
摘要:与其它可用于的软件包一样,新的软件包亦可利用来加速各类机器学习与深度学习应用。数据科学家们必须首先构建起机器学习模型,确保其适合分布式计算特性,而后将其映射至深层神经网络当中,最终编写代码以为这套新模型提供支持。
今天,我们兴奋地宣布在Mesosphere DC/OS服务目录当中发布TensorFlow的beta测试版本。只需要一条命令,您现在即可将分布式TensorFlow部署在任意裸机、虚拟或者公有云基础设施当中。与其它可用于DC/OS的软件包一样,新的TensorFlow软件包亦可利用GPU来加速各类机器学习与深度学习应用。
在由深度学习技术掀起的新一轮军备竞赛当中,专注于尝试学习的数据科学家已经成为人才市场上的新宠。而有效的数据科学基础设施将帮助您吸引更多顶尖数据科学家,并获得由他们倾力构建起的工作成果,最终为您的企业带来远超竞争对手的战略优势。向DC/OS当中引入分布式TensorFlow的作法,也进一步巩固了Mesosphere长久以来作出的支持开发人员、运营人员以及数据科学家群体的承诺。
在今天的文章当中,我们将对TensorFlow作出简要介绍,探讨分布式设置场景下的TensorFlow运行挑战,同时聊聊我们的全新DC/OS TensorFlow软件包如何解决这些挑战。在DC/OS之上运行分布式TensorFlow——尽管目前尚处于beta测试阶段,已经足以为如今的市场上提供一套简单且易行的分布式TensorFlow运行体验。
TensorFlow快速介绍
TensorFlow是一套极具人气的开源库,由谷歌Brain团队所打造,专门面向机器学习类场景。事实上,TensorFlow为2015年GitHub上的头号fork项目,且在之后的两年当中一直雄踞fork活跃度榜前十位名次。TensorFlow的高人气主要源自其利用一套基于数据流图形的计算模型实现深层神经网络开发与训练简化的强大能力。
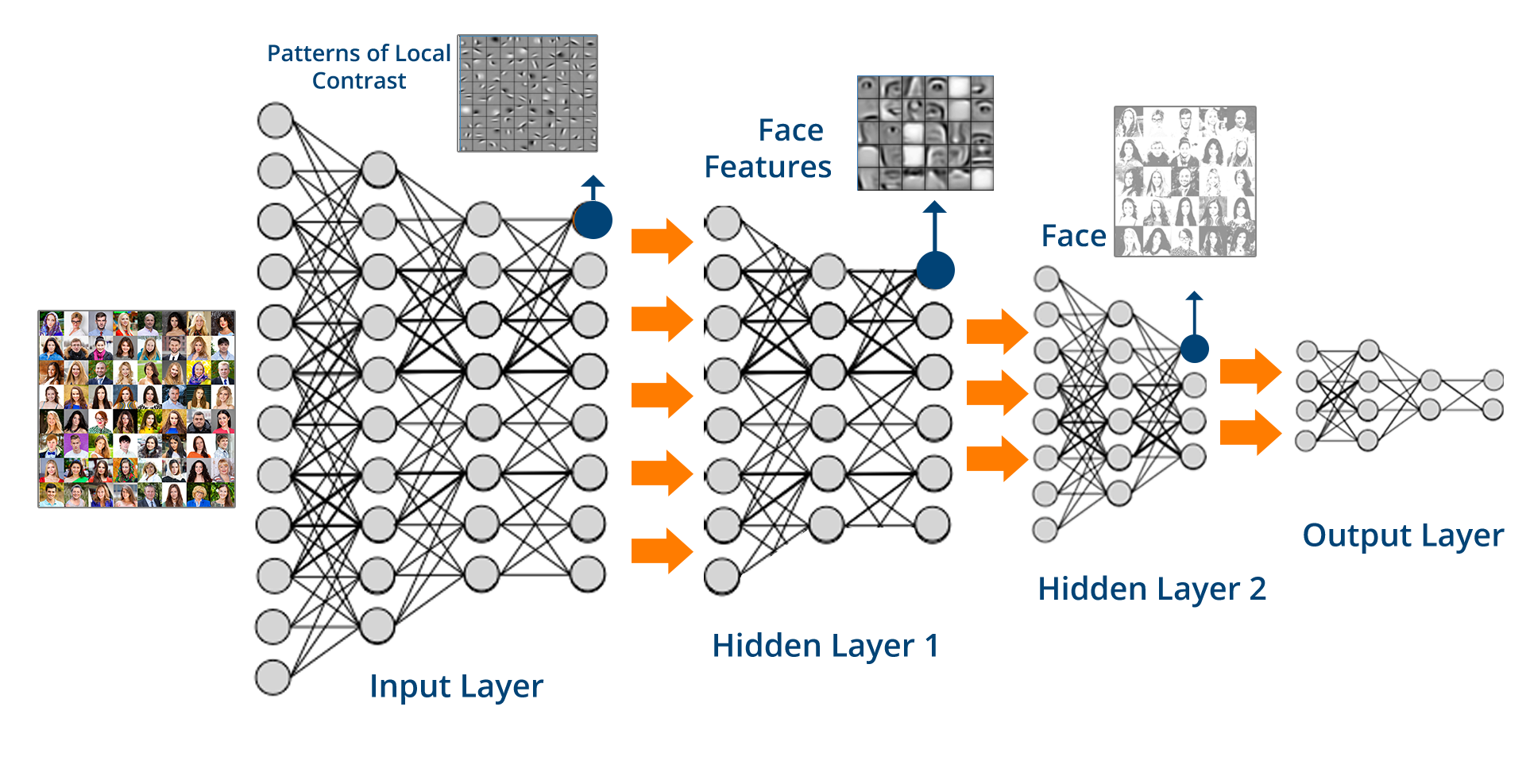
在以上示例当中,输入层负责寻找局部对比模式,隐藏层1负责利用这些对比结果发现个人面部特征,隐藏层2则基于这些面部特征进行整体面部识别。资料来源:https://www.edureka.co/blog/what-is-deep-learning。
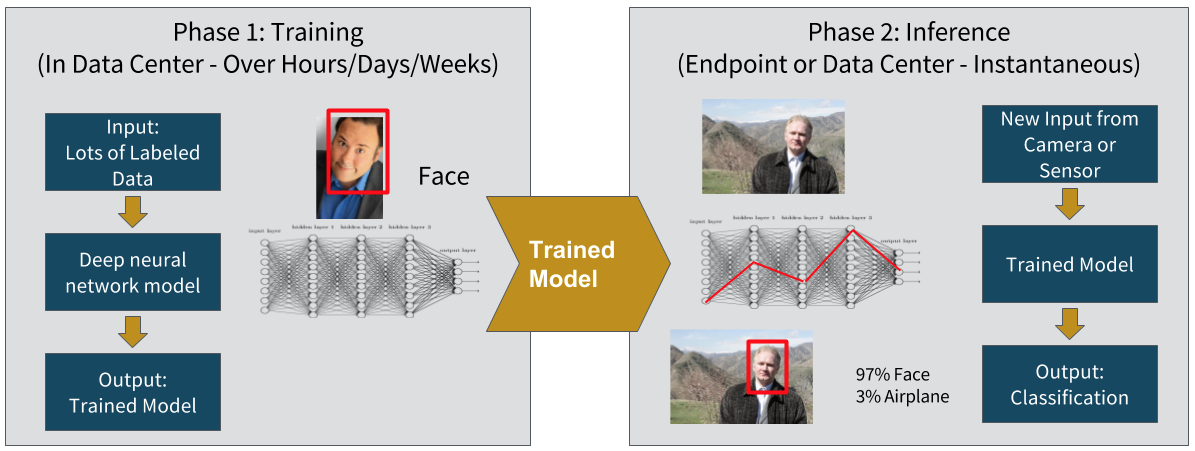
一般来讲,深层神经网络的生命周期需要经历两个不同的阶段:训练与推理。在我们的示例当中,训练阶段需要为神经网络提供成千上万图像,帮助其训练面部识别能力。这一训练过程可能需要数个小时、数天甚至数周时间才能完成,具体取决于数据集规模、模型复杂度以及硬件性能等各类因素。一旦训练工作完成,该神经网络即可用于“瞬时”识别图像中的面部要素。
