
摘要:分布式和集群区别分布式分布式是指将一个业务拆分不同的子业务,分布在不同的机器上执行。什么是云计算平台一个云计算平台,就是通过一套软件系统把分布式部署的资源集中调度使用。按业务的垂直拆库和按用户水平拆表是分布式数据库中通用的解决方案。
分布式是指将一个业务拆分不同的子业务,分布在不同的机器上执行,集群是指多台服务器集中在一起,实现同一业务,可以视为一台计算机,一个云计算平台,就是通过一套软件系统把分布式部署的资源集中调度使用。要应对大并发,要实现高可用,既需要分布式,也离不开集群。
分布式和集群区别? 分布式分布式:是指将一个业务拆分不同的子业务,分布在不同的机器上执行。
集群集群:是指多台服务器集中在一起,实现同一业务,可以视为一台计算机。
多台服务器组成的一组计算机,作为一个整体存在,向用户提供一组网络资源,这些单个的服务器就是集群的节点。
两个特点可扩展性:集群中的服务节点,可以动态的添加机器,从而增加集群的处理能力。
高可用性:如果集群某个节点发生故障,这台节点上面运行的服务,可以被其他服务节点接管,从而增强集群的高可用性。
集群分类常用的集群分类
1.高可用集群(High Availability Cluster)
高可用集群,普通两节点双机热备,多节点HA集群。
2.负载均衡集群(Load Balance Cluster)
常用的有 Nginx 把请求分发给后端的不同web服务器,还有就是数据库集群,负载均衡就是,为了保证服务器的高可用,高并发。
3.科学计算集群(High Performance Computing Cluster)
简称HPC集群。这类集群致力于提供单个计算机所不能提供的强大的计算能力。
两大能力负载均衡:负载均衡能把任务比较均衡地分布到集群环境下的计算和网络资源。
集群容错:当我们的系统中用到集群环境,因为各种原因在集群调用失败时,集群容错起到关键性的作用。
例如 Dubbo 的集群容错:
Failover Cluster
失败自动切换,当出现失败,重试其它服务器,通常用于读操作,但重试会带来更长延迟。
Failfast Cluster
快速失败,只发起一次调用,失败立即报错,通常用于非幂等性的写操作,比如新增记录。
Failback Cluster
失败自动恢复,后台记录失败请求,定时重发,通常用于消息通知操作。
Forking Cluster
并行调用多个服务器,只要一个成功即返回,通常用于实时性要求较高的读操作,但需要浪费更多服务资源。
简单总结分布式,从狭义上理解,也与集群差不多,但是它的组织比较松散,不像集群,有一定组织性,一台服务器宕了,其他的服务器可以顶上来。
分布式的每一个节点,都完成不同的业务,一个节点宕了,这个业务就不可访问了。
1. 分布式是指将一个业务拆分不同的子业务,分布在不同的机器上执行。
2. 集群是指多台服务器集中在一起,实现同一业务,可以视为一台计算机。
分布式的每一个节点,都可以用来做集群。而集群不一定就是分布式了。
什么是云计算平台?一个云计算平台,就是通过一套软件系统把分布式部署的资源集中调度使用。要应对大并发,要实现高可用,既需要分布式,也离不开集群。
比如负载均衡,如果只是一台服务器,这台宕机了就完蛋了。
分布式的难点,就是很多机器做存在依赖关系的不同活儿,这些活儿需要的资源、时间区别可能很大,某些机器还可能罢工,要怎么样才能协调好,做到效率最高,消耗最少,不出错。
分布式的应用场景?平时接触到的分布式系统有很多种,比如分布式文件系统,分布式数据库,分布式WebService,分布式计算等等,面向的情景不同,但分布式的思路是否是一样的呢?
