
摘要:它实现了中的横向自动扩容。目前只支持针对使用度进行动态扩容。这个就是真正控制扩容的,其结构如下其中的是一个的引用,定义了自动扩容的配置允许的最大实例数,最小实例数,以及使用配额。这也是为了避免出现频繁的扩容缩容。
最新一版的kubernetes release中我们看到了一个令人欣喜的特性:Autoscaling。它实现了replicationcontroller中pod的横向自动扩容。以下是摘自官方文档的相关内容:
自动扩容将通过一个新的resource(就像之前的pod,service等等)实现。目前只支持针对cpu使用度进行动态扩容。未来的版本中,将会实现基于另一个resource:metrics(这是说未来监控数据将会有一个更统一的展示?)
主要结构1.Scale subresource
Scale subresource是一个虚拟的resource,用来记录扩容进度。其主要结构如下:
// represents a scaling request for a resource.
type Scale struct {
unversioned.TypeMeta
api.ObjectMeta
// defines the behavior of the scale.
Spec ScaleSpec
// current status of the scale.
Status ScaleStatus
}
// describes the attributes of a scale subresource
type ScaleSpec struct {
// desired number of instances for the scaled object.
Replicas int `json:"replicas,omitempty"`
}
// represents the current status of a scale subresource.
type ScaleStatus struct {
// actual number of observed instances of the scaled object.
Replicas int `json:"replicas"`
// label query over pods that should match the replicas count.
Selector map[string]string `json:"selector,omitempty"`
}
其中ScaleSpec.Replicas表示我们预定的集群实例数目标。ScaleStatus.Replicas表示当前实例数,ScaleStatus.Selector是一个选择器,选择对应的pods。
2.HorizontalPodAutoscaler
这个就是真正控制扩容的resource,其结构如下:
// configuration of a horizontal pod autoscaler.
type HorizontalPodAutoscaler struct {
unversioned.TypeMeta
api.ObjectMeta
// behavior of autoscaler.
Spec HorizontalPodAutoscalerSpec
// current information about the autoscaler.
Status HorizontalPodAutoscalerStatus
}
// specification of a horizontal pod autoscaler.
type HorizontalPodAutoscalerSpec struct {
// reference to Scale subresource; horizontal pod autoscaler will learn the current resource
// consumption from its status,and will set the desired number of pods by modifying its spec.
ScaleRef SubresourceReference
// lower limit for the number of pods that can be set by the autoscaler, default 1.
MinReplicas *int
// upper limit for the number of pods that can be set by the autoscaler.
// It cannot be smaller than MinReplicas.
MaxReplicas int
// target average CPU utilization (represented as a percentage of requested CPU) over all the pods;
// if not specified it defaults to the target CPU utilization at 80% of the requested resources.
CPUUtilization *CPUTargetUtilization
}
type CPUTargetUtilization struct {
// fraction of the requested CPU that should be utilized/used,
// e.g. 70 means that 70% of the requested CPU should be in use.
TargetPercentage int
}
// current status of a horizontal pod autoscaler
type HorizontalPodAutoscalerStatus struct {
// most recent generation observed by this autoscaler.
ObservedGeneration *int64
// last time the HorizontalPodAutoscaler scaled the number of pods;
// used by the autoscaler to control how often the number of pods is changed.
LastScaleTime *unversioned.Time
// current number of replicas of pods managed by this autoscaler.
CurrentReplicas int
// desired number of replicas of pods managed by this autoscaler.
DesiredReplicas int
// current average CPU utilization over all pods, represented as a percentage of requested CPU,
// e.g. 70 means that an average pod is using now 70% of its requested CPU.
CurrentCPUUtilizationPercentage *int
}
其中的ScaleRef是一个Scale subresource的引用,MinReplicas, MaxReplicas and CPUUtilization定义了自动扩容的配置(允许的最大实例数,最小实例数,以及cpu使用配额)。
3.HorizontalPodAutoscalerList
用于记录一个namespace下的所有HorizontalPodAutoscaler。本质上是一个结构数组。
官方文档给出的并不是算法, 而是实现步骤,整个自动扩容的流程是:
1.通过podselector找到要扩容的集群
2.收集集群最近的cpu使用情况(CPU utilization)
3.对比在扩容条件里记录的cpu限额(CPUUtilization)
4.调整实例数(必须要满足不超过最大/最小实例数)
5.每隔30s做一次自动扩容的判断(这个日后应该会成为一个扩容条件的参数)
CPU utilization的计算方法是用cpu usage(最近一分钟的平均值,通过heapster可以直接获取到)除以cpu request(这里cpu request就是我们在创建容器时制定的cpu使用核心数)得到一个平均值,这个平均值可以理解为:平均每个CPU核心的使用占比。未来k8s会开放一个api直接获取heapster收集到的监控数据。
真正的算法是:
A.
TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target)
ceil()表示取大于或等于某数的最近一个整数
举个栗子:
我们有一个集群实例数是3 pods。cpu限额,即Target是每个pod分配1.1核,当cpu的使用度CurrentPodsCPUUtilization为1.1,1.4,1.3时,要扩容成多少个呢?
ceil((1.1+1.4+1.3)/1.1)= 4
所以扩容成四个实例。
B.
由于启动实例时cpu的使用度会陡增,所以自动扩容会等待一段时间以收集准确的运行时监控数据。每次扩容/缩容后冷却三分钟才能再度进行扩容,而缩容则要等5分钟后。这是因为自动扩容使用保守的方法,尽可能满足pods业务的正常使用,所以扩容的优先级要大于缩容。
C.
当满足:
avg(CurrentPodsConsumption) / Target >1.1 或 <0.9
时才会触发进行扩容/缩容。这也是为了避免出现频繁的扩容缩容。
为了方便使用,建议采用相对(relative)的度量标准(如 90%的cpu资源)而不是绝对的标准(如0.6个cpu核心)来描述扩容条件。否则,当用户修改pods的请求资源时还需要去修改这些绝对值。比如:我们创建一个集群时,podtemplate中的resource里填入了cpu为1,即最多分配一个cpu核心给该pod,如果在扩容条件中采用绝对标准,我们必须填一个小于1的数,否则这个条件根本不会被触发。而当我们要修改分配的资源为0.8个核心时,又必须要修改扩容条件以确保其小于0.8。这就很麻烦了。
kubectl中的支持以及待支持为了方便使用,在kubectl的cmd命令中加入了 creating/updating/deleting/listing 命令用来操作HorizontalPodAutoscaler
未来可能会加入像kubectl autoscale这样的命令,对一个已经在跑的集群实时进行动态扩容。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/32423.html
