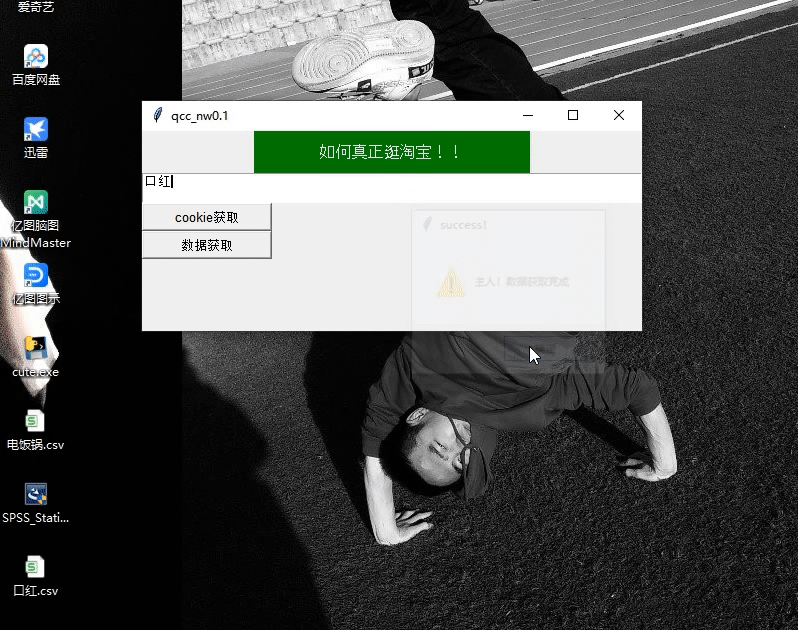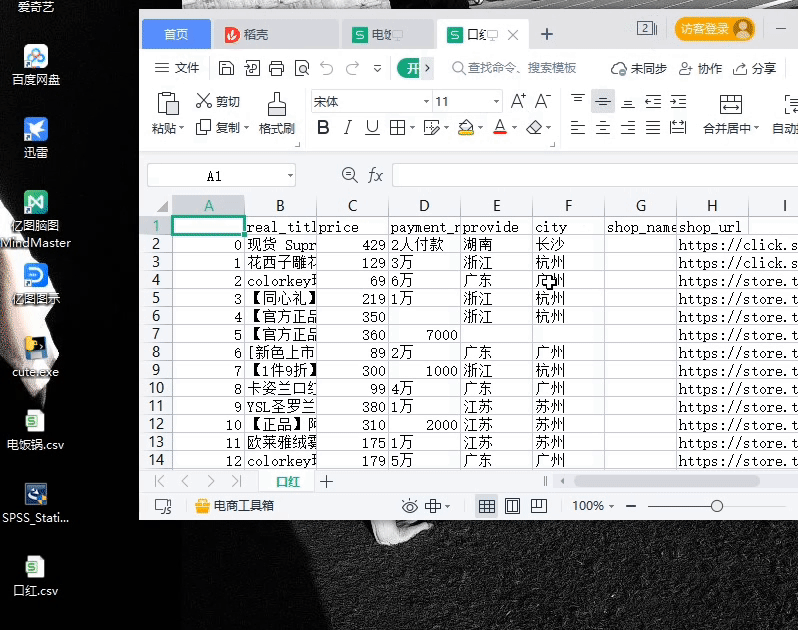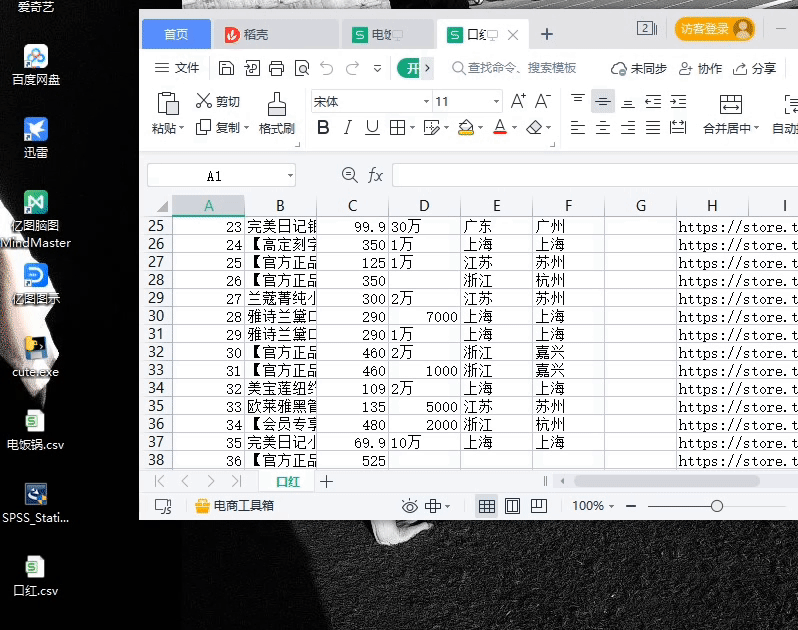
摘要:完整代码火狐浏览器驱动下载链接提取码双十一刚过,想着某宝的信息看起来有些少很难做出购买决定。完整代码&火狐浏览器驱动下载链接:https://pan.baidu.com/s/1pc8HnHNY8BvZLvNOdHwHBw 提取码:4c08双十一刚过,想着某宝的信息看起来有些少很难做出购买决定。于是就有了下面的设计:既然有了想法那就赶紧说干就干趁着双十二还没到一、准备工作:安装 :selen...

阅读 1903·2023-04-26 00:20
阅读 1922·2021-11-08 13:21
阅读 2223·2021-09-10 10:51
阅读 1747·2021-09-10 10:50
阅读 3418·2019-08-30 15:54
阅读 2228·2019-08-30 14:22
阅读 1508·2019-08-29 16:10
阅读 3178·2019-08-26 11:50