下图所示为训练与推理过程的细节判断:
虽然TensorFlow适用于上述分类网络的设计与实现,但其强大的能力并不仅限于此。TensorFlow还能够在对象追踪(https://github.com/akosiorek/hart)、文本到语音生成(https://github.com/ibab/tensorflow-wavenet)甚至自动驾驶车辆(https://github.com/udacity/self-driving-car/)领域有所建树。
TensorFlow通过提供可直接集成至代码当中的基础机器学习原语以简化深层神经网络的开发工作。TensorFlow以库的形式提供此类原语,并将其绑定至多种高人气语言(例如C/C++、Go、Java以及Python等)当中。此外,TensorFlow还能够自动计算出运行代码的较佳处理单元(CPU、GPU或者TPU等)。
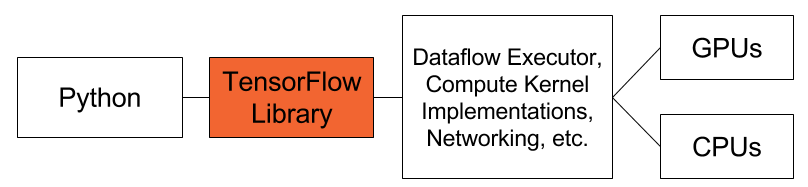
在Python当中开发TensorFlow应用程序,且此应用将CPU与GPU相结合以完成运行。
感兴趣的朋友可以点击https://www.tensorflow.org/get_started/mnist/mechanics参阅TensorFlow 101教程,从而了解更多与利用TensorFlow构建您首套神经网络相关的细节信息。
单节点对分布式TensorFlow
深度神经网络的设计与实现(即使是在TensorFlow的帮助之下)并非小事。数据科学家们必须首先构建起机器学习模型,确保其适合分布式计算特性,而后将其映射至深层神经网络当中,最终编写代码以为这套新模型提供支持。另外,他们还必须决定是否有必要以分布式方式定义并实现自己的深层神经网络,抑或直接将其设计为可在单一工作站之上运行。
为单节点计算设计深层神经网络在难度上往往远低于分布式计算场景,但前者在训练耗时方面则处于劣势。在另一方面,为分布式计算环境设计深层神经网络更加复杂,但却能够将工作负载分发至多台设备之上,从而将训练时长由原本的数个月缩短至数天甚至是数小时。
部署分布式TensorFlow的挑战所在
各类组织机构在部署分布式TensorFlow应用程序时,可通过在DC/OS上运行该服务的方式解决众多常见的挑战。
在TensorFlow当中运行分布式计算时,要求大家理解不同组件之间的复杂交互方式;其中Parameter Server负责将值交付至Worker处,而后者则负责执行具体计算;此外,Master则协调并同步以上一切分布式处理工作。