1.简单的例子假设我们有一台服务器,它可以承担1百万/秒的请求,这个请求可以的是通过http访问网页,通过tcp下载文件,jdbc执行sql,RPC调用接口…,现在我们有一条数据的请求是2百万/秒,很显然服务器hold不住了,会各种拒绝访问,甚至崩溃,宕机,怎么办呢。
一台机器解决不了的问题,那就两台。所以我们加一台机器,每台承担1百万。如果请求继续增加呢,两台解决不了的问题,那就三台呗。
这种方式我们称之为水平扩展。如何实现请求的平均分配便是负载均衡了。
另一个栗子,我们现在有两个数据请求,数据1 90万,数据2 80万,上面那台机器也hold不住,我们加一台机器来负载均衡一下,每台机器处理45万数据1和40万数据2,但是平分太麻烦,不如一台处理数据1,一台处理数据2,同样能解决问题,这种方式我们称之为垂直拆分。
水平扩展和垂直拆分是分布式架构的两种思路,但并不是一个二选一的问题,更多的是兼并合用。下面介绍一个实际的场景。这也是许多互联网的公司架构思路。
2.实际的例子我此时所在的公司的计算机系统很庞大,自然是一个整的分布式系统,为了方便组织管理,公司将整个技术部按业务和平台拆分为部门,订单的,会员的,商家的等等,每个部门有自己的web服务器集群,数据库服务器集群,通过同一个网站访问的链接可能来自于不同的服务器和数据库,对网站及底层对数据库的访问被分配到了不同的服务器集群,这个便是典型的按业务做的垂直拆分,每个部门的服务器在hold不住时,会有弹性的扩展,这便是水平扩展。
在数据库层,有些表非常大,数据量在亿级,如果只是纯粹的水平的扩展并不一定最好,如果对表进行拆分,比如可以按用户id进行水平拆表,通过对id取模的方式,将用户划分到多张表中,同时这些表也可以处在不同的服务器。按业务的垂直拆库和按用户水平拆表是分布式数据库中通用的解决方案。
比如 Mycat 开源分布式数据库中间件 http://www.mycat.io/
3.分布式一致性分布式系统中,解决了负载均衡的问题后,另外一个问题就是数据的一致性了,这个就需要通过同步来保障。根据不同的场景和需求,同步的方式也是有选择的。
在分布式文件系统中,比如商品页面的图片,如果进行了修改,同步要求并不高,就算有数秒甚至数分钟的延迟都是可以接受的,因为一般不会产生损失性的影响,因此可以简单的通过文件修改的时间戳,隔一定时间扫描同步一次,可以牺牲一致性来提高效率。
但银行中的分布式数据库就不一样了,一丁点不同步就是无法接受的,甚至可以通过加锁等牺牲性能的方式来保障完全的一致。
在一致性算法中paxos算法是公认的最好的算法,Chubby、ZooKeeper 中Paxos是它保证一致性的核心。这个算法比较难懂,我目前也没弄懂,这里就不深入了。
Contact作者:鹏磊
出处:http://www.ymq.io/2018/01/23/Distributed-cluster/
Email:admin@souyunku.com
版权归作者所有,转载请注明出处
Wechat:关注公众号,搜云库,专注于开发技术的研究与知识分享
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/25219.html
摘要:云存储主要技术路线有哪些各有哪些优缺点分享一存储虚拟化存储虚拟化更多是对传统块的虚拟化。也是云存储的主流当家花旦。哪些应用场景适合云存储?存储虚拟化、分布式存储、对象存储这几种技术主要解决什么问题?技术产品选型如何考虑? 企业哪些应用场景适合借助云存储来实现? 传统 IT 环境中使用传统存储的困境有那些?那些应用场景是传统存储不能满足而必须借助云存储来实现的? 分享一: ...
摘要:云存储主要技术路线有哪些各有哪些优缺点分享一存储虚拟化存储虚拟化更多是对传统块的虚拟化。也是云存储的主流当家花旦。 哪些应用场景适合云存储?存储虚拟化、分布式存储、对象存储这几种技术主要解决什么问题?技术产品选型如何考虑?企业哪些应用场景适合借助云存储来实现?传统 IT 环境中使用传统存储的困境有那些?那些应...
摘要:大数据时代第三次信息化浪潮年前后,以云计算大数据物联网的首发为标志迎来第三次信息化浪潮。大数据的发展历程大数据的概念和影响大数据的特性特性指。处理大规模图结构数据。物联网应用大数据云计算物联网的关系三者相辅相成,既有联系又有区别。 ...
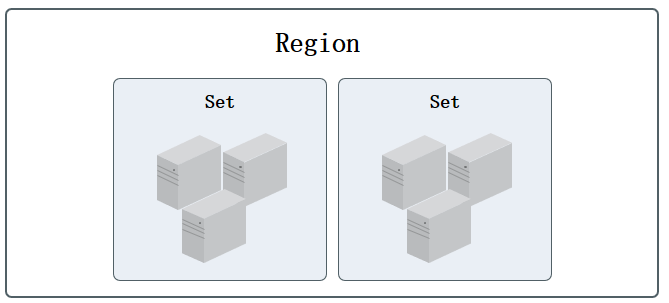
摘要:集群默认对所有租户开放权限,平台支持对存储集群进行权限控制,用于将部分物理存储资源独享给一个或部分租户使用,适用于专属私有云场景。支持租户将有权限的存储卷信息作为虚拟机的系统盘,使虚拟机直接运行直商业存储中,提升性能。4.1.1 地域地域 ( Region ) 指 UCloudStack 云平台物理数据中心的地理区域,如上海、北京、杭州等。不同地域间完全物理隔离,云平台资源创建后不能更换地域...

阅读 1891·2021-09-22 15:23
阅读 3374·2021-09-04 16:45
阅读 2083·2021-07-29 14:49
阅读 2819·2019-08-30 15:44
阅读 1596·2019-08-29 16:36
阅读 1114·2019-08-29 11:03
阅读 1584·2019-08-26 13:53
阅读 558·2019-08-26 11:57