摘要:月日,首期沙龙海量运维实践大曝光在腾讯大厦圆满举行。织云高效的实践是,它是以运维标准化为基石,以为核心的自动化运维平台。 作者丨周小军,腾讯SNG资深运维工程师,负责社交产品分布式存储的运维及团队管理工作。对互联网网站架构、数据中心、云计算及自动化运维等领域有深入研究和理解。 12月16日,首期沙龙海量运维实践大曝光在腾讯大厦圆满举行。沙龙出品人腾讯运维技术总监、复旦大学客座讲师、De...
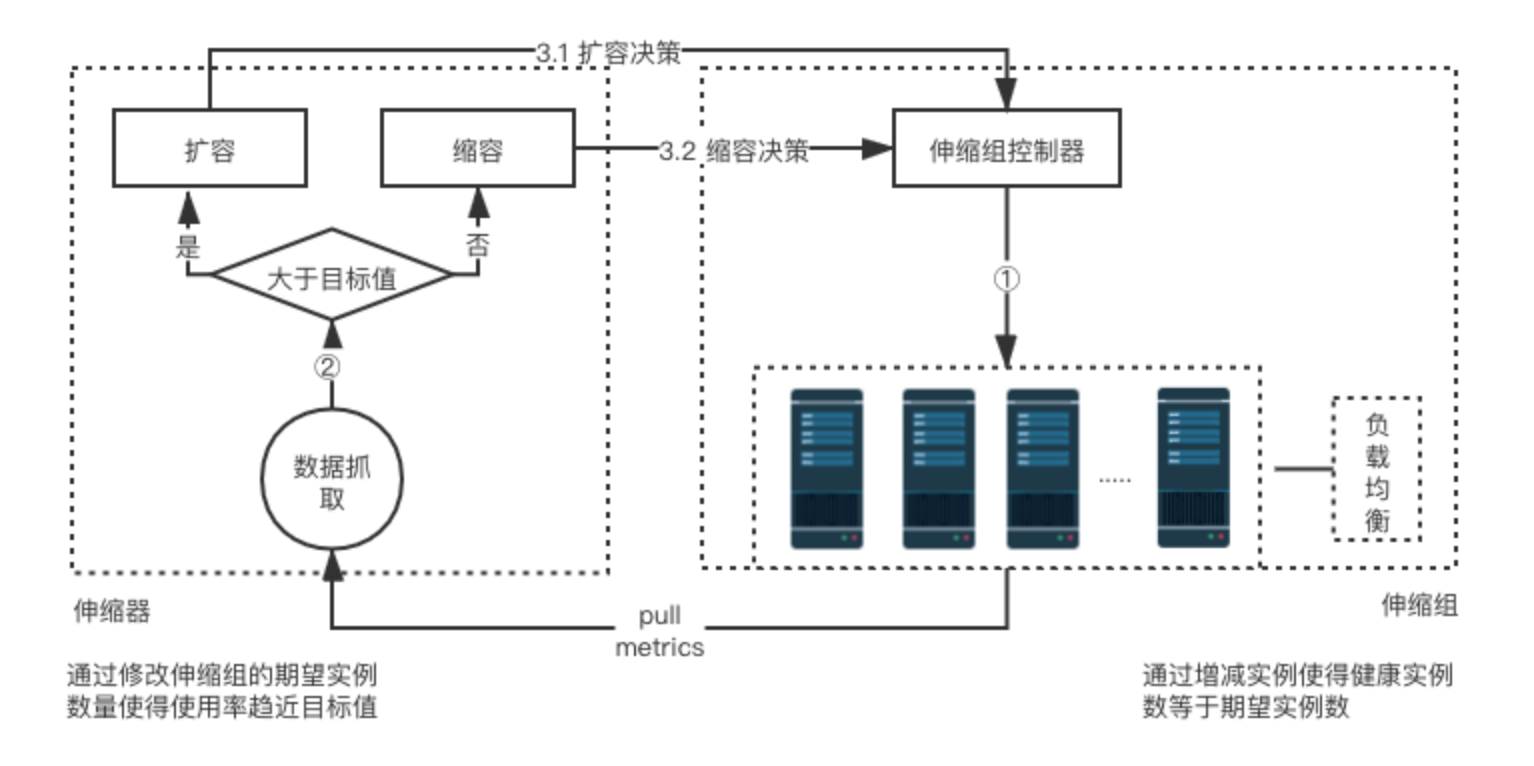
摘要:弹性伸缩是指在业务需求增长时自动增加计算资源虚拟机以保证计算能力,在业务需求下降时自动减少计算资源以节省成本同时可结合负载均衡及健康检查机制,满足请求量波动和业务量稳定的场景。弹性伸缩(Auto Scaling)是指在业务需求增长时自动增加计算资源(虚拟机)以保证计算能力,在业务需求下降时自动减少计算资源以节省成本;同时可结合负载均衡及健康检查机制,满足请求量波动和业务量稳定的场景。用户可通...
摘要:全面支持后端服务的高可用调整优化后端服务组件个中等级别以上的修复云帮社区版迎来了年月升级版本,我们优化了云帮的安装部署流程,全面支持后端服务的高可用,改进了相关提示信息文案,完善了平台日志模块,升级了部分核心组件版本。 全面支持后端服务的高可用、调整优化后端服务组件、4个中等级别以上的bug修复、云帮社区版迎来了2017年5月升级版本,我们优化了云帮的安装部署流程,全面支持后端服务的高...
摘要:本文中,我们将描述系统的架构开发演进过程,以及背后的驱动原因。应用管理层提供基本的部署和路由,包括自愈能力弹性扩容服务发现负载均衡和流量路由。 带你了解Kubernetes架构的设计意图、Kubernetes系统的架构开发演进过程,以及背后的驱动原因。 showImg(https://segmentfault.com/img/remote/1460000016446636?w=1280...

阅读 1774·2021-09-24 10:38
阅读 1592·2021-09-22 15:15
阅读 3149·2021-09-09 09:33
阅读 970·2019-08-30 11:08
阅读 717·2019-08-30 10:52
阅读 1344·2019-08-30 10:52
阅读 2423·2019-08-28 18:01
阅读 619·2019-08-28 17:55