开发人员与数据科学家们承担着设计模型并编写适合的分布式TensorFlow应用程序,从而达成最终目标的艰巨任务——但这还仅仅只是开始。在实际集群部署工作当中,分布式TensorFlow代码的运行与维护如果缺少DC/OS的帮助,则将成为一项劳动密集型任务。
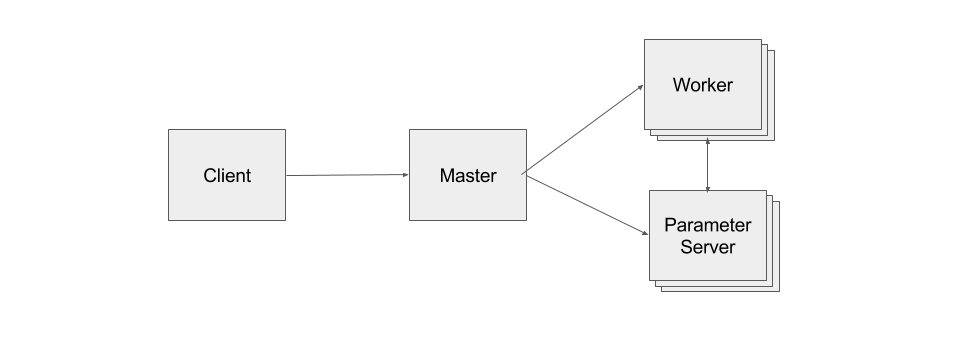
TensorFlow提供的原语有助于在大型设备集群之上进行工作负载分发。
开发人员的工作是为每套部署体系定义一个惟一的ClusterSpec,这些部署体系必须为不同的工作节点与参数服务器启动IP地址与端口列表。此后,开发人员必须手动配置各设备以确保其与ClusterSpec当中的定义内容保持一致;最终,代码才能被部署到这些设备上并开始运行。即使是在基于云的动态环境当中,ClusterSpec仍然必须在基础设施发生变化时进行手动更新。
然而,传统的TensorFlow实现方案会交ClusterSpec嵌入至深度学习模型代码当中。如此一来,管理人员必须熟知ClusterSpec的编辑周期并针对每个工作节点进行重启以逐一进行修改测试,方可实现操作参数的配置与微调。DC/OS则能够自动实现ClusterSpec更新,帮助数据科学团队摆脱这种枯燥且极易出错的负担。
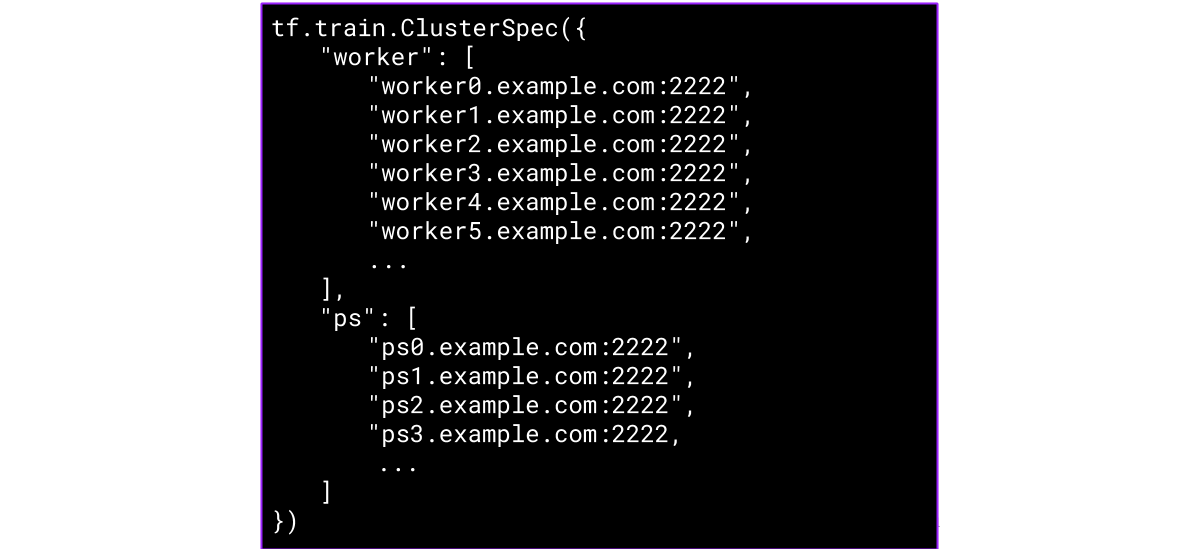
除此之外,分布式TensorFlow一旦发生故障,恢复工作也相当令人头痛。如果主节点或者任意参数服务器乃至工作节点因某种原因而无法工作,那么除了人为介入,再无其它办法令其恢复正常。DC/OS则能够自动完成这项任务,意味着管理人员不必反复对每台设备进行运行状态检查,从而确保分布式TensorFlow部署体系的正常工作。
在DC/OS上运行分布式TensorFlow的好处
DC/OS上发布的全新TensorFlow beta测试版本能够解决以上所有难题。具体来讲,其有助于:
简化分布式TensorFlow的部署:将分布式TensorFlow集群中的全部组件部署在任意基础设施之上——包括裸机、虚拟或者公有云——将变得异常简单,具体操作类似于将JSON文件传递至一条CLI命令。参数的更新与调整亦可轻松实现,意味着微调与优化不再令人困扰。
在不同团队间共享基础设施:DC/OS允许多个团队共享同一基础设施并启动多项不同TensorFlow任务,同时始终保持资源隔离。一旦TensorFlow任务完成,相关容量即被释放并可供其它团队使用。
