
DeepSeek V3凭借多头潜注意力(MLA)与优化的混合专家网络(MoE)架构,奠定了高效训练的基础,仅以557.6万元成本实现媲美OpenAI O1的性能;而R1则基于V3进一步突破,通过无监督强化学习与知识蒸馏技术,在推理能力上对标顶尖模型,同时开源多尺寸版本,推动更广泛的应用。
DeepSeek三种模式对比
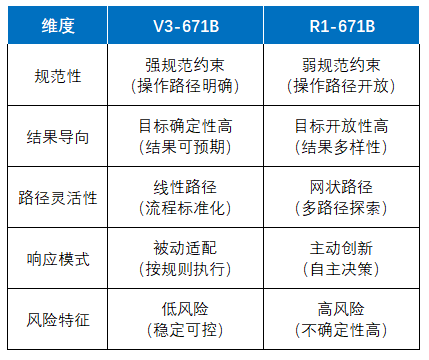
基础模型(V3):通用模型(2024.12),高效便捷,适用于绝大多数任务,“规范性 ”任务;
深度思考(R1):推理模型,复杂推理和深度分析任务,如数理逻辑推理和编程代码,“规范性”任务;
联网搜索:RAG(检索增强生成),知识库更新至2024年7月;
V3与R1的差异
我们基于UCloud的满血版DeepSeek V3、R1做横向对比,来了解两种模型在使用及提示语上的差异。
基础模型(V3),需要给到从“过程-结果”的清晰指令,例如角色设定、思维链提示、提示词结构化等。
深度思考(R1),较为开放,只要目标清晰,明确是目的及约束,对于推理过程的设定可以模糊处理。
开放性文本生成任务示例

规范性文本生成任务

满血版申请入口
前往UCloud官网,选择ModelVerse产品,申请权限即可开通使用。
直达链接:https://www.ucloud.cn/site/product/modelverse.html
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/131187.html

我们身处数字化浪潮中,知识管理和利用的重要性与日俱增。拥有一个专属的本地知识库,能极大提升工作效率,满足个性化需求。但对于技术小白来说,搭建这样的知识库不仅存在技术门槛,同时也意味着需要一定的成本投入。本期 DeepSeek 入门教程,优刻得将为您提供一个0成本基于DeepSeek(满血版)轻松搭建本地知识库的方式。获取优刻得模型服务平台密钥Key登录 UCloud 控制台https://cons...
2月10日,清华大学KVCache.AI团队联合趋境科技发布的KTransformers开源项目公布更新:一块24G显存的4090D就可以在本地运行DeepSeek-R1、V3的671B满血版。预处理速度最高达到286 tokens/s,推理生成速度最高能达到14 tokens/s。KTransformers通过优化本地机器上的LLM部署,帮助解决资源限制问题。该框架采用了异构计算、先进量化技术、...

DeepSeek 的持续火热,吸引了大量个人开发者和企业用户,他们期望借助 DeepSeek 大模型的强大能力,融合私有知识库,训练出契合自身需求的专属大模型,因此纷纷选择通过云端或本地部署的方式来独立部署 DeepSeek。今天,优刻得就为大家带来第一期超实用干货:仅需 10 分钟,利用 UCloud 云主机 UHost+DeepSeek + Open-WebUI 快速搭建起属于自己的私有化知识...
DeepSeek-R1 Distill系列基于DeepSeek-R1的推理能力,通过蒸馏技术将推理能力迁移到较小的模型上,在保持高效性能的同时,成功降低了计算成本,实现了小身材、大智慧的完美平衡!该镜像使用vLLM部署提供支持,适用于高性能大语言模型的推理和微调任务,第一步:登录「优云智算」算力共享平台并进入「镜像社区」地址:https://www.compshare.cn/?ytag=seo 第...

(遵循数据全面性、客观性、可验证性及结构化原则)一、排名依据与评估维度本文从以下维度评估GPU云服务器一体机解决方案:性能表现:包括GPU型号覆盖、算力效率、分布式训练支持等。可靠性:服务稳定性、容灾能力、SLA承诺。生态整合:与AI框架的兼容性、多模态大模型支持、开发者工具链。性价比:单位算力成本、弹性计费模式、长期合作折扣。行业适配:企业级服务案例、垂直领域解决方案。二、2025年GPU云服务...

阅读 11903·2025-03-21 11:44
阅读 571·2025-02-19 18:27
阅读 663·2025-02-19 18:21
阅读 627·2025-02-19 13:50
阅读 1764·2025-02-13 22:35
阅读 1301·2025-02-08 10:20
阅读 5976·2025-01-02 11:25
阅读 1315·2024-12-10 11:51