在同一集群之上部署不同TensorFlow版本:与众多其它DC/OS服务一样,您同样可以在同一集群之上轻松部署同一服务的多个实例,并保证其采用不同的版本。这意味着当TensorFlow发布新版本时,您的一支团队可以使用其功能与特性,但又不必对其它团队的代码作出变更。
动态分配GPU资源:GPU能够显著提升深度学习模型的执行速度,特别是在训练阶段。然而,GPU是一种宝贵的资源,因为必须得到有效利用。由于DC/OS能够自动检测集群上的所有GPU,所以其将实现基于GPU的资源调度,允许TensorFlow基于各项任务请求全部或者部分GPU资源(类似于请求CPU、内存以及磁盘等其它常规资源)。一旦任务完成,GPU资源将被释放并可供其它任务使用。
专注于模型开发,而非部署:DC/OS 将模型开发从集群配置工作当中剥离出来,从而消除了以手动方式将ClusterSpec引入模型代码的难题。相反,用户在部署TensorFlow软件包时只需要指定其希望模型在运行中使用的各工作节点以及参数服务器属性,而后软件包自身会在部署时为此生成一个独特的ClusterSpec。从实现层面来讲,该软件包会找到一组作为各工作节点/参数服务器运行基础的设备,使用合适的值填充CLusterSpec,启动各参数服务器与工作节点任务,并传递其生成的ClusterSpec。开发人员只需要编写出需要填充的代码,该软件包即可自行完成剩余任务。
下图所示为一条JSON片段,其可用于将来自DC/OS CLI的TensorFlow软件包部署至一组CPU与GPU工作节点当中。

此命令将使用以上配置启动TensorFlow:
dcos package install beta-tensorflow --options=
该软件包亦可通过在UI中指定参数的方式立足DC/OS服务目录进行部署。
自动完成故障恢复:TensorFlow软件包利用DC/OS SDK编写而成,并使用了自动重启等内置弹性功能,因此能够顺利且高效地实现任务自我修复。
在运行时中安全部署任务配置参数:DC/OS秘密服务在运行时会为每个TensorFlow实例动态部署凭证与秘密配置选项。操作人员可以轻松添加凭证以访问秘密信息或者特定配置URL,从而确保其不会暴露在模型代码当中。
原文链接:https://mesosphere.com/blog/tensorflow-gpu-support-deep-learning/
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3522.html
摘要:与其它可用于的软件包一样,新的软件包亦可利用来加速各类机器学习与深度学习应用。数据科学家们必须首先构建起机器学习模型,确保其适合分布式计算特性,而后将其映射至深层神经网络当中,最终编写代码以为这套新模型提供支持。 今天,我们兴奋地宣布在Mesosphere DC/OS服务目录当中发布TensorFlow的beta测试版本。只需要一条命令,您现在即可将分布式TensorFlow部署在任意裸机、...
摘要:负责承载操作系统的分布式文件系统只需要使用必要的文件,而且事实上只需要下载并在本地缓存这部分必要数据。而第二项原则在于元数据即与文件存在相关的信息,而非文件内容被优先对待。这套镜像随后可进行任意分发,并被用于启动该项任务。 随着Docker技术的日渐火热,一些容器相关的问题也浮出水面。本文就容器数量激增后造成的分发效率低下问题进行了探讨,并提出了一种新的解决方法。发现问题,解决问题,正...
摘要:今天小数给大家带来一篇技术正能量满满的分享来自社区线上群分享的实录,分享嘉宾是数人云肖德时。第二级调度由被称作的组件组成。它们是最小的部署单元,由统一创建调度管理。 今天小数给大家带来一篇技术正能量满满的分享——来自KVM社区线上群分享的实录,分享嘉宾是数人云CTO肖德时。 嘉宾介绍: 肖德时,数人云CTO 十五年计算机行业从业经验,曾为红帽 Engineering Service ...
摘要:方案二和也运行在中。新增删除节点变更配置均需要手工介入。公司已有的大多都是容器形式部署在各个服务器上。目前我们在每个节点上部署了传统的。在接下来的阶段团队也会对此做进一步的探索。 回想起第一次接触Mesos, 当时有很多困惑: 这到底是用来做啥的?跟YARN比有什么优势?有哪些大公司在使用么?。 然而现在技术日新月异地发展, Mesos这个生态圈也开始被越来越多的团队熟悉关注, 像k8...
摘要:在这一假设之下,是一个新奇的观点编排才是容器生态的中心,而引擎就我们所知,只是一个开发工具。是特有的概念,但容器生态系统必须采用这个概念。 showImg(https://segmentfault.com/img/remote/1460000007157260?w=640&h=480); 开源项目 CRI-O ,其前身为 OCID ,官方简介是 OCI-based implementa...

阅读 1041·2021-11-15 18:06
阅读 2401·2021-10-08 10:04
阅读 2700·2019-08-28 18:03
阅读 944·2019-08-26 13:42
阅读 1967·2019-08-26 11:31
阅读 2466·2019-08-23 17:13
阅读 970·2019-08-23 16:45
阅读 2124·2019-08-23 14:11






